今天就跟大家聊聊有关如何用MNIST数据集进行基于深度学习的可变形图像配准的验证,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
用MNIST数据集做了一个简单图像配准方案的验证,效果不错。
Sarath Chandra
https://medium.com/@sarathchandra.knv31/deep-learning-based-2d-deformable-image-registration-with-mnist-2db3b6ee1426
我被Google Summer of Code 2020录取,进行基于深度学习的图像配准的研究工作。我的项目链接 —— MRI Registration using Deep Learning and Implementation of Thin-Plate Splines
图像配准是找到将一幅图像对齐到另一幅图像的转换的过程。通常,这个过程的输入是两幅图像:一个参考图像,也称为静态图像,和一个将与静态图像对齐的移动图像。这里的目标是对移动图像进行扭曲以匹配到静态图像。
给定一个移动图像和静态图像作为输入,卷积编码器-解码器网络计算两个图像之间的像素变形。这个变形场也称为配准场,给出了运动图像中新的采样位置。通过对这些位置的运动图像进行采样,得到变换后的图像。简单地说,我们只是重新安排移动图像中的像素,直到它尽可能地与静态图像匹配。框架如下图所示。
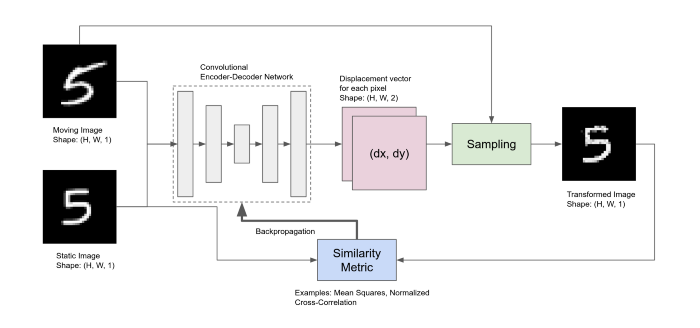
通过对编解码器网络进行训练,输出一个dense的变形场,该变形场被采样器用来使运动图像与静止图像相匹配。
采样点不一定映射到移动图像中的整数位置。所以当点是分数时需要一些插值技术。此外,为了使整个框架是端到端可训练的,采样块也需要是可微的。可以使用“Spatial transformer networks”。
正如“Spatial transformer networks”中描述的,我使用了双线性插值,它是可微的,可以写成纯张量流函数。在双线性插值中,分数位置上的值是四个最近整数位置上的值的加权和。
通过优化变换后的图像和静态图像之间的相似性度量来训练网络。一旦训练完成,网络可以一次性预测最优配准域,这与传统算法不同,传统算法需要对每一对新配准进行数值优化,因此需要更长的时间。
MNIST数据集经过筛选,只保留一类图像,而静态图像是从筛选数据集的测试集中随机选择的。网络使用相似度度量进行训练,这是衡量两幅图像的相似/不相似程度的指标。一些度量的例子包括均方误差(MSE)和归一化交叉相关(NCC)。由于交叉相关损失对强度变化具有鲁棒性,所以使用了交叉相关损失。它就是两个归一化的图像的点积。数学上是:
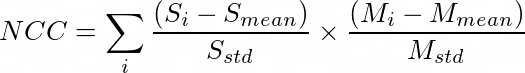
S和M分别代表静态图像和运动图像。下标mean和std分别表示图像的均值和标准差。对图像中所有像素求和。该训练在Tesla K80 GPU上大约需要5分钟,在CPU (i5-8250U)上大约需要10分钟。

看完上述内容,你们对如何用MNIST数据集进行基于深度学习的可变形图像配准的验证有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1416903/blog/4548857



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



