本篇内容介绍了“Flink的bulkIteration迭代操作怎么实现”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
迭代算法在很多数据分析领域会用到,比如机器学习或者图计算。为了从大数据中抽取有用信息,这个时候往往会需要在处理的过程中用到迭代计算。大数据处理框架很多,比如spark,mr。实际上这些实现迭代计算都是很困难的。
Flink神奇之处就是它直接支持迭代计算。Flink实现迭代的思路也是很简单,就是实现一个step函数,然后将其嵌入到迭代算子中去。有两种迭代操作算子:Iterate和Delta Iterate。两个操作算子都是在未收到终止迭代信号之前一直调用step函数。
本小节是主要是讲解理论。
迭代操作算子包括了简单的迭代形式:每次迭代,step函数会消费全量数据(本次输入和上次迭代的结果),然后计算得到下轮迭代的输出(例如,map,reduce,join等)
1.迭代输入(Iteration Input)
第一次迭代的初始输入,可能来源于数据源或者先前的操作算子。
2. Step函数
每次迭代都会执行step函数。其是由map,reduce,join等算子组成的数据流,根据业务定制的。
3. 下次迭代的部分结果(Next Partial Solution):
每次迭代,step函数的输出结果会有部分返回参与继续迭代。
4. 最大迭代次数
如果没有其他终止条件,就会在聚合次数达到该值的情况下终止。
5. 自定义聚合器收敛:
迭代允许指定自定义聚合器和收敛标准,如sum会聚合要发出的记录数(聚合器),如果此数字为零则终止(收敛标准)。
案例:累加计数
这个例子主要是给定数据输入,每次增加一,输出结果。
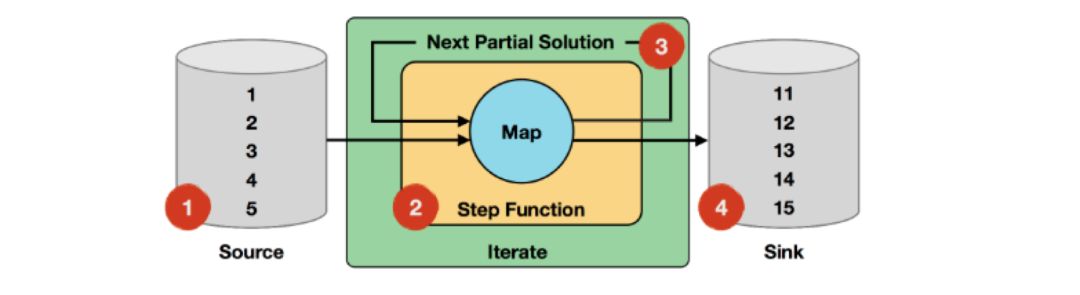
迭代输入:输入是1-5的数字。
step函数:给数字加一操作。
部分结果:实际上就是一个map函数。
迭代结果:最大迭代次数是十次,所以最终输出是11-15.

代码操作
编程的时候,本文说的这种迭代方式叫做bulk Iteration,需要调用iterate(int),该函数返回的是一个IterativeDataSet,当然我们可以对他进行一些操作,比如map等。Iterate函数唯一的参数是代表最大迭代次数。
迭代是一个环有前面的图可以看到,我们需要进行闭环操作,那么这时候就要用到closeWith(Dataset)操作了,参数就是需要循环迭代的dataset。也可以可选的指定一个终止标准,操作closeWith(DataSet, DataSet),可以通过判断第二个dataset是否为空,来终止迭代。如果不指定终止迭代条件,迭代就会在迭代了最大迭代次数后终止。
下面就是通过迭代计算pi的例子。
package Streaming.iteration;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.IterativeDataSet;
public class IteratePi {
public static voidmain(String[] args) throws Exception{
final ExecutionEnvironmentenv = ExecutionEnvironment.getExecutionEnvironment();
// Create initialIterativeDataSet
IterativeDataSet<Integer> initial= env.fromElements(0).iterate(100);
DataSet<Integer> iteration= initial.map(new MapFunction<Integer, Integer>(){
@Override
public Integermap(Integer i) throws Exception{
double x = Math.random();
double y = Math.random();
return i + ((x * x + y * y < 1) ? 1 : 0);
}
});
// Iterativelytransform the IterativeDataSet
DataSet<Integer> count = initial.closeWith(iteration);
count.map(new MapFunction<Integer, Double>(){
@Override
public Double map(Integercount) throws Exception {
return count /(double) 10000 * 4;
}
}).print();
// execute theprogram
env.execute("IterativePi Example");
}
}
“Flink的bulkIteration迭代操作怎么实现”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





