这篇文章主要介绍stringTie工具有什么用,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
对于转录组数据而言,最基础的分析就是基因和转录本水平的定量了,定量就是确定一个基因或者转录本的表达量,其中定量的方式有很多种。
最直接的方式就是统计mapping到这个基因/转录本上的reads的个数,将reads数作为表达量。我们称这种表达量为raw count。
在raw count的基础上,利用外显子长度进行归一化,就得到了TPM值的定量方式。对于每个基因,将raw count除了该基因的长度(exon长度之和) , 得到长度归一化之后的表达量。某个基因的TPM值就是利用归一化之后的表达量,计算了一个相对丰度。具体计算公式如下,注意基因长度以k为单位

在raw count的基础上,利用测序量和外显子长度两个因素进行归一化,就得到了RPKM/FPKM值的定量方式。首先将raw count除了mapping 上的所有reads数,得到相对丰度,在除以该基因长度(exon长度之和), 就可以计算出RPKM值。测试时每一条插入片段称为一个fragment, 对于双端测序,一个fragment 会得到两条reads。
RPKM和FPKM 唯一不同的地方在于raw count的计算,RPKM 计算的是reads 数,而FPKM 值计算的是fragments 数,对于单端测序, fragment 和 reads 的个数是相等的;对于双端测序,reads 数目是fragments 数目的两倍,对于FPKM 而言,即使双端的两条reads都比对上了基因组,在计数时也知计一次,因为两条reads来源于同一个fragment。
具体计算公式如下, 需要注意单位,mapping上的reads 总数以M为单位,基因长度以k为单位。
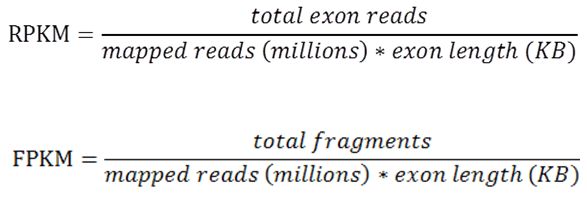
能够进行定量的软件有很多,本文主要介绍stringTie这款软件。
在早期的转录组数据分析中,最经典的分析策略是tophat+cufflinks+cuffdiff, 这套分析的pipeline会给出基于FPKM值的定量结果,然后进行差异分析,但是随着测序数据量的提高和分析手段的发展,这套分析策略出现了很多的问题。
首先就是tophat的速度很慢,相比新出的比对软件,其速度可以算得上是龟速了,同样的数据量,hisat/star只需要半个小时就可以比对完成,tophat2至少需要5到6个小时;其次,基于FPKM值得到的差异结果和实验手段如qPCR验证的一致性较差。
为了顺应测序和分析的新趋势,原本的开发团队对整个pipeline进行了全面升级, 用hisat 代替tophat, 用stringTie + ballgown 代替cufflinks + cuffdiff。
stringTie 可以看做是cufflinks 软件的升级版本,其功能和cufflinks是一样的 ,包括下面两个主要功能
转录本组装
定量
相比cuffinks, 其运行速度更快。该软件的官网如下
https://ccb.jhu.edu/software/stringtie/index.shtml
stringTie的输入文件为经过排序之后的bam文件,常见用法有以下几种
对于模式生物,如human, mouse等,通常只需要对已知的转录本定量即可,用法如下
stringtie -p 10 \
-G hg19.gtf \
-o output.gtf \
-b ballgown_out_dir -e \
align.sorted.bam-G参数指定参考基因组的gtf文件,-o指定输出的文件,格式也为gtf, -b指定ballgown的输出结果目录,这个参数是为了方便下游进行ballgown差异分析,-e参数要求软件只输出已知转录本的定量结果。
在输出的GTF格式的文件中,对于每个转录本,会给出以下3种表达量
coverage
TPM
FPKM
对于单个样本进行组装,用法如下
stringtie align.sorted.bam
-o assembly.gtf
-p 20
-G hg19.gtf在组装的转录本中,也会给出定量的结果,对于组装的新转录本和基因,默认采用STRG加数字编号进行区分,示例如下
gene_id "STRG.1"
transcript_id "STRG.1.1"单个样本组装完成后,会合并所有样本的转录本组装结果,得到一个非冗余的转录本集合,用法如下
stringtie --merge \
-o assembly.gtf \
-p 20 \
-G hg19.gtf \
sampleA.gtf sampleB.gtf在合并的非冗余转录本中,采用MSTRG加数字编号对基因和转录本进行编号,示例如下
gene_id "MSTRG.2"
transcript_id "MSTRG.2.2"本质上,stringTie只提供了转录本水平的表达量,定量方式包括TPM和FPKM值两种。为了进行raw count的定量方式,官方提供了prepED.py脚本,可以计算出raw count的表达量,用法如下
python prepDE.py \
-i sample_list.txt \
-g gene_count_matrix.csv \
-o transcript_count_matrix.csv输入文件为sample_list.txt, 该文件为\t分隔的两列,第一列为样本名称,第二列为定量的gtf文件的路径,示例如下
sampleA A.stringtie.gtf
sampleB B.stringtie.gtf同时输出基因和转录本水平的raw count表达量值。
采用stringTie进行定量,运行速度快是一个优势,同时提供raw count, FPKM, TPM 3种定量方式的结果,也是其最便利的地方。
以上是“stringTie工具有什么用”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4620711



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



