Python中怎么利用Mitmproxy爬取公众号文章,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
将手机端的代理IP设为pc端的IP地址
当我们安装好证书后,就可以进行如下操作。首先在pc端的开始栏输入cmd,然后输入控制命令ipconfig,查看pc端的IP地址,如下图;
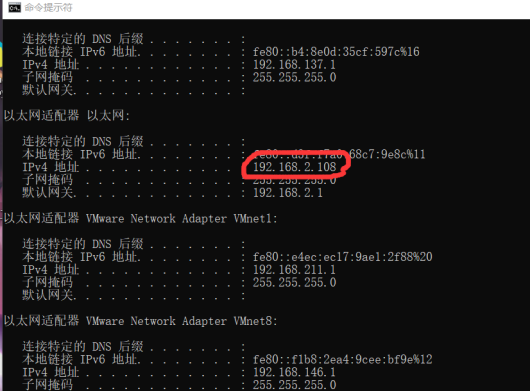
然后在手机端的所连接的wifi选项中打开代理ip手动设置,用户名填入IPv4地址,端口一般设为8080即可。
爬取文章阅读信息
完成上述操作后,我们就进行py代码的如下操作。
代码修改操作
在参考博客中我们只需要修改wxCrawler.py这个py代码即可,其余代码均可不必修改,因为该代码是爬取文章的关键。我们将wxCrawler.py代码的爬取链接改为爬取到的文章的阅读信息即可;wxCrawler.py在for循环处导入参考博客text_01.py代码类传入相应的参数,(参考博客为articles.py代码);只做这一处修改即可完成爬取公众号文章阅读信息。
text_01.py代码

修改后的wxCrawler.py代码


运行结果示例:
以该公众号为例的测试结果图为;
注意事项
事项1:将所有的py代码放入同一个文件夹。
事项2:阅读该博客前,请先阅读参考博客和关于参考博客难点介绍的那篇博客。
事项3:尽量用pycharm打开文件夹运行py代码。
事项4:参考博客中的代码存在代码缩进,符号等问题,在上一篇博客我已经将其修改完毕,只需要将wxCrawler.py代码改为修改后的代码然后加入text_01.py代码即可。
关于Python中怎么利用Mitmproxy爬取公众号文章问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/gschen/blog/4499454



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



