本篇文章给大家分享的是有关Spark原理的实例分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Hadoop存在缺陷:
基于磁盘,无论是MapReduce还是YARN都是将数据从磁盘中加载出来,经过DAG,然后重新写回到磁盘中
计算过程的中间数据又需要写入到HDFS的临时文件
这些都使得Hadoop在大数据运算上表现太“慢”,Spark应运而生。
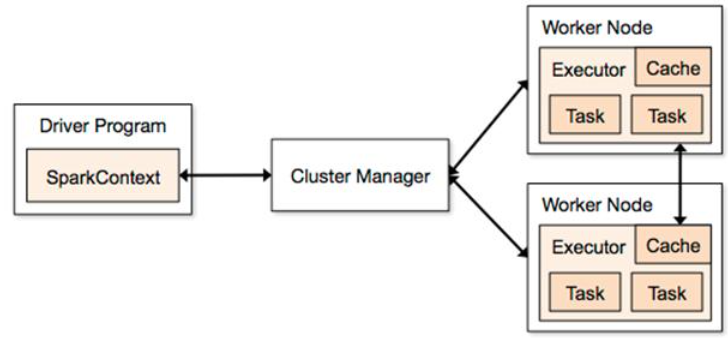
Spark的架构设计:
ClusterManager负责分配资源,有点像YARN中ResourceManager那个角色,大管家握有所有的干活的资源,属于乙方的总包。
WorkerNode是可以干活的节点,听大管家ClusterManager差遣,是真正有资源干活的主。
Executor是在WorkerNode上起的一个进程,相当于一个包工头,负责准备Task环境和执行Task,负责内存和磁盘的使用。
Task是施工项目里的每一个具体的任务。
Driver是统管Task的产生与发送给Executor的,是甲方的司令员。
SparkContext是与ClusterManager打交道的,负责给钱申请资源的,是甲方的接口人。
整个互动流程是这样的:
1 甲方来了个项目,创建了SparkContext,SparkContext去找ClusterManager申请资源同时给出报价,需要多少CPU和内存等资源。ClusterManager去找WorkerNode并启动Excutor,并介绍Excutor给Driver认识。
2 Driver根据施工图拆分一批批的Task,将Task送给Executor去执行。
3 Executor接收到Task后准备Task运行时依赖并执行,并将执行结果返回给Driver
4 Driver会根据返回回来的Task状态不断的指挥下一步工作,直到所有Task执行结束。
再看下图加深下理解:
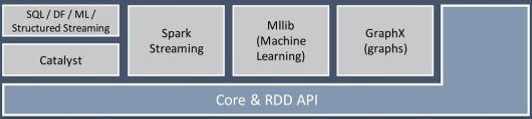
核心部分是RDD相关的,就是我们前面介绍的任务调度的架构,后面会做更加详细的说明。
SparkStreaming:
基于SparkCore实现的可扩展、高吞吐、高可靠性的实时数据流处理。支持从Kafka、Flume等数据源处理后存储到HDFS、DataBase、Dashboard中。
MLlib:
关于机器学习的实现库,关于机器学习还是希望花点时间去系统的学习下各种算法,这里有一套基于Python的ML相关的博客教材http://blog.csdn.net/yejingtao703/article/category/7365067。
SparkSQL:
Spark提供的sql形式的对接Hive、JDBC、HBase等各种数据渠道的API,用Java开发人员的思想来讲就是面向接口、解耦合,ORMapping、Spring Cloud Stream等都是类似的思想。
GraphX:
关于图和图并行计算的API,我还没有用到过。
RDD(Resilient Distributed Datasets) 弹性分布式数据集
RDD支持两种操作:转换(transiformation)和动作(action)
转换就是将现有的数据集创建出新的数据集,像Map;动作就是对数据集进行计算并将结果返回给Driver,像Reduce。
RDD中转换是惰性的,只有当动作出现时才会做真正运行。这样设计可以让Spark更见有效的运行,因为我们只需要把动作要的结果送给Driver就可以了而不是整个巨大的中间数据集。
缓存技术(不仅限内存,还可以是磁盘、分布式组件等)是Spark构建迭代式算法和快速交互式查询的关键,当持久化一个RDD后每个节点都会把计算分片结果保存在缓存中,并对此数据集进行的其它动作(action)中重用,这就会使后续的动作(action)变得跟迅速(经验值10倍)。例如RDD0àRDD1àRDD2,执行结束后RDD1和RDD2的结果已经在内存中了,此时如果又来RDD0àRDD1àRDD3,就可以只计算最后一步了。
RDD之间的宽依赖和窄依赖:
窄依赖:父RDD的每个Partition只被子RDD的一个Partition使用。
宽依赖:父RDD的每个Partition会被子RDD的多个Partition使用。
宽和窄可以理解为裤腰带,裤腰带扎的紧下半身管的严所以只有一个儿子;裤腰带帮的比较宽松下半身管的不禁会搞出一堆私生子,这样就记住了。
对于窄依赖的RDD,可以用一个计算单元来处理父子partition的,并且这些Partition相互独立可以并行执行;对于宽依赖完全相反。
在故障回复时窄依赖表现的效率更高,儿子坏了可以通过重算爹来得到儿子,反正就这一个儿子当爹的恢复效率就是100%。但是对于宽依赖效率就很低了,如下图:
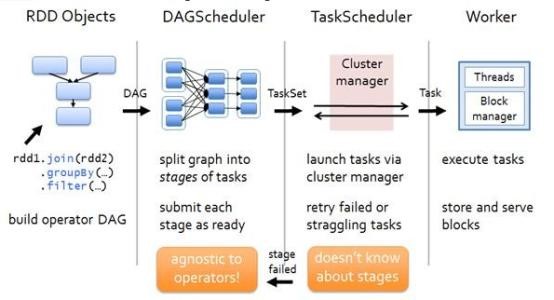
用户编排的代码由一个个的RDD Objects组成,DAGScheduler负责根据RDD的宽依赖拆分DAG为一个个的Stage,买个Stage包含一组逻辑完全相同的可以并发执行的Task。TaskScheduler负责将Task推送给从ClusterManager那里获取到的Worker启动的Executor。
DAGScheduler(统一化的,Spark说了算):
详细的案例分析下如何进行Stage划分,请看下图
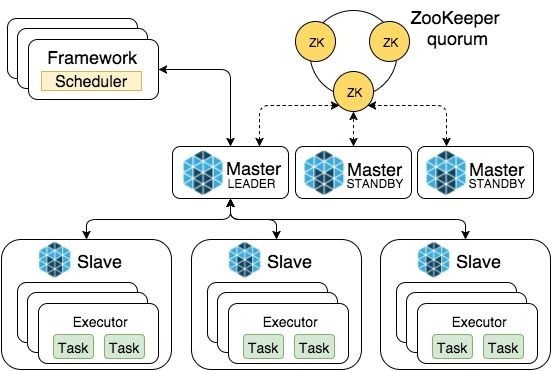
Worker部分采用Master/Slaver模式,Master是整个系统的核心部件所以用ZooKeeper做高可用性加固,Slaver真正创建Executor执行Task并将自己的物理计算资源汇报给Master,Master负责将slavers的资源按照策略分配给Framework。
Mesos资源调度分为粗粒度和细粒度两种方式:
粗粒度方式是启动时直接向Master申请执行全部Task的资源,并等所有计算任务结束后才释放资源;细粒度方式是根据Task需要的资源不停的申请和归还。两个方式各有利弊,粗粒度的优点是调度成本小,但是会因木桶效应造成资源长期被霸占;细粒度没有木桶效应,但是调度上的管理成本较高。
YARN模式:
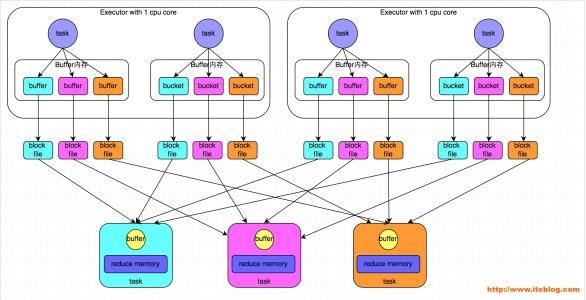
在洗牌过程中StageA每个当前的Task会把自己的Partition按照stageB中Partition的要求做Hash产生stageB中task数量的Partition(这里特别强调是每个stageA的task),这样就会有len(stageA.task)*len(stageB.task)这么多的小file在中间过程产生,如果要缓存RDD结果还需要维护到内存,下个stageB需要merge这些file又涉及到网络的开销和离散文件的读取,所以说超过一定规模的任务用Hash Base模式是非常吃硬件的。
尽管后来Spark版本推出了Consolidate对基于Hash的模式做了优化,但是只能在一定程度上减少block file的数量,没有根本解决上面的缺陷。
Sort Base Shuffle(spark1.2开始默认):
Sort模式下StageA每个Task会产生2个文件:内容文件和索引文件。内容文件是根据StageB中Partition的要求自己先sort好并生成一个大文件;索引文件是对内容文件的辅助说明,里面维护了不同的子partition之间的分界,配合StageB的Task来提取信息。这样中间过程产生文件的数量由len(stageA.task)*len(stageB.task)减少到2* len(stageA.task),StageB对内容文件的读取也是顺序的。Sort带来的另一个好处是,一个大文件对比与分散的小文件更方便压缩和解压,通过压缩可以减少网络IO的消耗。(PS:但是压缩和解压的过程吃CPU,所以要合理评估)
Sort和Hash模式通过spark.shuffle.manager来配置的。
Storage模块:
存储介质:内存、磁盘、Tachyon(这货是个分布式内存文件,与Redis不一样,Redis是分布式内存数据库),存储级别就是它们单独或者相互组合,再配合一些容错、序列化等策略。例如内存+磁盘。
负责存储的组件是BlockManager,在Master(Dirver)端和Slaver(Executor)端都有BlockManager,分工不同。Slaver端的将自己的BlockManager注册给Master,负责真正block;Master端的只负责管理和调度。
Storage模块运行时内存默认占Executor分配内存的60%,所以合理的分配Executor内存和选择合适的存储级别需要平衡下Spark的性能和稳定。
Spark的出现很好的弥补了Hadoop在大数据处理上的不足,同时随着枝叶不断散开,出线了很多的衍生的接口模块丰富了Spark的应用场景,也降低了Spark与其他技术的接入门槛。
以上就是Spark原理的实例分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579082/blog/4555842



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务