本篇内容介绍了“怎么用R语言进行KM生存”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
R是数据分析常用的软件之一,通过各种功能强大的R包,可以简单方便的实现各种分析。在R语言中,能够进行生存分析的R包很多,survival和survminer是其中最基本的两个,survival负责分析,survimner负责可视化,二者相结合,可以轻松实现生存分析。具体过程如下
对于每个个体而言,其生存数据会出现两种情况,第一种是观测到生存时间,通常用1表示,第二种则是删失。通常用0表示。survival自带了一个测试数据lung, 内容如下所示
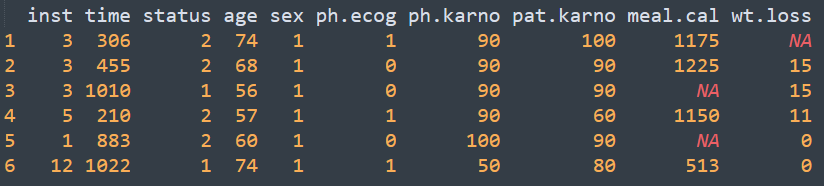
每一行代表一个样本,time表示生存时间,status表示删失情况,这里只有1和2两种取值,默认排序后的第一个level对应的值为删失,这里则为1表示删失。其他列为样本对应的性别,年龄等基本信息。
这里根据性别这个二分类变量,采用KM算法来估计生存曲线,代码如下
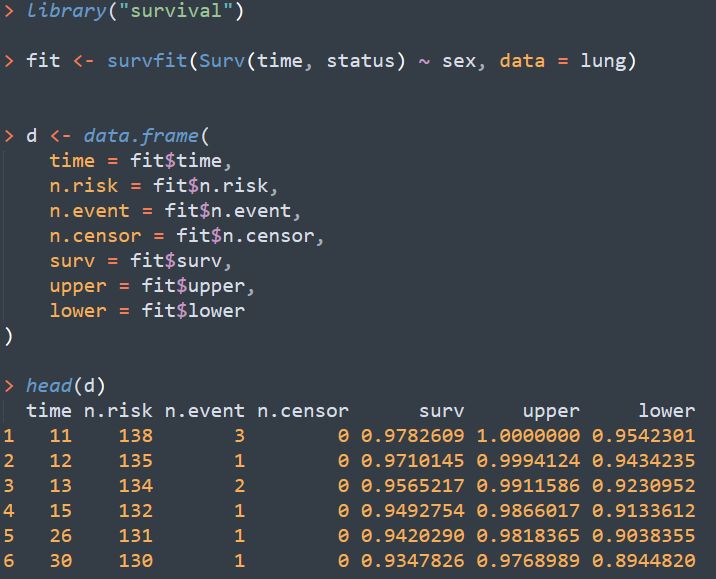
从fit中提取结果构成了d这个数据框,可以看到已经包含了每个时间点的生存概率,删失等信息,通过这些信息,完全可以自己写代码来画图。为了方便,我们直接采用survminer中的函数来进行可视化。
最基本的可视化方式如下
library("survminer")
ggsurvplot(fit)效果图如下所示
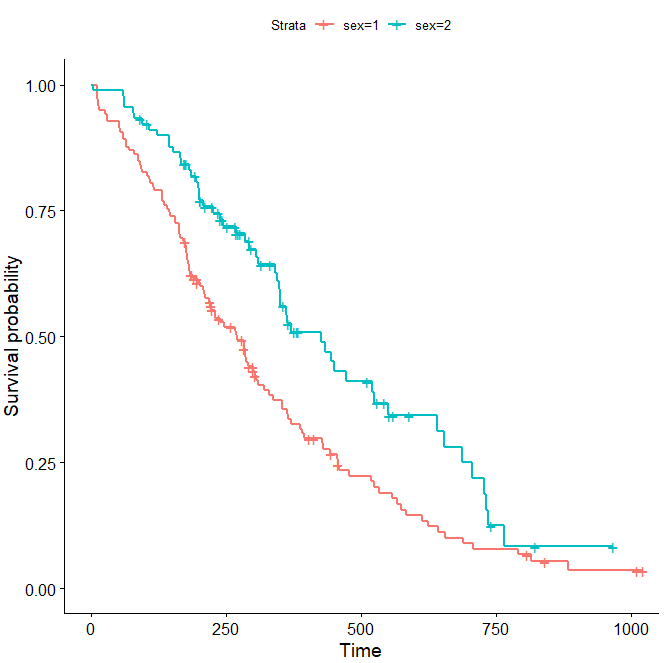
两条不同颜色的折线代表不用性别的生存曲线。对于两组生存数据,通常都需要比较二者之间是否具有差异,最常用的算法是log-rank test。survminer在可视化结果时,也支持进行差异检验,并将对应的p值标记在图上,代码如下
ggsurvplot(fit, pval = TRUE)
效果图如下
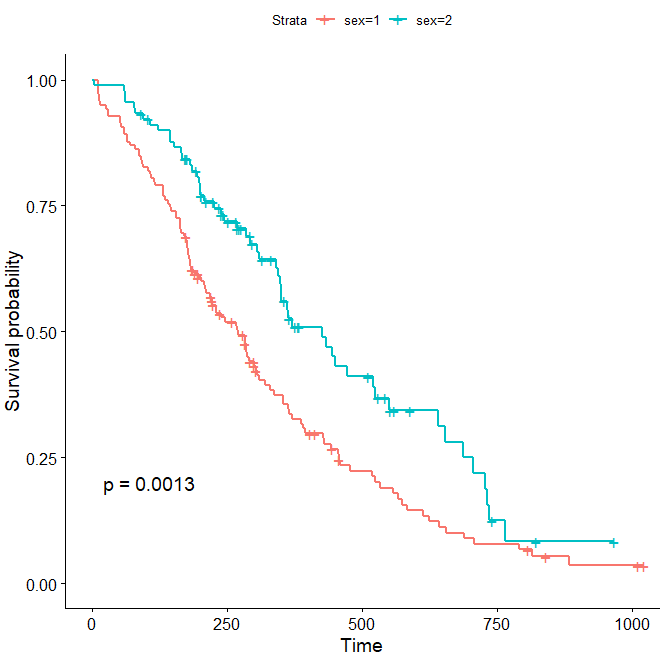
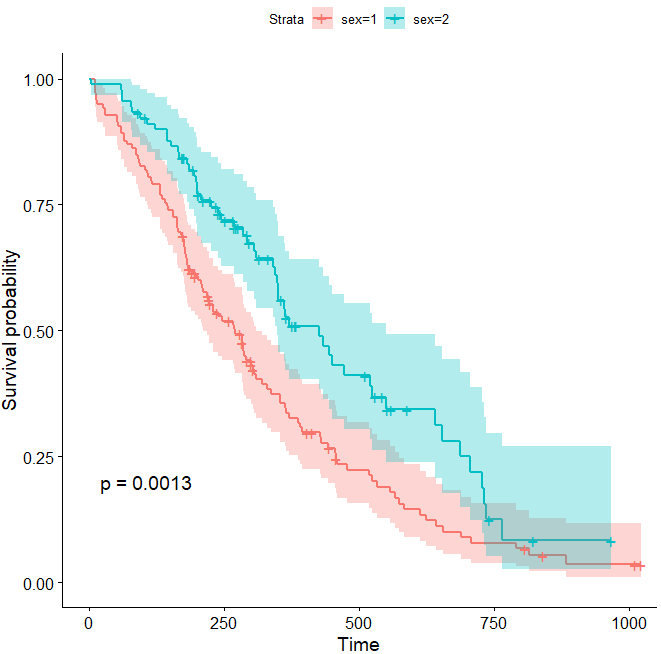
上图中的p值小于0.05,说明不同性别的生存曲线存在显著差异。除了这些基本功能外,该函数还有多个参数,可以灵活的展示结果,比如添加置信区间,代码如下
ggsurvplot(fit, pval = TRUE, conf.int = TRUE)
效果图如下
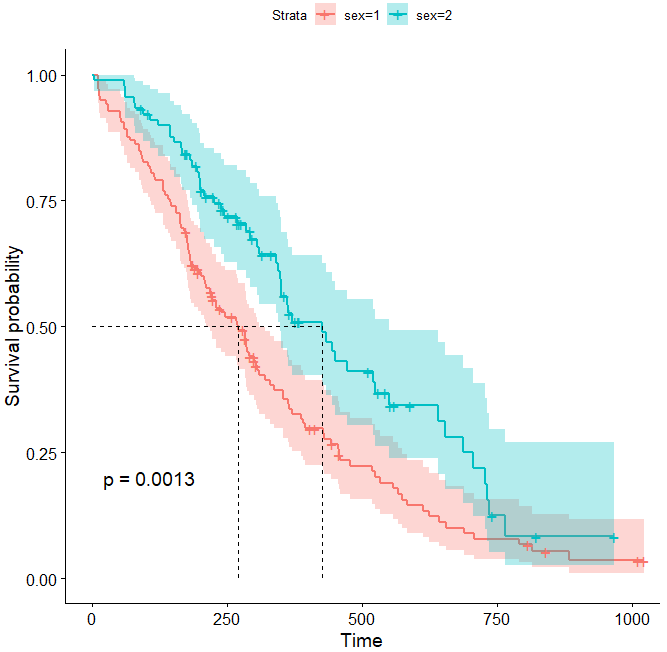
也支持标记生存时间的中位数,代码如下
ggsurvplot(fit, pval = TRUE, conf.int = TRUE, surv.median.line = "hv")
效果图如下
该函数还有非常多的参数,可以非常个性化的调整可视化结果,更加详细的参数用法请参考官方的帮助文档。
“怎么用R语言进行KM生存”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





