在工作中时常会遇到对 Excel 表格的处理。当编辑一张 Excel 表格时,发现表格的列数太多,而行数较少,为方便打印,这时你或许会希望将该表格行列转换;或许是为了做进一步做统计分析,当前格式不太方便,这时也会用到行列转换。
下面这种交叉式的 Excel 表是很常见的格式,用来填写和查看都比较方便:
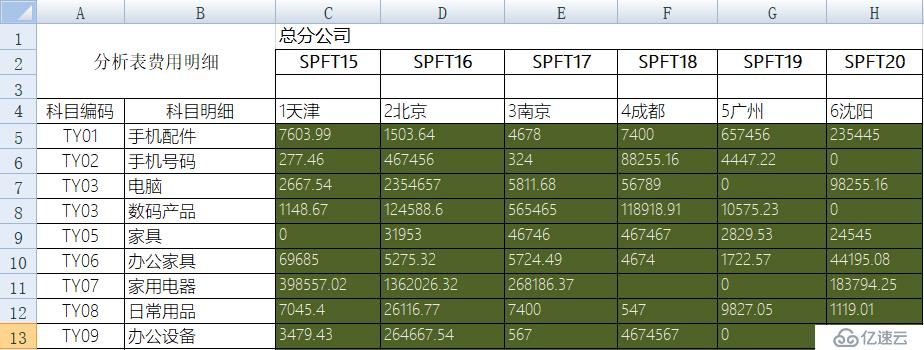
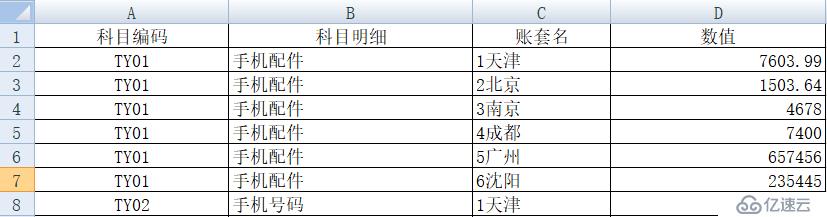
但是,如果想做进一步的统计分析,这种格式就不方便了,需要行列转换,变成如下格式的明细表:
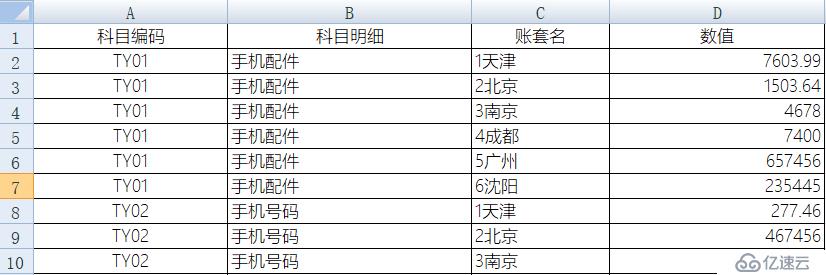
显然,手工操作会非常麻烦,若数据量小还可以,数据量大了会耗费大量时间,简直就是灾难。
我们就以此为例,举例说明几种常见的解决方法。
Excel 可以通过数据透视表支持行列转换功能,效果如下图:
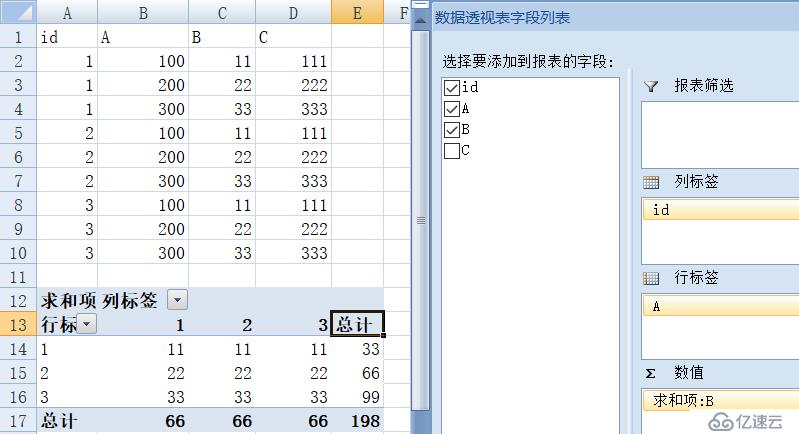
显然,这并不是我们想要的格式。Excel 的数据透视表可以满足简单格式的行列转换,但如果格式稍微复杂,转换效果往往是不尽人意。
以写程序来解决,思路也很简单:
· 加载 excel 文件,装载需要的 sheet 工作表。
· 读取“账套名”所在行,将其转换成字符串数组。
· 读取“科目编码”所在列,将其转换成字符串数组。
· 按“科目编码”分组,与“账套名”数组构造一张表。
· 根据“账套名”对应的数据,遍历所有的明细值填充到相应的表中。
· 这样就可以构造出对应的明细表来。
如果用 Java 来实现,初步估计代码量也不会少于 200 行,若需要结果输出成 excel 文件则开发工作量会更多。虽然 Excel 自己提供了 VBA,但那个麻烦程度谁用谁知道,不提也罢。那其它的语言呢?传说 python 有处理行列转换的功能(pandas 包里有 pivot 功能),代码量相对于 java 会少很多, 我们来试一下:
import pandas as pd
import numpy as np
df = pd.read_excel("D:\\excel\\pandas.xlsx", 0, 3)
cols = df.columns.values.tolist() #获取数据头信息
#移去前两列,只保留需要行列转换的列
cols.remove('科目编码')
cols.remove('科目明细')
#构造一个 list.
frames=[]
for col in cols:
df1 = df.pivot_table(index = ['科目编码','科目明细'], values = [col])
df1.rename(columns={col: '数值'}, inplace=True)
df1[3]=col
#转换后的数据追加到 frames 中.
frames.append(df1)
# concat 将相同字段的表首尾相接
result=pd.concat(frames)
result.rename(columns={3: '帐套名'}, inplace=True)
result.to_excel('D:\\excel\\pandas_n.xlsx', sheet_name='科目明细') import pandas as pd import numpy as np
df = pd.read_excel("D:\\excel\\pandas.xlsx", 0, 3)
cols = df.columns.values.tolist() #获取数据头信息
#移去前两列,只保留需要行列转换的列
cols.remove('科目编码')
cols.remove('科目明细') #构造一个 list.
frames=[] for col in cols:
df1 = df.pivot_table(index = ['科目编码','科目明细'], values = [col])
df1.rename(columns={col: '数值'}, inplace=True)
df1[3]=col #转换后的数据追加到 frames 中.
frames.append(df1) # concat 将相同字段的表首尾相接
result=pd.concat(frames)
result.rename(columns={3: '帐套名'}, inplace=True)
result.to_excel('D:\\excel\\pandas_n.xlsx', sheet_name='科目明细') 效果还不错,果然比较简洁!这是 Python 生成的 excel 文件:
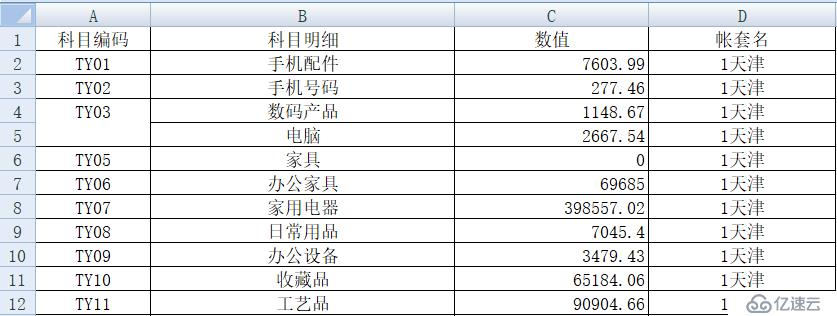
不过,存在一点小问题,这个 excel 格式有点特殊,想用 Python 的 pivot,我们要将“科目编码”,“科目明细”移到与转换列标题所在同一行上,变成下面的样子。否则在代码上就得特殊 “照顾”,反正只有一行,手工做一下就算了,比写代码省事。

无论如何,python 的这个细节处理的小“瑕疵”并不影响其方便性。python 确实名不虚传,虽然使用了循环,但整个代码也就只有 10 来行的样子。
还能更简单吗?
嘿嘿,能!
下面我们来看集算器的代码:
| A | B | |
|---|---|---|
| 1 | =file("D:/excel/ 明细.xlsx").importxls@t(;1,3:40) | // 读入 excel 文件 |
| 2 | >A1.delete(A1.select(_1=="科目编码")) | // 清除首列为“科目编码”所在的行 |
| 3 | >A1.rename(_1: 科目编码,_2: 科目明细) | // 更换列 1 名称为科目编码,列 2 名称为科目明细 |
| 4 | =A1.fname().to(3,).concat(",") | // 将从第 3 列的列名连成字符串,用, 分开 |
| 5 | =A1.pivot@r(科目编码, 科目明细; 账套名, 数值;${A4}) | // 用 pivot 函数进行行列转换 |
| 6 | =file("D:/excel/ 明细 2.xlsx").exportxls@t(A5;"科目明细") | // 将整理好的数据另存储为 xlsx 文件 |
代码很简单,我们把每一步的中间结果列出来看看:
A1:加载 excel 文件工作表 1,提取指定范围的数据 (从 3 行到 40 行),其中选项 @ t 表示首行为标题,载入数据, 生成表格如下:
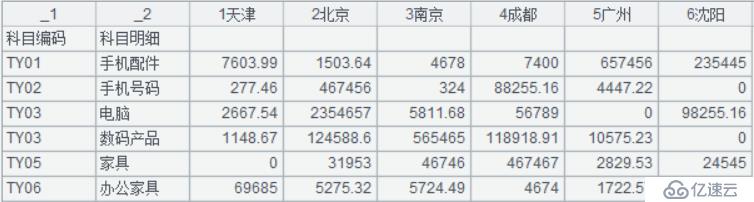
A2:删除非数据行
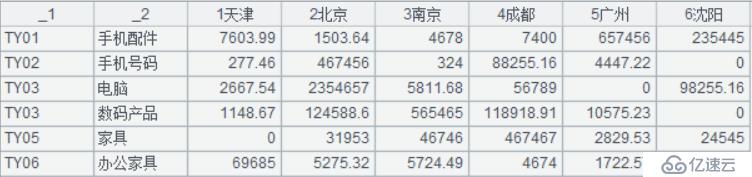
A3:更换列名称
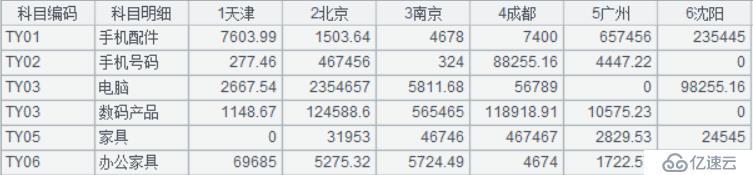
A4:把从第 3 列开始的列名称连成字符串,用“,”分开

A5:pivot 函数将行列数据进行转换,把 A4 中对应的列数据置放到“数值”列
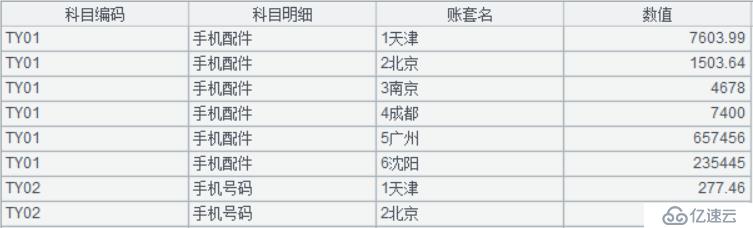
A6:将整理好的数据另存储为 xlsx 文件
集算器脚本只有 6 行,木有啥循环、判断之类的玩意儿,也不像 Python 那样要先手工倒腾一下,就把这看似有点“乱”的数据表格处理好了。相比之下,Python 采用列优先转换多次循环 “N”字方式,集算器则用行优先一次性处理,在处理数据上,集算器对细节处理及使用习惯更专业。而且集算器的开发环境也容易调试,可以看到每一步运算的中间结果,方便挑出错误,开发更为便捷。在这种常规数据处理的任务中,集算器要比 Python 更为优越。
就这个问题,关于 python 与集算器的差异,再说说自己的一点心得体会:
对于需要多列行列转换并汇集成“长”列的场景时,python 需要将每个数据列构造成数组,并增加一列记录当前列名,再追加到一个大的列表中,最后合并,合并中去掉非首个数组中的 title;
集算器就容易些,它直接把想要转换的列汇集在一块就行。相对于 python 的繁琐,集算器至少能省几个脑细胞。
python 对于需要转换列的名称不能更改, 如 cols[0]=’天津’,此时 python 找不到修改前的关键字,“哪个朋友挖的坑,别以为我发现不了”,欺负大爷眼花,给报个异常行不?
但对应的集算器来说则很方便, 如:>A1.rename(_1: 科目编码,_2: 科目明细,4 成都: 成都)
Python 读取 excel 表中的转换行标题时,前面两列为空 (对应原来的 excel 中的“科目编码,科目明细”),此时标题 cols 中的空值就没有了, 这个“坑”有点隐蔽啊,我真没有发现, 把其中的两列弄丢了,真有点丢脸 ;
但集算器能识别出来,会自动加上对应的标识 _1、_2,这样处理数据时,就能找到其中对应的两列。
集算器使用网格 A1 这种格式,它自动与所在位置的对象关联起来,这点非常方便, 感觉很有特色;Python 就只能望洋兴叹了。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





