这篇文章主要介绍“如何使用HiCUP进行Hi-C数据预处理”,在日常操作中,相信很多人在如何使用HiCUP进行Hi-C数据预处理问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”如何使用HiCUP进行Hi-C数据预处理”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
HiCUP是一款经典的Hi-C数据预处理软件,官网如下
https://www.bioinformatics.babraham.ac.uk/projects/hicup/
数据处理的流程示意如下
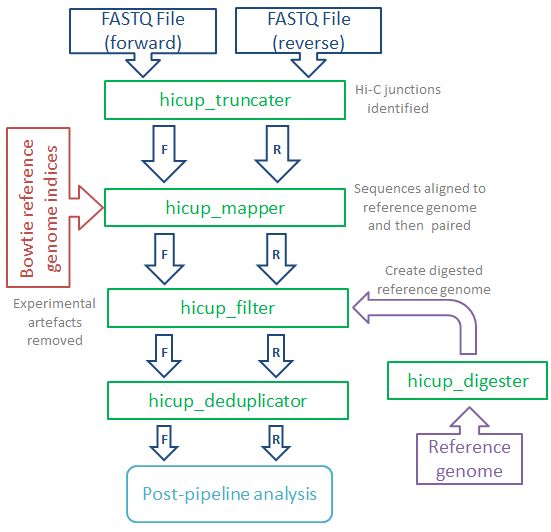
首先通过hicup_truncater识别原始序列中的junction reads, 最典型的Hi-C的reads如下所示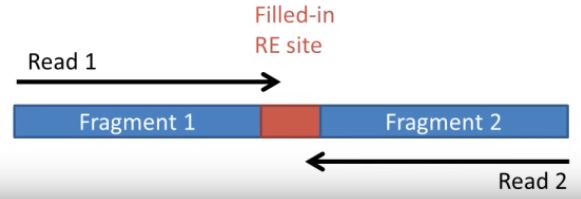
R1和R2来自两个不同的fragments, 当然这取决于插入偏度长度和读长的关系,当连接点与fragment两端的距离小于测序读长是,会发生下图所示的情况
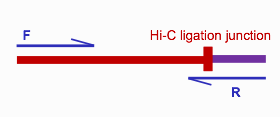
其中一端的序列是一个嵌合体序列,这样的序列在后续比对时会被过滤掉。为了保留这部分有效reads,hicup_truncater根据酶切位点的特征来识别所有reads上的连接位点,从而识别上图中的嵌合体序列,并对这样的序列末端进行切割,切除多余的嵌合体序列。切割完之后,这样的序列和普通的R1,R2就一样了,可以进行后续的mapping。
hicup_mapper将双端reads与参考基因组比对,由于Hi-C文库的R1和R2来源于空间结构近的染色质,其线性距离比传统的双端测序插入片段的长度大的多,如果直接进行双端比对,觉得部分reads都比对不上参考基因组,所以这里是对每一端的序列分别比对,然后再进行合并。
hicup_filter对比对上的序列进行过滤,如下图所示
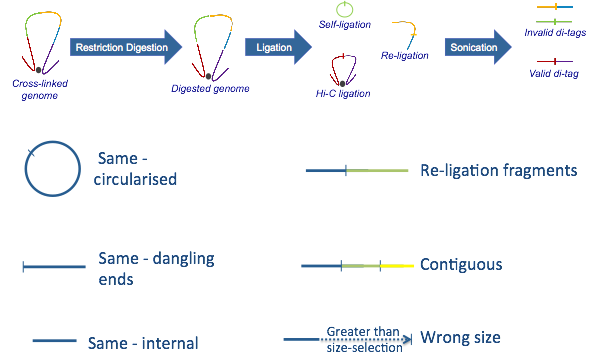
只保留valid di-tags, 其他诸如selft-ligation, Re-ligation等片段都会被过滤掉。
hicup_deduplicator用来去除PCR重复,因为valid reads的多少用来表征染色质互作的频率,PCR重复的reads数量会对这个信息造成干扰,如果不去除PCR重复,junction reads的数目多可能是PCR重复多,不一定是因为染色质交互频率强而导致的reads多。
软件的安装也很方便,直接下载解压缩即可。使用步骤如下
所有的参考基因组比对软件都需要事先对基因组建立索引,HiCUP支持使用bowtie或bowtie2进行比对,以bowtie2为例,建立基因组索引的方式如下
bowite2-build hg19.fa hg19
第一个参数是基因组的fasta文件,第二个参数是输出的索引文件的名称。
采用hicup_digester这个脚本来创建基因组的酶切图谱,基本用法如下
hicup_digester \
--re1 A^AGCTT,HindIII \
--genome hg19_digester_db \
hg19.fa根据限制性内切酶识别的位点,将基因组序列进行模拟酶切,得到所有可能的酶切片段。--re1指定切割位点的序列和内切酶的名字,--genome指定输出文件的名称。最终输出的文件名示例如下
Digest_hg19_digester_db_HindIII_None_09-46-07_17-05-2019.txt
首先通过如下命令生成一个配置文件的模板
hicup --example
该命令会生成一个名为hicup_example.conf的文件,在此基础上进行编辑就可以了。在配置中对每个选项都体用了详细的注释,根据需求修改即可。常用的修改的选项如下
#Path to the reference genome indices
#Remember to include the basename of the genome indices
Index: /bi/scratch/Genomes/Human/GRCh48/Homo_sapiens.GRCh48
#Path to the genome digest file produced by hicup_digester
Digest: /bi/scratch/Genomes/Human/GRCh48/Digest_Homo_sapiens_GRCh48_HindIII_None_14-43-31_10-02-2016.txt.gz
#FASTQ files to be analysed, placing paired files on adjacent lines
s_1_1_sequence.fastq.gz
s_1_2_sequence.fastq.gz包括基因组索引和酶切图谱的路径,以及需要处理的Hi-C原始fastq文件的路径。
准备好配置文件之后,就可以运行了,用法如下
hicup --config hicup.conf
在输出结果的目录会生成一个html文件,展示了质控的各项指标,内容如下所示
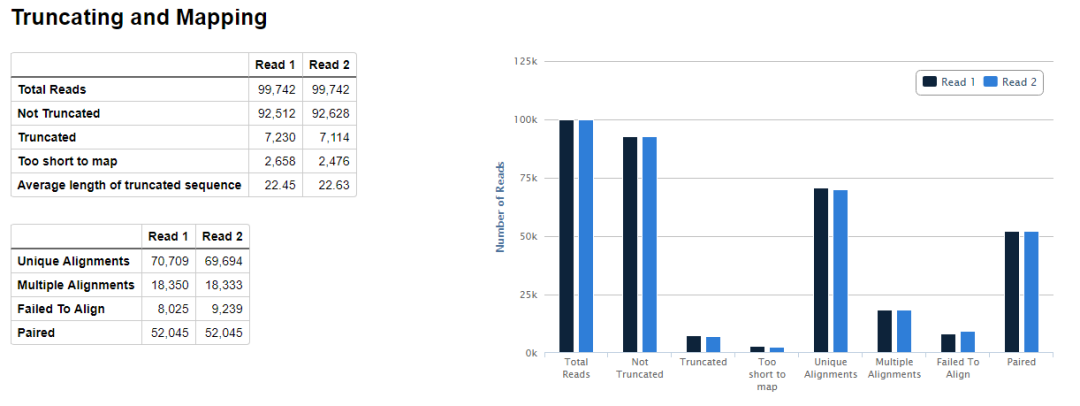
示意如下,可以看到valid pairs的比例在50%左右
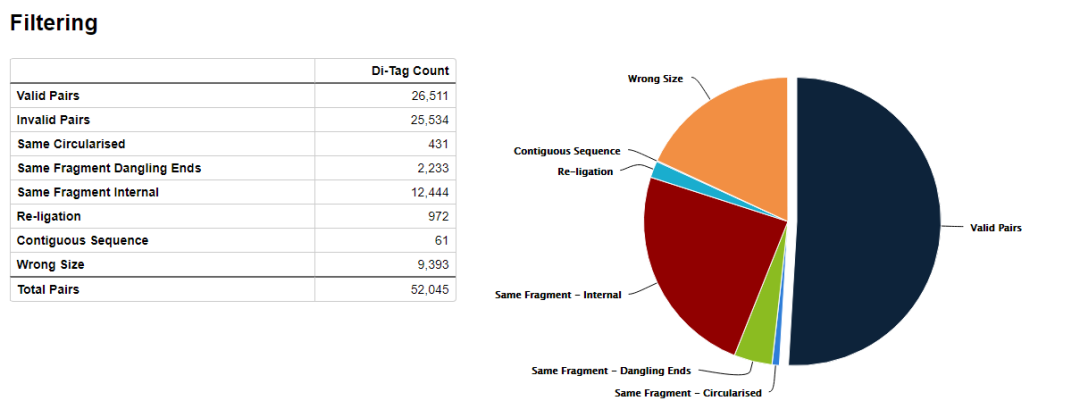
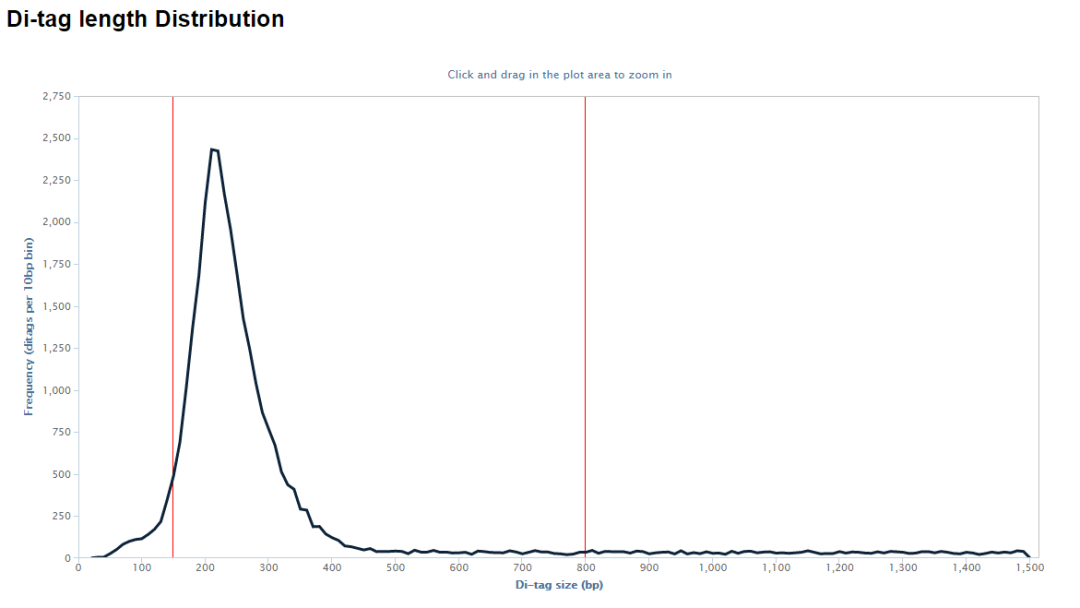
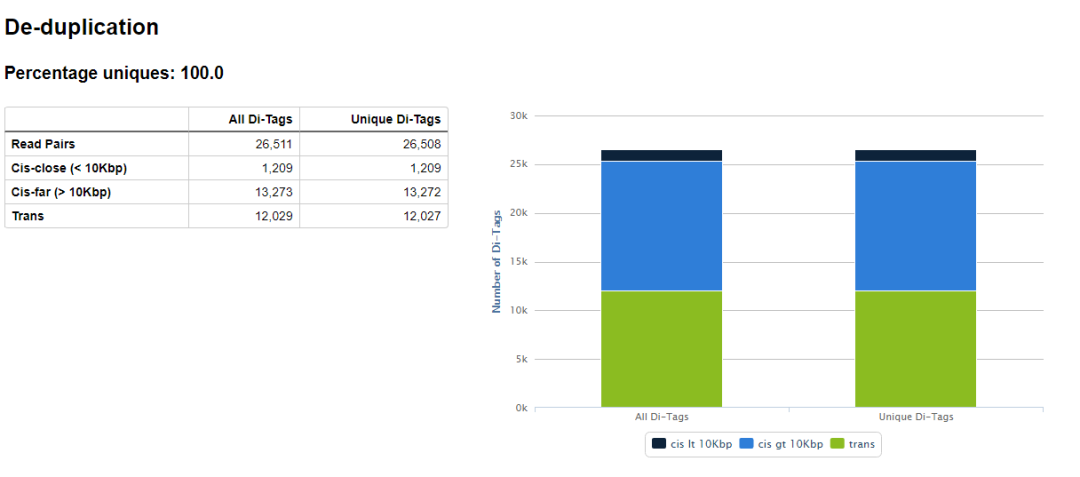
除此之外,输出目录还有很多的文件,其中后缀为hicup_bam的文件包含了最终的de-duplication之后的reads的比对结果,可以用于下游的分析。
到此,关于“如何使用HiCUP进行Hi-C数据预处理”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





