这篇文章主要介绍“spark创建RDD的方式有哪些”,在日常操作中,相信很多人在spark创建RDD的方式有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”spark创建RDD的方式有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
##产生的技术环境
避免在多种运算场景,多种集群部署
集群计算数据,典型的思想mr,后来最重要的是hadoop,分布式集群,会把编程简化为位置感知、容错、负载均衡,在集群上操作超大数据,这种模式是数据流的方式;hdfs->计算->hdfs tez dag 基于数据流的dag虽然实现任务调度和故障恢复,但是每次操作读写磁盘,如果同样一次操作,如果第二次操作,完全会计算一次,比如图计算,机器学习,比如交互式查询
##解决问题的方式
解决上述的问题是RDD
检查点或者回滚机制vs共享内存模型
#创建RDD的三种方式
通过已存在的scala集合
通过hdfs、hbase等
通过其他rdd的转换
#Spark RDD中Transformation的Lazy特性
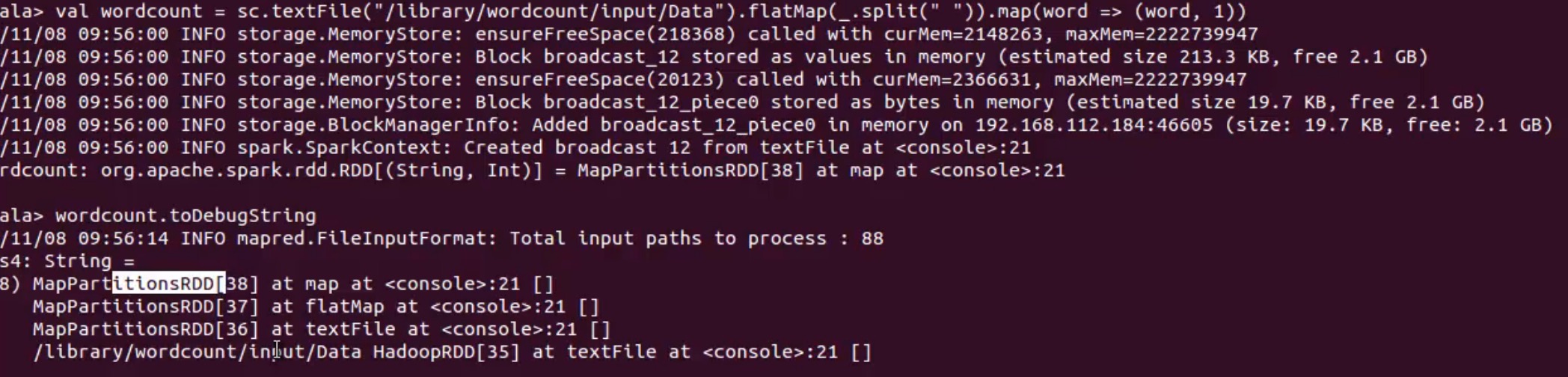
textfile产生hadoopRDD和mappartitionRDD
#Spark RDD中Runtime流程解析
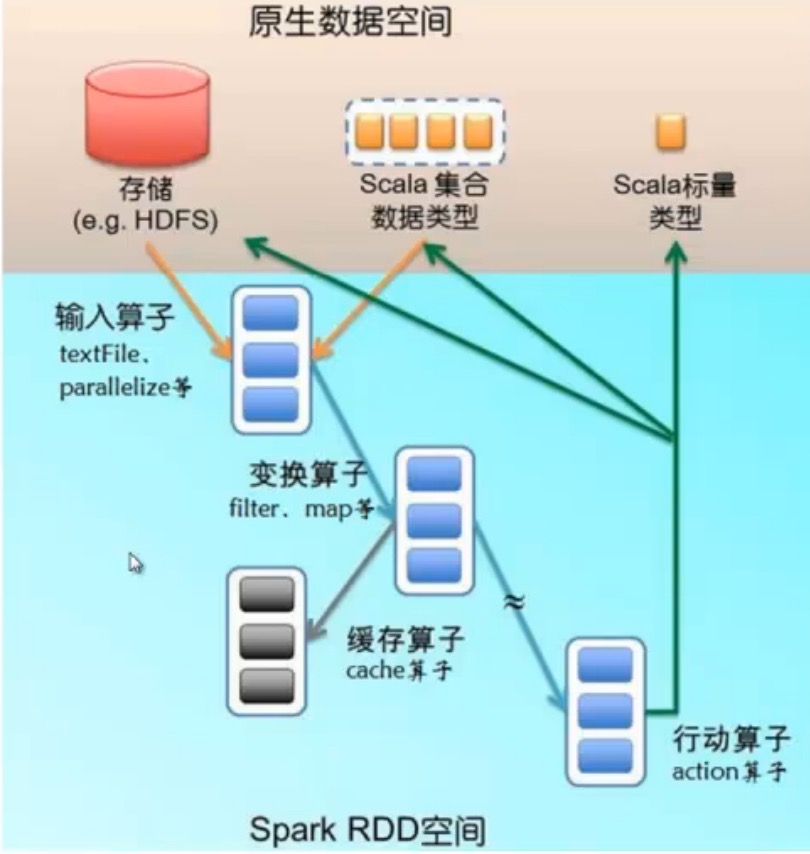
RDD是逻辑结构,数据本身是block manager
#Spark RDD中Transformation的算子详解
map:针对每个分区中的元素进行改变,分区个数不行 v1->v`1,map是根据stage中进行复合操作时执行的
flatmap:将各个分区中的数,进行转化,汇聚成一个分区
mapPartitions:Iter=>iter.filter(_>3)针对某个分区,分区数不变
glom:将每个分区形成一个数组,分区数不变
filter:根据传入的函数的返回值,如果为true,就返回否则忽略,分区数不变
distinct:针对每个分区内重复的元素过滤,分区数不变
cartesian:针对多个RDD的分区进行笛卡尔积
union:针对多个RDD分区进行合并(不进行去重),会改变分区数
mapValues:针对分区中kv结构的RDD中的v进行操作,对k不会有影响,分区数不变
subtract:去除多个分区中交叉的元素
sample:针对RDD采样fraction=0.5,seed=9,返回结果仍是RDD
takeSample:num=1,seed=9,返回结果不是RDD groupBy:根据k,group,相同k拥有v数组 partitionBy:针对RDD分区 cogroup:这对kvRDD,的k进行分组,每个k是v的元组数组 combineByKey:groupbykey,针对分区进行分组,分区数不变 reduceByKey:对每个分区相同k的v进行操作
join:
leftOuterJoin:
rightOuterJoin:
#Spark RDD中cache和persist详解
cache是persist的一种实现,都是lazy操作,unpersist是立即操作
#RDD中Action的算子详解
foreach:
collect:toArray
collectAsMap:kv模式的hashmap,k重复v会覆盖
reduceByKeyLocally:reduce+collectAsMap:kv lookup:寻找指定k的sequence序列,优先找partition,否则暴力扫描
count:计算所有分区中元素的个数
top:
reduce:对每个分区分别进行reduceLeft,在对所有分区结果进行reduceLeft
fold:比reduce默认一个zero
aggregate:
saveAsTextFile:
saveAsObjectFile:c<null,byteWriteable> sequence
#RDD中的缓存和检查点不同使用场景和工作机制彻底解析
##缓存(persist)
缓存会被重用eg:1 2 3 4 [5] 6.1 6.2 6.3
[5]有10000分片,可能丢失
##检查点(checkpoint) 在什么地方缓存,在获取大量数据的时候,上下stage,很长的计算链条之后,超耗时计算,checkpoint
checkpoint:会改变rdd的血缘关系,在action后触发,引入checkpoint,避免缓存丢失,重新计算带来的性能方面的开销,checkpoint,在action触发之后产生一个新的job,使用checkpoint的rdd务必使用checkpoint,这样更快,流计算,图计算使用很多checkpoint
#RDD窄依赖NarrowDependency和宽依赖ShuffleDependency 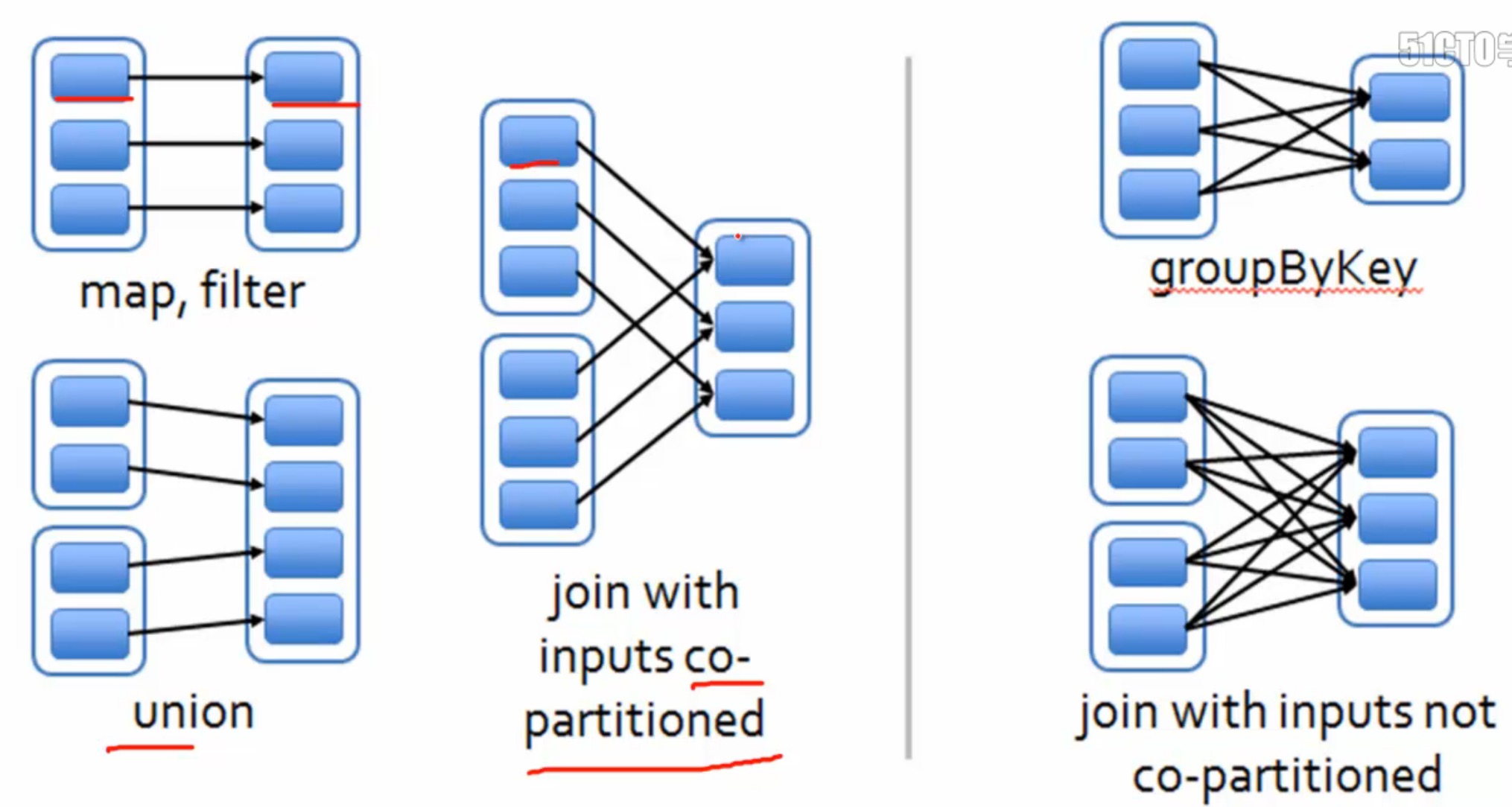
1个窄依赖:1个计算任务,相互独立
源码 Dependency
窄依赖可以优化scheduler optimizations
宽依赖是划分stage的依据,stage是构成dag的大粒度
#两种类型Spark RDD Task解析以及iterator解析
最后一个stage的task是resultTask,前面依赖的stage的task称为shuffleMapTask,都共有一个runTask方法的iterator开始计算
shuffleMapTask->bucket
判断是否有缓存
判断是否有checkpoint
sparkEnv
#RDD的iterator中的缓存处理内幕源码级详解
#Spark RDD的checkpoint处理内幕源码级详解
#Spark RDD容错原理及其四大核心要点解析
#Spark应用程序中核心概念和常用术语详解
一个application可以有若干个作业
#Spark应用程序作业调度流程和底层运行机制内幕概述

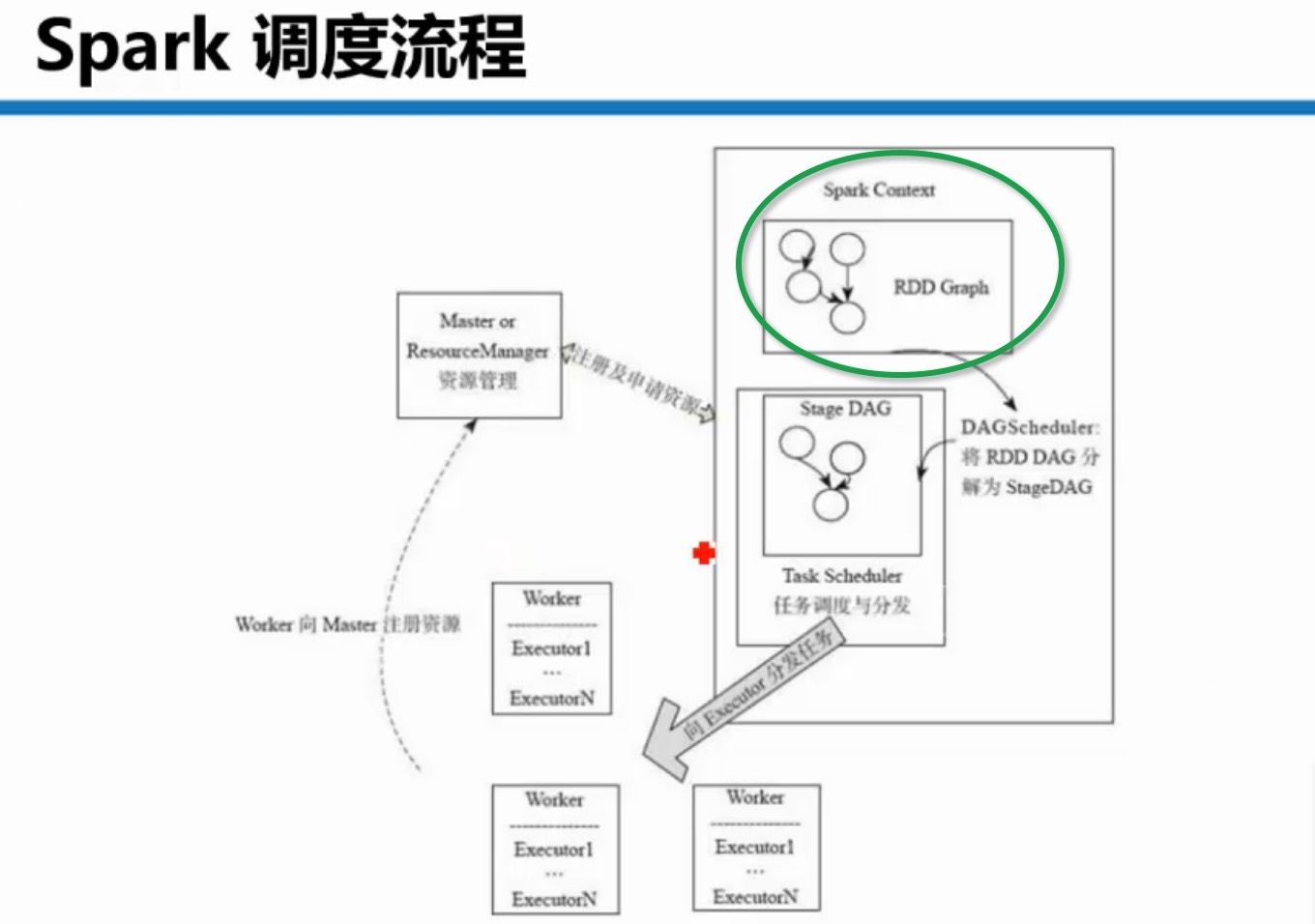
#Spark应用程序运行Cluster和Client两种模式详解
cluster是在集群的某个worker中,client是在本地
所有的schedule都会被driver中的schedulebackend管理
excutor内部是多线程并行执行
#DAGScheduler、TaskScheduler、SchedulerBackend解析
到此,关于“spark创建RDD的方式有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





