一、hive在执行sql时会以mapreduce的方式对数据进行接入和处理,其主要包含以下几个阶段:
1.hive首先根据sql语句中的表从hdfs文件中获取数据,对数据文件进行split操作,使其可以一行一行将所需数据读入内存;
2.map函数将内存中的数据按照key值进行映射,形成一行一行的key-value值,比如用户表中的性别字段,内存中map处理后的记录如下: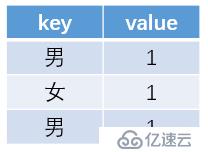
3.在实际应用中会有多台机器参与map处理,map完成后需要将带有相同key的数据分发到同一台集群去进行后续处理,此时的操作称为shuffle;
4.如果sql中包含有join、count、sum,此时还会进行reduce操作,比如count,其完成reduce后数据情况如下: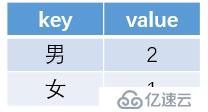
二、在hive底层,同时还会将上面的sql进行编译,其过程主要包含以下六点: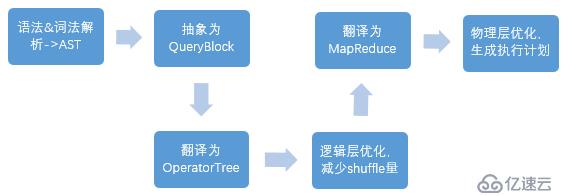
为便于理解,我们拿一个简单的查询语句进行展示,对5月30号的地区维表进行查询:
select * from dim.dim_region where dt = '2019-05-30'1.根据Antlr定义的sql语法规则,将相关sql进行词法、语法解析,转化为抽象语法树AST Tree
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
dim
dim_region
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_ALLCOLREF
TOK_WHERE
=
TOK_TABLE_OR_COL
dt
'2019-05-30'2.遍历AST Tree,抽象出查询的基本组成单元QueryBlock
AST Tree生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化,形成QueryBlock。QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出。简单来讲一个QueryBlock就是一个子查询。QB的生成过程为一个递归过程,先序遍历 AST Tree ,遇到不同的Token 节点(理解为特殊标记),保存到相应的属性中,主要包含以下几个过程:
3.遍历QueryBlock,翻译为执行操作树OperatorTree
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
由于Join/GroupBy/OrderBy均需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce Key/value, Partition Key。
4..Logical Optimizer对OperatorTree进行优化操作
使用ReduceSinkOperator,减少shuffle数据量。大部分逻辑层优化器通过变换 OperatorTree ,合并操作符,达到减少 MapReduce Job ,减少 shuffle 数据量的目的。
5.遍历OperatorTree,并翻译为MapReduce任务
OperatorTree 转化为 Task tree的过程分为下面几个阶段
对输出表生成 MoveTask
从 OperatorTree 的其中一个根节点向下深度优先遍历
ReduceSinkOperator 标示 Map/Reduce 的界限,多个 Job 间的界限
遍历其他根节点,遇过碰到 JoinOperator 合并 MapReduceTask
生成 StatTask 更新元数据
剪断 Map 与 Reduce 间的 Operator 的关系
6.物理层优化器对MapReduce任务进行优化,生成最终的执行计划
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





