本篇内容介绍了“Linux文件系统中的NiLFS(2)和exofs怎么使用”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
使用日志和对象发展 Linux 文件系统
Linux® 在文件系统领域不断创新。它支持任何操作系统上的众多不同文件系统。它还提供尖端文件系统技术。Linux 最近又引入两种新的文件系统,它们是 NiLFS(2) 日志结构文件系统和 exofs 基于对象的存储系统。探索这两种文件系统背后的动机和它们的优点。
在 IBM Bluemix 云平台上开发并部署您的下一个应用。
现在就开始免费试用
一种新的 Linux 文件系统的公布总是令人既兴奋又恐惧。兴奋是因为文件系统意味着新的发展空间。恐惧是因为文件系统在早期还是试验性的,尚未迎来黄金时期。但是有时候,新文件系统的公布也意味着对 Linux 未来的投资,而最近 2.6.30-rc1 的公布确实标示着令人感兴趣的前景。在过去几个季度,Linux 主要公布了三种文件系统。2008 年底引入了 B-Tree File System(Btrf),最近又引入了两种独特的文件系统:NiLFS(2) 和 exofs。
我们首先了解这些非传统文件系统,然后探索 NiLFS(2) 和 exofs 的细节。
日志结构文件系统是用于由 NAND 闪存组成的固态硬盘(solid-state disks,SSD)的理想格式。闪存的基本问题是写擦周期数量有限。日志可以写到整个设备上,尽量写满设备,从而最大程度地减少擦的周期。由于这个原因,日志结构文件系统在 SSD 上(连续写)表现非常好,并且提供更好的损耗均衡。
日志结构文件系统在现代计算系统中有丰富的历史。第一个日志结构文件系统由 John Ousterhout 和 Fred Douglis 在 1988 年提出,随后由 Sprite 操作系统在 1992 年实现。顾名思义,日志结构文件系统将文件系统视为一个循环日志,将新的数据和文件系统元数据写到日志的头部,并且从尾部回收空闲空间(如图 1 所示)。这意味着数据可能在日志中出现两次或更多次,但是由于日志是按时间先后顺序发展的,最近的数据被视作活动数据。日志中保留数据的多个副本可以带来一些有趣的优点,后面将详细谈到这些优点。
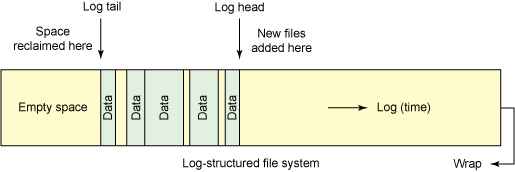
与其说日志结构方法是一个卖点,不如说它是体系结构上的一个细节,不过这种方法确实有一些独特的优点。一个关键的优点在于系统崩溃后的数据恢复,当使用日志结构方法时,这种恢复更简单。
另一个优点是利用底层存储系统挖掘性能。您也许还记得,连续写到硬盘比随机 I/O 要快得多。如果所有的写都是连续的,那么查找的开销随之减少,从而可以获得更快的硬盘 I/O,进而得到更快的文件系统。
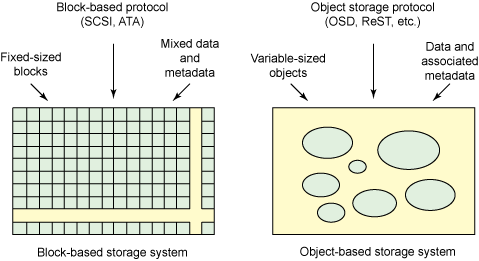
传统存储系统依赖于磁盘驱动器和它们的本地接口持久地存储数据。这些接口依赖于块存储语义,大小固定的数据小块与它们的映射(文件系统元数据)相关联。对象存储系统则采用截然不同的方法:它们不是管理大小固定的数据块,而是管理大小可变的对象以及相关联的元数据(提供关于对象的系统级信息)。
对象存储设备基于 T-10 Object Storage Devices(OSD)标准。该规范详细描述了用于支持对象级管理的对标准 SCSI 命令集的扩展。除了定义对象级访问方法外,该规范还包括安全性和元数据管理。
对象存储系统是解决包含多租户和安全性的可伸缩存储的唯一途径。构建作为一种标准的 OSD(见侧边栏)的方式有很多种。例如可以使用遵从 OSD 的组件(例如 OSD 驱动器和启动器)或更高级的组件(在传统驱动器上构建 OSD 行为的目标系统)。但是,基于块的存储系统与基于对象的存储系统之间的根本区别在于,在基于块的存储系统中,是从块集合创建对象的,块中既包括数据,又包括使用某种协议与块通信的元数据。而在基于对象的存储系统中,是与对象和它们的关联元数据通信的(如图 2 所示)。于是,对象存储设备成为对象的平面名称空间(flat namespace),必要时,在存储系统栈中的更高层建立层次结构。
本文探索基于对象的存储系统上的一种文件系统的实现。
回页首
NiLFS(2) 是日本 Nippon Telegraph and Telephone(NTT)开发的一种日志结构文件系统的第二次迭代。该文件系统的开发非常活跃,最近已进入主流 Linux 内核(另外还有 NetBSD 内核)。第一版的 NILFS(version 1)出现于 2005 年,这个版本没有任何形式的垃圾收集。在 2007 年,第 2 版首次发布,其中包括一个垃圾收集器,并且可以创建和维护多个快照。今年(2009),NiLFS(2) 文件系统进入主流内核,可通过安装它的可装载模块方便地启用它。
NiLFS(2) 一个有趣的方面是,它支持连续快照(continuous snap-shotting)技术。由于 NILFS 是基于日志结构的,新数据被写到日志的头部,而旧数据仍然保留(直到需要对旧数据进行垃圾收集)。由于旧数据仍被保留,因此可以在时间线上回滚,以检查文件系统的不同时期(epoch)。在 NiLFS(2) 中,这些时期被称作检查点,它们是文件系统中不可或缺的一部分。每当发生改变时,NiLFS(2) 都会创建这些检查点,但是也可以强制创建检查点。
NiLFS(2) 是众多包含快照行为的文件系统中的一种。其他包含快照的文件系统有 ZFS、LFS 和 Ext3cow。
可以在快照中查看和更改检查点(恢复点)。可以像其他文件系统一样将快照挂载到 Linux 文件系统空间中,但是目前它们还是只读的。这一点非常有用,因为可以挂载快照,然后恢复之前删除的文件,或者检查之前版本的文件。
除了连续快照外,NiLFS(2) 还具有很多其他的优点。从可用性的角度看,最重要的优点是快速重启。如果当前检查点失效,文件系统只需回滚到上一个有效的检查点,重新获得有效的文件系统。这显然好于 fsck 进程。
这个 NiLFS(2) 演示 是在 2.6.27 Linux 内核中完成的。2.6.30-rc1 内核在 mainline 中包括 NiLFS(2),但是在这里,NILFS 文件系统模块和工具是从源代码安装的。请参阅 参考资料 了解关于如何将 NiLFS(2) 安装到内核中的信息。
虽然连续快照是一个很好的特性,但是也有一定的副作用。前面已经提到,它的优点在于它是日志结构的,采用连续写的方式(减少物理磁盘的查找行为),因此非常快。而缺点在于,它是日志结构的,所以需要垃圾收集,以便清理旧的数据和元数据。一般情况下,这种文件系统非常快,但是一旦需要进行垃圾收集,性能就会慢下来。
我们来看看 NiLFS(2) 的实际应用。这个演示展示如何在循环设备上创建一个 NiLFS(2) 文件系统(测试文件系统的一种简单方法),然后看看 NiLFS(2) 的一些特性。首先安装 NiLFS(2) 内核模块:
$ sudo modprobe nilfs2 $
接下来,创建一个文件,该文件将包含文件系统(主机操作系统上的一个区域,可通过循环设备将它挂载为操作系统本身的文件系统),然后使用 mkfs 在其中构建 NiLFS(2) 文件系统(如图 1 所示)。
$ dd if=/dev/zero of=/tmp/disk.img bs=384M count=1 1+0 records in 1+0 records out 402653184 bytes (403 MB) copied, 60.7253 s, 6.6 MB/s $ mkfs.nilfs2 /tmp/disk.img mkfs.nilfs2 ver 2.0 Start writing file system initial data to the device Blocksize:4096 Device:/tmp/disk.img Device Size:402653184 File system initialization succeeded !! $
现在,您有了自己的以 NiLFS(2) 文件系统格式初始化的磁盘镜像。接下来,使用循环设备将该文件系统挂载到一个挂载点上(如清单 2 所示)。注意,当挂载文件系统时,会启动一个用户空间程序 nilfs_cleanerd,以提供垃圾收集服务。
$ sudo losetup /dev/loop0 /tmp/disk.img $ sudo mkdir /mnt/nilfs $ sudo mount -t nilfs2 /dev/loop0 /mnt/nilfs/ mount.nilfs2: WARNING! - The NILFS on-disk format may change at any time. mount.nilfs2: WARNING! - Do not place critical data on a NILFS filesystem. $ ls /mnt/nilfs $
现在,在该文件系统中添加一些文件,然后使用 lscp 命令列出当前可用的检查点(如清单 3 所示)。使用 mkcp 命令定义一个快照,然后再次查看检查点。第二次执行 lscp 命令时可以看到新创建的快照(所有检查点和快照都有一个 CNO,或检查点号)。
$ cd /mnt/nilfs $ sudo touch file1.txt file2.txt $ lscp CNO DATE TIME MODE FLG NBLKINC ICNT 1 2009-08-21 22:29:31 cp - 11 3 2 2009-08-21 22:36:44 cp - 11 5 $ sudo mkcp -s $ lscp CNO DATE TIME MODE FLG NBLKINC ICNT 1 2009-08-21 22:29:31 cp - 11 3 2 2009-08-21 22:36:44 ss - 11 5 3 2009-08-21 22:39:47 cp i 7 5 $
现在有了一个快照,接下来同样使用 touch 命令再将一些文件添加到当前文件系统中(如清单 4 所示)。
$ sudo touch file3.txt file4.txt $ ls file1.txt file2.txt file3.txt file4.txt $
现在,挂载快照作为一个只读文件系统。这和之前的挂载类似,但是需要指定挂载的快照。为此可以使用 cp 选项。从之前的 lscp 命令中可以看出,快照是 CNO=2。在 mount 命令中使用这个 CNO 挂载只读文件系统。挂载后,首先使用 ls 命令列出挂载的读/写文件系统,然后查看所有的文件。在只读快照中,只能看到两个文件,这两个文件是创建快照时存在的两个文件(如清单 5 所示)。
$ sudo mkdir /mnt/nilfs-ss2 $ sudo mount.nilfs2 -r /dev/loop0 /mnt/nilfs-ss2/ -o cp=2 $ ls /mnt/nilfs file1.txt file2.txt file3.txt file4.txt $ ls /mnt/nilfs-ss2/ file1.txt file2.txt $
注意,一旦将检查点转换为快照,这些快照将持久存在。当需要清理出空间时,检查点会被从文件系统中回收,而快照可以持久存在。
该演示展示了用于 NiLFS(2) 的两个命令行实用程序:lscp(列出检查点和快照)和 mkcp(创建检查点或快照)。有一个名为 chcp 的实用程序,用于将检查点转换为快照,或者将快照转换为检查点;还有一个 rmcp 实用程序,用于使检查点或快照无效。
鉴于这种文件系统是临时性的,NTT 已经为将来考虑了一些非常有创新性的工具 — 例如,tls(临时 ls)、tdiff(临时 diff)和 tgrep(临时 grep)。下一步引入基于时间的功能似乎是合乎情理的。
回页首
Extended Object File System(exofs)是构建在对象存储系统上的一种传统的 Linux 文件系统。exofs 最初由 IBM 的 Avnishay Traeger 开发,当时被称作 OSD 文件系统,或称作 osdfs。然后,Panasas(一家构建对象存储系统的公司)接管该项目,并将它重新命名为 exofs(因为它的祖先来自 ext2 文件系统)。
从概念上讲,对象存储系统可以视作对象的平面名称空间和它们的关联元数据。而在基于块的传统存储系统,元数据要占用一些块,以提供语义黏合剂。图 3 显示 exofs 的架构图。Virtual File System Switch(VFS)为 exofs 提供一条途径,在其中,exofs 通过一个本地 OSD 启动器与对象存储系统通信。OSD 启动器实现 OSD T-10 标准 SCSI 命令集。
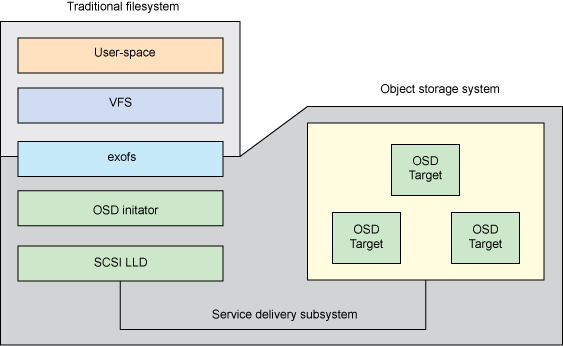
exofs 背后的思想是在 OSD 后备存储上提供一个传统文件系统。这样一来,就更容易迁移到对象级存储,因为提供的文件系统本身是传统的文件系统。
OSD 中的每个对象由平面名称空间中一个 64 位的标识符表示。为了将标准 POSIX 接口叠加到对象存储系统上,需要一个映射。exofs 提供一个简单的映射,这种映射还是可伸缩、可扩展的。
文件系统中的文件由 inode 唯一地表示。exofs 将 inode 映射到对象系统中的对象标识符(OID)。在对象系统中,使用对象表示文件系统的所有元素。文件被直接映射到对象,目录也是文件,只不过是引用目录中所含文件的文件(采用文件名和 inode-OID 对的形式)。图 4 简明地阐释了这一点。另外还有一些其他的对象,用于支持 inode 位图(用于 inode 分配)等。
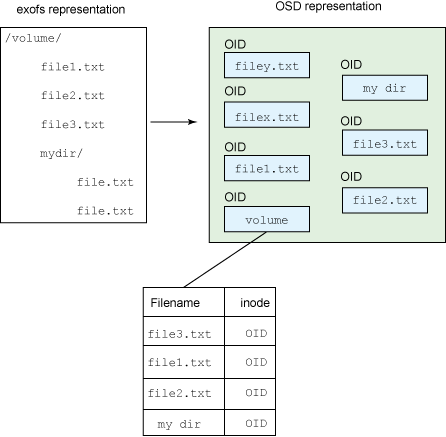
用于表示对象空间中的对象的 OID 长度为 64 位,因此支持非常多的对象。
对象存储是一个有趣的思想,可大幅提高系统的可伸缩性。它将文件系统的一些部分从主机转移到存储子系统中。为此需付出一定的代价,但是通过将文件系统的一些部分分布到多个端点,可以分散工作负载,使基于对象的方法更易于伸缩到更大的存储系统。主机操作系统不再需要考虑块到文件的映射,存储设备本身会提供这种映射,因此主机可以在文件级进行操作。
对象存储系统还提供查询可用元数据的能力。这可以带来更多的好处,因为搜索能力可以分布到端点对象系统。
最近,对象存储在云存储领域回归。云存储提供商(将存储作为服务出售)以对象的形式提供他们的存储,而不是以传统的块 API 的形式提供存储。这些提供商实现用于对象传输、管理和元数据管理的 API。
回页首
“Linux文件系统中的NiLFS(2)和exofs怎么使用”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





