本篇文章给大家分享的是有关Python中怎么使用 pivot_table()实现数据透视功能,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
pivot_table
pivot()函数没有数据聚合功能,要想实现此功能,需要调用Pandas包中的第三个顶层函数:pivot_table(),在pandas中的工程位置如下所示:
pandas
|
pivot_table()
如下,构造一个df实例:
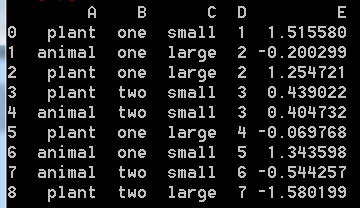
调用如下操作:
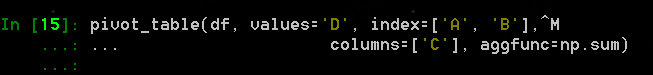
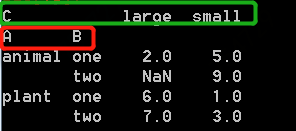
参数index指明A和B为行索引,columns指明C列取值为列,聚合函数为求和,values是在两个轴(index和columns)确定后的取值用D列。得到结果如下:
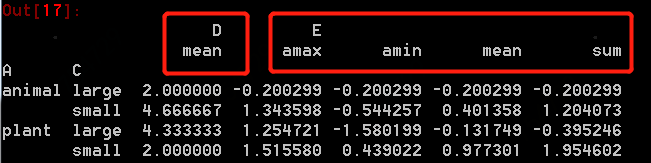
其中聚合函数可以更加丰富的扩展,使用多个。如下所示,两个轴的交叉值选用D和E,聚合在D列使用np.mean(), 对E列使用np.sum, np.mean, np.max, np.min

得到结果如下所示:
函数原型

fill_value: 空值的填充值;
dropna: 如果某列元素都为np.nan, 是否丢弃;
margins: 汇总列, margins_name: 汇总名称
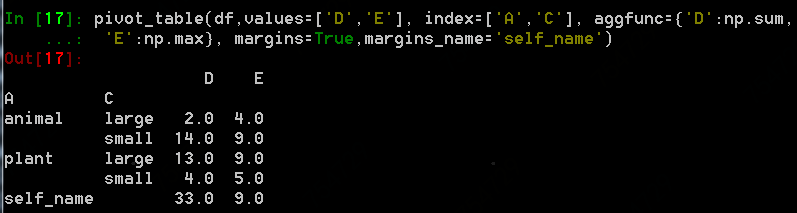
margins参数默认为False,如果设置为True,会得到每列的汇总,如下df实例

设置margins为True,汇总行索引为名称自定义为self_name:
注意
margins设置为True后,目前pandas 0.22.3版本只支持聚合函数为单个元素,不支持为list的情况,如下:
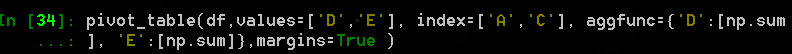
会报出异常:
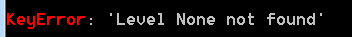
透过pivot_table聚合功能源码(如下所示),我们发现它本身是通过调用groupby()及其agg()实现的。
grouped = data.groupby(keys, observed=False)agged = grouped.agg(aggfunc)以上就是Python中怎么使用 pivot_table()实现数据透视功能,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4585819/blog/4583536



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



