cephfs中怎么实现Elasticsearch数据持久化,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
一、cephfs
cephfs创建
在172.20.0.10上搭建了三节点ceph cluster
10.0.169.87 node1.cephfs-cluster (mons at {node1=10.0.169.87:6789/0})
10.0.149.141 node2.cephfs-cluster
10.0.235.158 node3.cephfs-cluster
每节点上挂在了一块300G数据云盘(采用lvm创建分区,方便以后扩容),在每个节点上将格式化后的文件系统挂载到/var/local/osd[123]
[root@node1 ~]# mount -l | grep cephfs
/dev/mapper/vg--for--cephfs-lvm--for--cephfs on /var/local/osd1 type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
[root@node2 ~]# mount -l | grep cephfs
/dev/mapper/vg--for--cephfs-lvm--for--cephfs on /var/local/osd2 type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
[root@node3 ~]# mount -l | grep cephfs
/dev/mapper/vg--for--cephfs-lvm--for--cephfs on /var/local/osd3 type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
后续可以参考之前给出的两篇文章完成cephfs的创建,然后将cephfs挂载到本地
[root@node1 ~]# mount -t ceph <monitor-ip>:6789:/ /opt -o name=admin,secret=<admin-key>
其中admin-key用如下方式获取
[root@node1 opt]# ceph auth get client.admin
[root@node1 ~]# mount -l | grep opt
10.0.169.87:6789:/ on /opt type ceph (rw,relatime,name=admin,secret=<hidden>,acl,wsize=16777216)
然后在cephfs中创建出后续需要的三个目录
[root@node1 opt]# pwd
/opt
[root@node1 opt]# ll
总用量 0
drwxr-xr-x 1 1000 root 1 8月 1 22:07 elasticsearch_node1
drwxr-xr-x 1 1000 root 1 8月 1 22:07 elasticsearch_node2
drwxr-xr-x 1 1000 root 1 8月 1 22:07 elasticsearch_node3
二、persistent storage
使用简单,建议使用。
在elasticsearch/persistent_storage目录下有如下文件。
drwxr-xr-x. 2 root root 30 7月 31 14:42 cephfs (包含文件 -rw-r--r--. 1 root root 173 7月 30 15:20 ceph-secret.yaml)
-rw-r--r--. 1 root root 1115 7月 31 15:50 replicset_elasticsearch_1.yaml
-rw-r--r--. 1 root root 1115 7月 31 15:50 replicset_elasticsearch_2.yaml
-rw-r--r--. 1 root root 1115 7月 31 15:50 replicset_elasticsearch_3.yaml
其中cephfs的secret文件用于在k8s中创建出secret资源,保存了访问cephfs的key等信息。
replicaset_elasticsearch_1.yaml中需要注意以下内容
volumeMounts:
- name: cephfs
mountPath: /usr/share/elasticsearch/data #将cephfs中的elsticsearch_node1挂载到pod elasticsearch_node1中的/usr/share/elasticsearch/data目录下。
volumes:
- name: cephfs
cephfs:
monitors:
- 10.0.169.87:6789 # cephfs的管理节点
path: /elasticsearch_node1 #之前创建的目录
secretRef: #引用访问cephfs的secret
name: ceph-secret
2.persistent storage架构图
data数据会被永久保存到cephfs中,除非在elasticsearch中删除相关index;或者将cephfs挂载到本地,然后将elasticsearch_node[123]中的内容删除。
这里特别要注意的是elasticsearch_node[123]目录的权限问题,用之前方式创建出来的目录用户为root:root,但是在elasticsearch中需要elasticsearch用户来运行elasticsearch进程,并将数据保存在data中,在elasticsearch的docker image中,已添加更改目录所有者操作,将elasticsearch_node[123]的所有者改为elasticsearch:root,对外映射看到的所有者为1000:root。

3. 为什么要创建3个replicaset来管理3个elasticsearch pod实例,而不是在一个replicaset中将replicas设置为3 ?
在没有添加cephfs存储之前,采用的是使用一个replicaset来管理3个elasticsearch pod。
每个elasticsearch需要不同的空间来存储自己的data数据,不能在replicaset中设置replicas为3,这样会导致每个elasticsearch的/usr/share/elasticsearch/data目录挂载到相同cephfs目录下。不建议在一个pod中创建创建3个container来挂载不同cephfs的目录,这样虽然能工作,但是这些container在同一个worker node上会导致该node负载过重。
三、persistent volume and persistent volume claim
pv/pvc原理同persistent storage类似,此处仅给出相关原理便于理解。
pv/pvc架构图
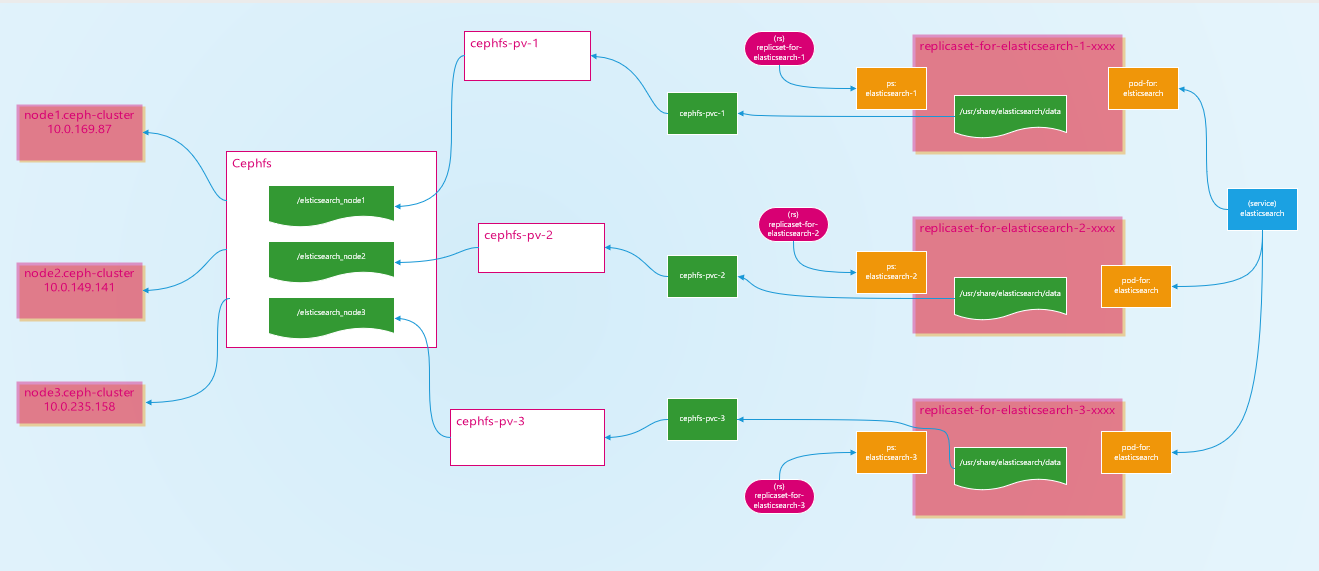
需要以下几点
persitent storage和pv/pvc一样都是利用cephfs提供的posix接口将cephfs挂载到相应的worker node上后再利用docker volume将该目录挂载到container中,可在相应worker node上利用docker inspect查看container的mount信息。
pv/pvc中声明的大小可能并非cephfs中的大小(通常不是),具体能存放多少数据取决于cephfs。pv声明的存储大小是为了pvc选择能够满足其需求的pv时使用。
pv是一类cluster level级别的资源,不属于任何namespace,所以可以被任何namespace中pvc使用。
以cephfs为后端存储的pv,经过验证,其persistentVolumeReclaimPolicy只支持Retain,而不支持Delete和Recycle。意味着删除pvc后,pv中的数据(其实是存储在cephfs文件系统中的数据)不会被删除,但此时该pv不能再被任何pvc所使用,只能删除该pv然后重新创建。因为数据存储在cephfs文件系统中,所以不用担心数据会丢失。Delete会将数据删除,Recycle将数据删除后重新创建pv以为其他pvc提供服务。
四、后期优化
cephfs读写性能。
需要对cephfs的读写性能进行优化,否则elasticsearch在初始化时需要较长时间。如果发现elasticsearch一直无法初始化完成(kubectl get pod 发现ready的数量为0),可能是liveness检测的initialDelaySeconds时间过短,导致elasticsearch还未完成初始化就被liveness kill掉然后重启了相关pod,可以将这个值设置得更长一些。
关于cephfs中怎么实现Elasticsearch数据持久化问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3887035/blog/3107339



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



