R语言jiebaR包文本中文分词及词云制作的示例分析,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
微信出现之前,qq群是我和读者交流的主要阵地,一般我会问大家为什么入群这样一个问题,收集到一些有趣的回答,今天就以这组文本数据练习中文分词和词云图的制作。

首先我们先从excel读取数据
data <- read.xlsx("why.xlsx")data <- data[,1]准备jiebaR包和分词引擎
library(jiebaR)engine <- worker()开始分词
fc <- segment(data,engine)
我们会发现分词质量不高,有些词语要剔除。
准备停止词stopwords.txt
t <- readLines('stopwords.txt')stopwords<-c(NULL)for(i in 1:length(t)){stopwords[i]<-t[i]}开始过滤
fc2 <- filter_segment(fc,stopwords)过滤之后,我们发现此时的关键词更加凸显。

统计词频
freq <- sort(table(fc2),decreasing = T)简单画个饼图看看效果咋样吧
pie(head(freq))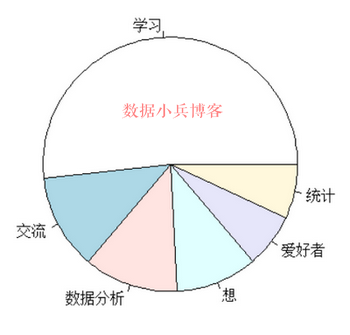
联想造句:爱好者想学习和交流数据分析和统计(这个意思非常符合入qq群目标)。
把关键词和词频转换为数据框结构
mydata=data.frame(word=names(freq),freq=as.vector(freq),stringsAsFactors= F)
制作一个词云图吧
library(wordcloud2)wordcloud2(mydata,size = 1.5)这就是最终效果了,简单总结一下:入群最主要的目的是“学习”“数据分析”以及“统计”了,ta们都有谁内?有“爱好者”、“新手”、“研究生”,不管是“交流”,或是“请教”“咨询”,总是是要“谢谢”“数据小兵”(纯属娱乐造句)。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/datasoldier/blog/4460297



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



