本篇文章给大家分享的是有关怎样搭建Serverless AI应用,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
向大家介绍一个典型函数计算的应用场景:AI Model Serving(AI 模型服务化)。
第一部分,我们简单介绍一下什么是函数计算和 AI 推理。函数计算能为 AI 场景做些什么?

 Serverless 分为 FaaS 和 BaaS,阿里云函数计算属于 FaaS,是事件驱动的全托管计算服务。通过函数计算,您无需管理服务器等基础设施,只需编写代码并上传。函数计算会为您准备好计算资源,以弹性、可靠的方式运行您的代码,并提供日志查询、性能监控、报警等功能。
Serverless 分为 FaaS 和 BaaS,阿里云函数计算属于 FaaS,是事件驱动的全托管计算服务。通过函数计算,您无需管理服务器等基础设施,只需编写代码并上传。函数计算会为您准备好计算资源,以弹性、可靠的方式运行您的代码,并提供日志查询、性能监控、报警等功能。
借助于函数计算,您可以快速构建任何类型的应用和服务,无需管理和运维。而且,您只需要为代码实际运行所消耗的资源付费,代码未运行则不产生费用。

如上图所示:是一个完整的机器学习项目的工作流程。
工作流程可以分为三个部分:
首先对原始数据进行预处理;
然后将处理过的数据进行模型训练,会选用不同的参数和算法组合进行多次训练,形成多个备选模型;
最后选一个最合适的模型进行部署。

上述的 3 个步骤,前两个步骤数据处理和模型训练主要由数据科学工作者来完成。最后一步通常是应用开发者的工作。当一个 AI 模型被部署成正式的应用时,需要解决可用性、可靠性和可扩展性等应用开发领域的问题。

函数计算是事件触发型计算服务,上游服务如 OSS、MNS 和 API Gateway 会触发事件,事件会触发函数运行,处理上游数据源的数据。这个机制可以用来做机器学习数据的预处理。

另一个函数计算适合 ML 的场景是适合做 AI Model Serving。上图是一个图片分类的示例,通过 TensorFlow 训练的模型可以部署成函数。当一张新的图片做出输入通过 HTTP 协议发送给函数后,函数会返回对这张图片的分类判断。
下面我们进入第二部分:快速部署一个 AI 应用。(更多详细信息:https://developer.aliyun.com/article/741406)
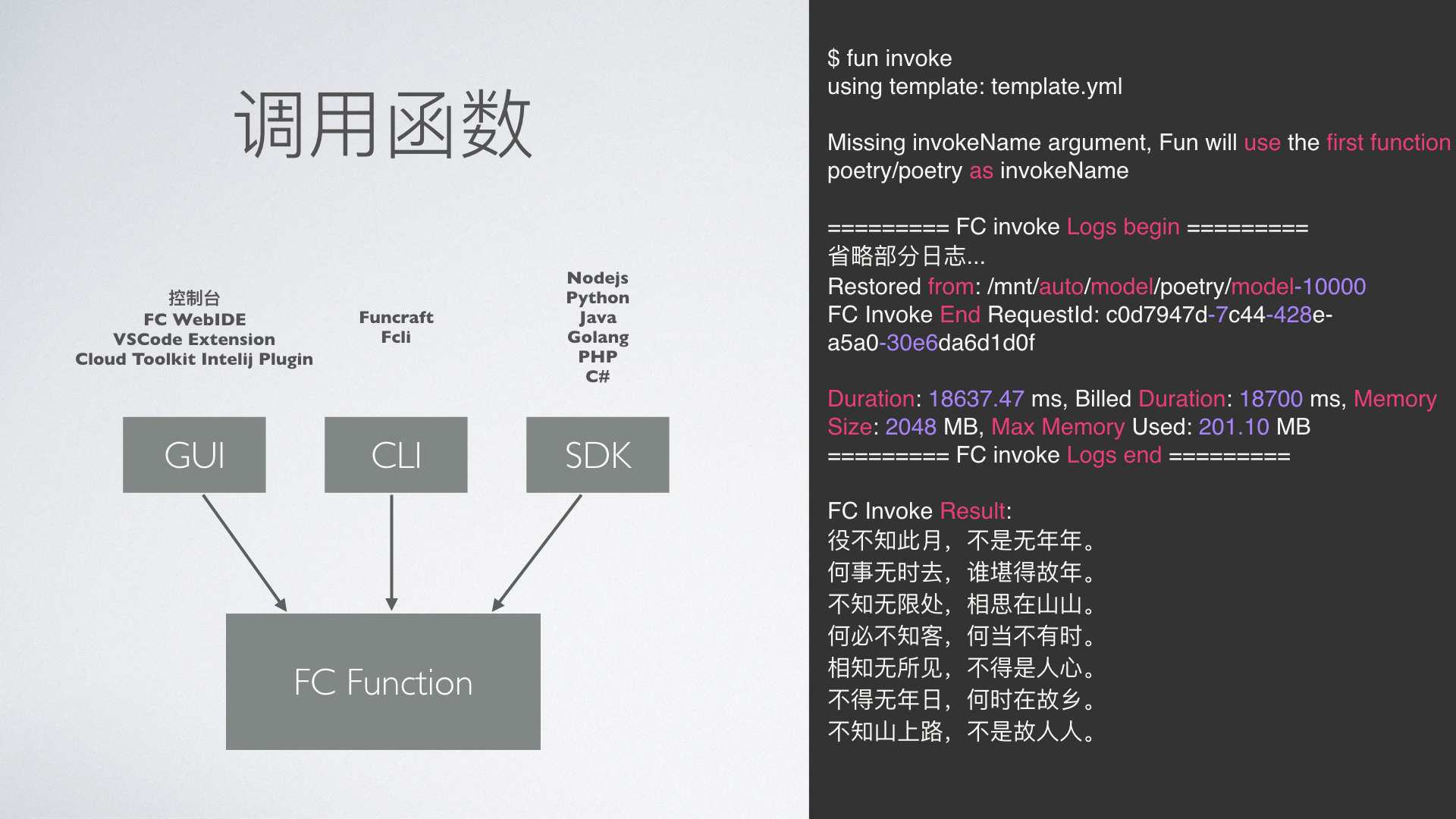
函数支持灵活的调用,分为 GUI、CLI 和 SDK 三种方式:
GUI 有 web 版本的控制台和 IDE,也有本地的插件;
CLI 我们推荐 Funcraft 工具,Funcraft 是个面向工程的开发工具,提供了模板向导、本地开发调试和部署运行等一些功能,Fcli 侧重于对已部署云端的资源进行操作;
SDK 方面,函数计算覆盖了常见语言。
上图右侧是“为你写诗”通过 fun 工具的调用效果。每次调用会返回当次执行的耗时和资源使用情况。返回结果就是由 AI 自动生成的诗句。

上图是“为你写诗”应用的工作原理图。
首先是训练模型,大概有 7 万行五言绝句,通过 TensorFlow 的 CharRNN 训练成模型;然后通过 Funcraft 工具安装 TensorFlow 的 pip 包,用 python 写好调用代码。template.yml 是 ROS 的描述文件,以声明式的方式来描述函数,然后通过 fun deploy 部署函数。
由于 Model 和 TensorFlow lib 会超过函数计算对于部署包 50M 的限制,Funcraft 工具会自动把这两部分部署到 NAS 网盘(如果不存在会提示自动创建),然后运行时函数会像访问本地文件系统一样访问 NAS 网盘上的模型和库文件。
最后用户通过调用函数返回自动生成的诗句。由于函数实例会按照请求量自动扩展,并且按照调用量进行收费,所以快速上线的 AI 服务是一个真实场景下高可用的服务。

要搭建该服务,首选需要安装 git 和 funcraft 工具。funcraft 是一个 github 开源项目,大家可以在 https://github.com/alibaba/funcraft 找到各个平台的安装文件和指南。
然后只需要执行上图中的三个步骤就可以快速地将“为你写诗”应用部署到函数计算平台。
最后一部分,我们会通过不同维度与传统架构对比的方式来总结一下函数计算在 AI 场景的优势。

首先我们看一下函数计算的工程效率:
相比于自建服务(ECS 或者 K8s 集群),函数计算不需要维护基础设施(主机、网络、存储等);
在开发效率上,函数计算通过这些年在 Funcraft 和 VSCode 等工具的建设,解决了应用构建、开发调试和打包部署一系列的痛点,用户可以平滑的上手,通过模板快速部署和二次开发应用;
学习成本上方面,由于函数计算实现了分布式应用的细节,所以只需要专心于实现一个单体应用,更专注于业务。

相比于 ECS 和容器服务,函数计算的弹性更好,支持百毫秒级的弹性,可以更好的应对业务的实时波动。同时也提供了细粒度的、开箱即用的监控报警模块。

上图是一些监控图表,用户可以通过可视化界面直观地理解应用的监控状况。

下面我们来看看一个可用性的对比实验,假设存在上图中的三个 AI 场景:
第一个是部署在 ECS 上的延时敏感应用;
第二个是部署在 ECS 上的成本敏感应用;
第三个是 FC 方案,由于 FC 默认提供了 MKL 加速,所以这也是 FC 的一个小优势。

场景一出现了很多超时或者 5xx 错误,扩容速度太慢, 理论上需要 4 分钟及以上才能扩容:触发报警 3*1min + 购买启动 ECS(1-5min) > 4 min; 同时缩容速度更慢, 只有触发报警 15 * 1min,当然您可以调整触发报警的时间间隔,但是云监控总是分钟级别的粒度,而且设置的值太小,频繁的采购和释放 ECS 并不是一个推荐的操作, 这也是官方推荐扩容是 3 分钟, 缩容 15 分钟的原因;
场景二在压力忽然上升的时候仍然由于扩容不及时导致的 5xx, 同时实例数目图可以看出分钟级别的扩容和缩容速度的滞后在这种场景下可能会严重影响用户体验;
场景三压力和压力的变化明显大于自建 ECS + SLB + ESS 方案,但没有错误,响应时间基本稳定在 200-300ms, 除了冷启动有点毛刺以外。 但是毛刺的最大时间也没有超过 2s:MKL 加速, 单次运算时间短;快速弹性缩容,压力陡升骤降都能快速伸缩,提高资源的使用效率。
不管是延迟敏感型和成本敏感型, FC 都能很好解决快速响应的问题, 冷启动的毛刺可以通过预留实例+预付费去解决。

解决函数冷启动毛刺问题有两条思路:减少单次启动时间和预先启动(预热)。
首先谈谈如何缩短函数的启动时间。函数的启动时间分为两部分:一部分是由平台负责的,包括代码下载、容器启动、运行时初始化和代码初始化;另一部分是由用户负责的代码部分,这部分往往由于业务的不同比较难优化。
关于预启动函数的方式,函数计算 1.0 的时候,会推荐用户使用 Time Trigger 定时触发函数让函数保持住而不被回收。函数计算 2.0 推出了函数的预留模式。通过预留模式,用户可以让函数一直保持住而不回收。

下面我们针对预留模式做一组对比试验。

场景一:当函数执行的请求到来时,由于没有任何预留资源,所有的请求都是按需, 所以每次压力一增大,就会有很多冷启动的,请求毛刺很多,毛刺的时间达到 20s+;
场景二:当函数执行的请求到来时,由于预留资源充足,所有的请求都被调度到预留的实例中被执行, 这个时候是没有冷启动的,所以请求是没有毛刺的;
场景三:当函数执行的请求到来时,优先被调度到预留的实例中被执行, 这个时候是没有冷启动的,所以请求是没有毛刺的, 后面随着测试的压力不断增大(峰值 TPS 达到 1184), 预留的实例不能满足调用函数的请求, 这个时候函数计算就自动进行按需扩容实例供函数执行,此时的调用就有冷启动的过程, 从上图我们可以看出,函数的最大 latency 时间甚至达到了 32s,如果这个 web AP 是延时敏感的,这个 latency 是不可接受的。

上图中的 4 个小图描绘了不同场景下的资源利用率和成本的关系。
图 1:按照峰值进行 ECS 实例预留,资源利用率小于 30%;
图 2:延迟敏感,资源利用率小于 50%;
图 3:成本敏感,相应的会牺牲一些相应性,资源利用率小于 70%;
图 4:基于预留模式+预付费,把弹性的部分使用函数的按量模式,资源的利用率可以做到 80% 以上。

上面四个 Case 的成本核算,最终函数计算组合付费模式的成本最低。
以上就是怎样搭建Serverless AI应用,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3874284/blog/3152981



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



