这篇文章主要讲解了“Hadoop生态的组件HBase怎么搭建”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Hadoop生态的组件HBase怎么搭建”吧!
分布式表格系统对外提供表格模型,每个表格由很多行组成,通过主键唯一标识,每一行包含很多列。整个表格在系统中全局有序。而Google的BigTable是分布式表格系统的始祖,它采用双层结构。底层用GFS作为持久层存储层。而BigTable的对外的接口不怎么丰富。所以谷歌有开发出Megastore和Spanner.既提供来接口,又能处理事务.
表格中的每一行都有主键(Row Key)作为唯一标识。每一行又包含很多列(Column)。某一行的某一列构成一个单元(Cell),每个单元包含多个版本的数据。整体来看的话,BigTable是一个分布式多维度映射表。
(row:string,column:string,timestamp:int64)->string多个列的话又可以构成一个列族(Column Family),所以列名就由列族(Column Family)+列名(qualifier).列族是访问控制的单元,所以列族的话是预先定义好的,而列的话后面可以添加,数量任意.
存储结构如图(逻辑视图):

存储结构如图(物理视图):

行主键是任意的字符串,但是大小不能超过64KB。按主键排序,而主键是字典序.所以网址接近刚好可以排列在一块.
HBase开源山寨版BigTable. 基于Hadoop的分布式文件系统HDFS之上。然后HDFS和HBase是有什么区别呢?
HDFS 是分布式文件系统,适合保存大文件。官方宣称它并非普通用途文件系统,不提供文件的个别记录的快速查询。 另一方面,HBase基于HDFS且提供大表的记录快速查找(和更新)。这有时可能引起概念混乱。 HBase 内部将数据放到索引好的 "存储文件(StoreFiles)" ,以便高速查询。存储文件位于 HDFS中。 PS:说白了,HBASE就是一个索引集合.
HBase与关系数据库的存储结构对比(HBase是NOSQL--not only sql的一种):在HBase中定位到value值,需要几个坐标:rowkey,列族,列,版本号。。在这里我对比的例子不太恰当。。Hbase还是存储一些半结构化的数据要好一点。
| id | name | password | type |
| 1 | zhangsan | xxxxx | sb |
| 2 | lisi | 324324 | sb2 |
| 3 | zhaowu | 423423 | db |
hbase:
| rowkey(主键) | info(列族) | others(列族) |
| name | password | type | age | |
| rk0000999 | zhangsan,version1 zhangsan3,version2 | xxxxxxxx | sb | 10 |

前提: 已经部署分布式文件系统,例如HDFS.
3.1 机器准备,以及节点的分配
在这里有三台机器,其中一台为HMaster,同时的有三个HRegionServer.所以有一台机器时两种角色.还需要部署HDFS和Zookeeper.我的HDFS也是三个节点,也是有一台机器同时有NameNode和DataNode,SecondaryNameNode,其他两台机器只有datanode.
| IP | Hostname | JVM Process |
| 192.168.237.201 | Spark-0x64-001 | HMaster,HRegionServer,QuorumPeerMain,DataNode NameNode,SecondaryNameNode |
| 192.168.237.202 | Spark-0x64-002 | HRegionServer,QurumPeerMain,DataNode |
| 192.168.237.203 | Spark-0x64-003 | HRegionServer,QurumPeerMain,DataNode |
3.2 安装非HA模式的HDFS
由于之前之前已经安装过HDFS的分布式集群,但是是非HA机制. 这里就不重复啦.
3.3 安装集群的Zookeeper
不重复啦。之前的博客已经写啦.http://my.oschina.net/codeWatching/blog/367309
3.4 配置HBase的文件
a. 修改文件hbase-evn.sh.添加两个地方.
export JAVA_HOME=/spark/app/jdk1.7.0_21/
export HBASE_MANAGES_ZK=false
b. 修改文件hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Spark-0x64-001:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>Spark-0x64-001:6000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Spark-0x64-001,Spark-0x64-002,Spark-0x64-003</value>
</property>
</configuration>c.将hadoop中的core-site.xml和hdfs-site.xml拷贝到hbase的conf目录下
d.编辑regionservers文件
Spark-0x64-001 Spark-0x64-002 Spark-0x64-003
3.5 将配置好的Hbase拷贝到其他机器上。Scp -r 命令.
3.6 配置时间时间服务器。见链接:........
3.7 启动HBase
a.在三台机器上启动zookeeper
b.启动HDFS.已启动
c.启动Hbase(主节点Master)--->sh bin/start-hbase.sh.
d.可选,启动多个HMaster---->hbase-daemon.sh start master3.8 验证Web页面
http://192.168.237.201:60010HBase的技术架构图:一览无余
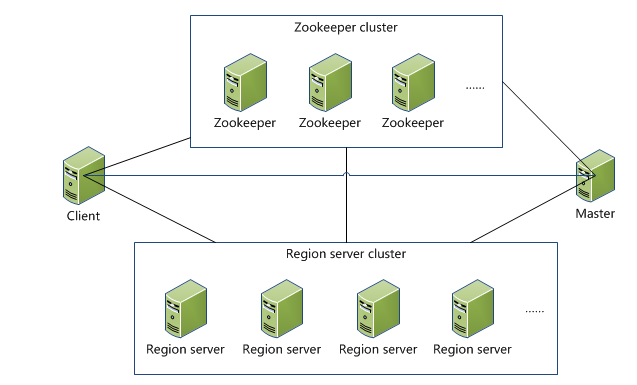
Client
1 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
Zookeeper
1 保证任何时候,集群中只有一个master
2 存贮所有Region的寻址入口。
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 GFS上的垃圾文件回收
5 处理schema更新请求
Region Server
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。HBase的寻找数据的流程

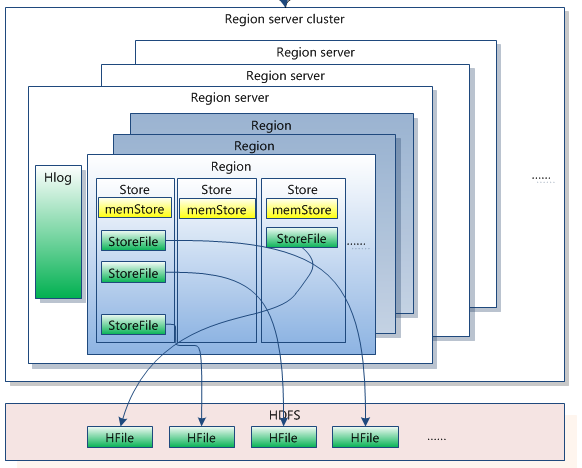
系统如何找到某个row key (或者某个 row key range)所在的region
hbase使用三层类似B+树的结构来保存region位置。
第一层是保存zookeeper(谷歌chubby)里面的文件,它持有root region的位置。
第二层root region是.META.表的第一个region其中保存了.META.z表其它region的位置。通过root region,我们就可以访问.META.表的数据。
.META.是第三层,它是一个特殊的表,保存了hbase中所有数据表的region 位置信息。
PS:root region永远不会被split,保证了最需要三次跳转,就能定位到任意region 。
2.META.表每行保存一个region的位置信息,row key 采用表名+表的最后一样编码而成。
3 为了加快访问,.META.表的全部region都保存在内存中。
假设,.META.表的一行在内存中大约占用1KB。并且每个region限制为128MB。
那么上面的三层结构可以保存的region数目为:
(128MB/1KB) * (128MB/1KB) = = 2(34)个region
4 client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/codeWatching/blog/410919



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



