本篇内容介绍了“spark2.0集群环境的安装步骤”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
spark2.0已经在apache的官网进行公布。大家可以去下载。今天我就带大家进行安装spark2.0
.spark2.0要求是hadoop2.7.2 +scala2.11+java7 版本不够的请先升级
1.安装hadoop2.7.2
下载地址是:http://hadoop.apache.org/releases.html
下载好后进行解压 tar -zxvf
我在这里用的是伪分布虚拟机的配置
如果对hadoop不熟悉的同学可以参考http://www.linuxidc.com/Linux/2016-02/128729.htm?1456669335754进行安装
提示:对于hadoop测试不要只用jps看进程,这是不准确的。正确的操作是通过页面访问50070和8088端口
2.安装scala2.11
下载地址是http://www.scala-lang.org/download/
下载后进行解压
配置环境变量 vi /etc/profile
这些操作简单。估计大家都会。我再这里不详细描述 不了解的可以去百度
对于scala的测试是scala -version
3.安装spark2.0
下载地址是http://spark.apache.org/news/spark-2-0-0-released.html
下载后也是进行解压tar -zxvf
解压后开始配置
首先在/etc/profile 把spark的环境变量配上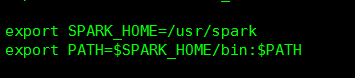
然后配置spark的conf/slaves
把slaves的主机名添加上
然后进行启动
sbin/start-all.sh
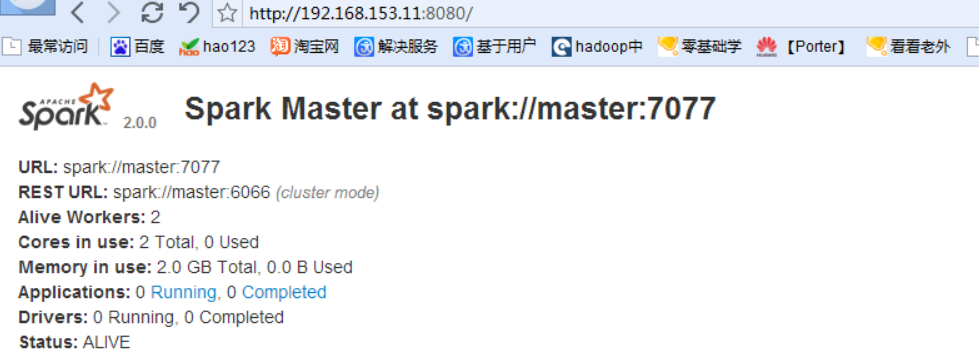
启动成功后可以访问上面的界面注意是master的ip,端口是8080
这样spark环境就安装成功
然后可以跑个demo进行测试例如
bin/run-example org.apache.spark.example.SparkPi
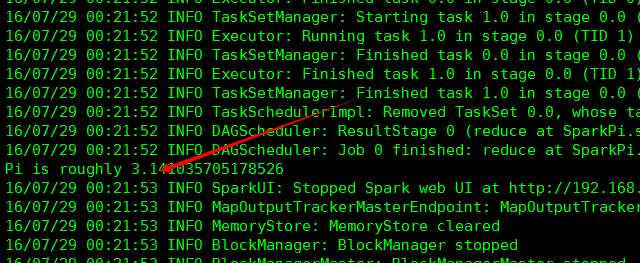
运行成功算出pi的近似值。至此spark环境搭建已经完成
“spark2.0集群环境的安装步骤”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2507413/blog/719671



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



