可扩展超快OLAP引擎Kylin怎么用,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
Kylin沿用了原来的数据仓库技术中的Cube概念,把无限数据按有限的维度进行“预处理”,然后将结果(Cube)加载到Hbase里,供用户查询使用。
Kylin是通过空间换时间的方式,实现在亚秒级别延迟的情况下,对Hadoop上的大规模数据集进行交互式查询,Kylin通过预计算,把计算结果集保存到Hbase中,原有的基于行的关系模型被转化为基于键值对的列式存储,通过维度组合作为HBase的RowKey,在查询访问时不再需要昂贵的表扫描,这为高速高并发分析带来了可能;Kylin提供了标准SQL查询接口,支撑大多数的SQL函数,同时也支持ODBC/JDBC的方式和主流的BI产品无缝集成。
Kylin的工作原理
1、指定数据模型,定义维度和度量
2、预计算Cube,计算所有Cuboid并保存为物化视图
3、执行查询时,读取Cuboid,运算,产生查询结果
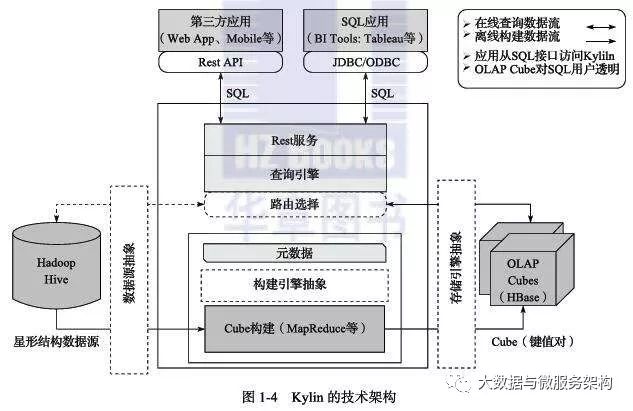
Kylin的的主要特点
1、标准SQL接口
2、支持超大数据集
3、亚秒级响应
4、可伸缩性和高吞吐率
5、BI及可视化工具集成
几个核心概念
数据仓库:(Data Warehouse):大量历史性资料数据。
OLAP:联机分析处理,以多维度的方式分析数据,而且能够弹性的提供上卷、下钻和透视分析等操作。区别于联机交易处理(OLTP):更侧重于日常事务处理,增删改查。
BI:商业智能
维度与度量:维度是指审视数据的角度,通常是数据记录的一个属性,eg:时间、地点等,度量是基于数据所计算出来的考量值。eg:销售额,用户数等
事实表和维度表:事实表存储有事实记录的表,eg:系统日志、销售记录等,事实表不断动态增长。维度表保存了维度的属性值,eg:日期表、地点表等
Cube、Cuboid和Cube Segment
Cube:数据立方体,常用于数据分析和索引的技术,他可以对原始数据建立多维度索引,通过Cube对数据进行数据进行分析,大大加快数据的查询效率。
Cuboid:在Kylin中特制某一中维度组合下所计算的数据
Cube Segment:是指针对源数据中的某一片段,计算出来的Cube数据。通常数据仓库中的数据会随着时间的增长而增长,而Cube Segment也是按时间顺序来构建的。
Apache Kylin的主要使用过程:
1、数据准备:符合星型模型、维度表设计(Kylin将维度表加载到内存中处理,所有维度表不能太大)、Hive表分区 。
2、设计Cube:导入Hive表定义、创建数据模型
3、创建Cube:Kylin是以Key-Value的方式将Cube存储到Hbase中,Hbase的Key也就是RowKey是由各个维度的值拼接而成的。
4、构建Cube:增量构建和全量构建
5、历史数据刷新、合并(Segment)
6、查询Cube,标准的SQL的select语句。
支持构建方式:
增量构建:分全量和增量
流式构建:实现实时数据更新,对接Kafka实现,目前存在丢失数据的风险
支持对接方式:
1、WEB GUI --- Insight页面
2、Rest API
3、ODBC/JDBC
4、通过Tableau(BI)访问Kylin。
看完上述内容,你们掌握可扩展超快OLAP引擎Kylin怎么用的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3454764/blog/4550530



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



