不使用selenium插件如何抓取网页的动态加载数据,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
下面讲的是不使用selenium插件模拟浏览器,如何获得网页上的动态加载数据。
步骤如下:
一、找到正确的URL。
二、填写URL对应的参数。
三、参数转化为urllib可识别的字符串data。
四、初始化Request对象。
五、urlopen这个Request对象,获得数据。
url='http://www.*****.*****/*********'formdata = {'year': year,'month': month,'day': day}data = urllib.urlencode(formdata)request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)r = urllib2.urlopen(request)html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式后面步骤都是相同的,关键在于如何获得URL和参数。我们以新冠肺炎的疫情统计网页为例(https://news.qq.com/zt2020/page/feiyan.htm#/)。
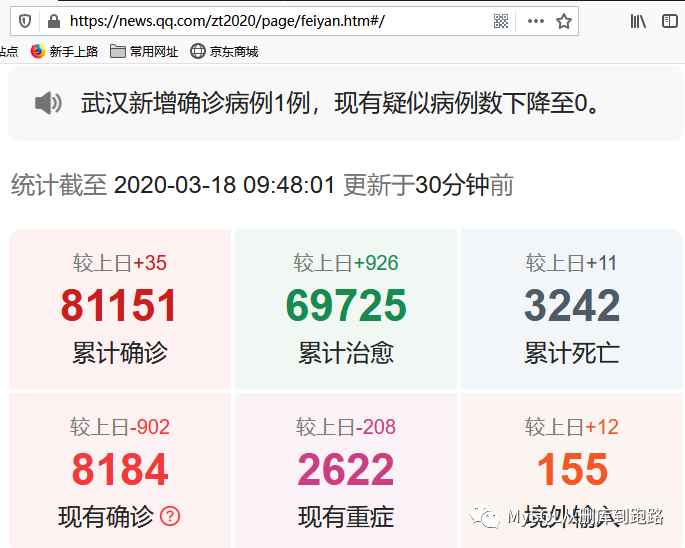
如果直接抓浏览器的网址,你会看见一个没有数据内容的html,里面只有标题、栏目名称之类的,没有累计确诊、累计死亡等等的数据。因为这个页面的数据是动态加载上去的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获得URL和对应参数formdata。下面以火狐浏览器讲讲如何获得这两个数据。
肺炎页面右键,出现的菜单选择检查元素。
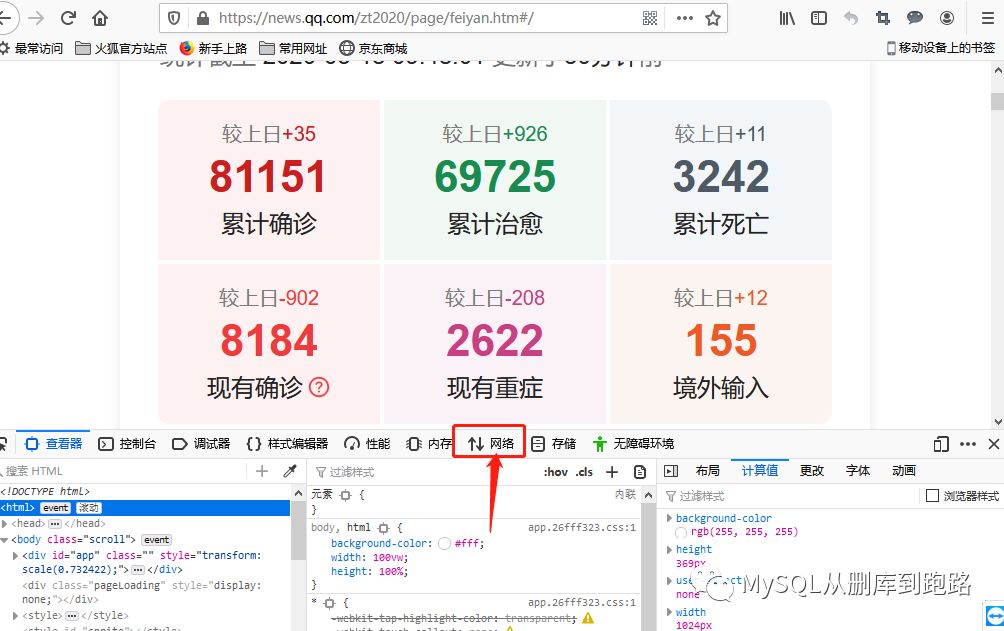
点击上图红色箭头网络选项,然后刷新页面。如下,
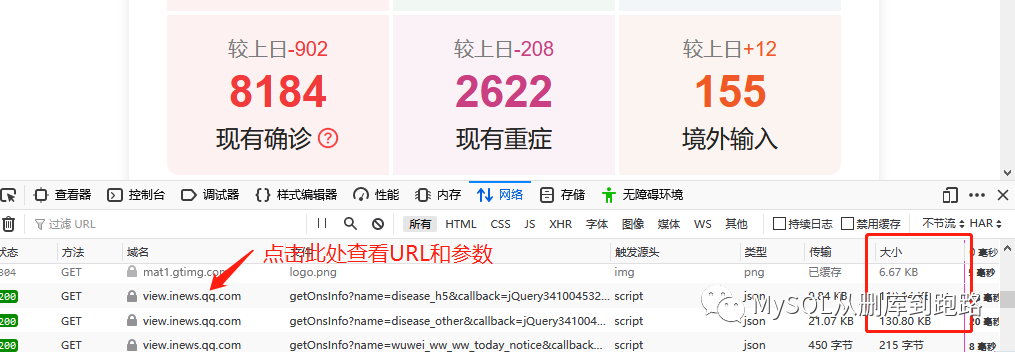
这里会出现很多网络传输记录,观察最右侧红框“大小”那列,这列表示这个http请求传输的数据量大小,动态加载的数据一般数据量会比其它页面元素的传输大,119kb相比其它按字节计算的算是很大的数据了,当然网页的装饰图片有的也很大,这个需要按照文件类型那列来甄别。
然后点击域名列对应那行,如下

可以在消息头中看见请求网址,这个就是url,点击参数可以看见url对应的参数
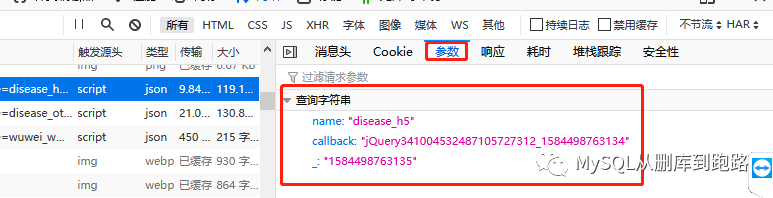
https://view.inews.qq.com/g2/getOnsInfo?name=disease_h6&callback=jQuery341004532487105727312_1584498763134&_=1584498763135
可以看到url的尾部?后面已经把参数写上了。
我们如果使用带参数的URL,那么就
request=urllib2.Request(url),不加data参数。
如果使用request=urllib2.Request(url,data = data)
那么url="https://view.inews.qq.com/g2/getOnsInfo"
formdata = {'name': 'disease_h6',
'callback': '',
'_': 当前时间戳
}
name是disease_h6,callback是页面回调函数,我们不需要有回调动作,所以设置为空,_对应的是时间戳(Python很容易获得时间戳的),因为查询肺炎患者数量和时间是紧密相关的。
如果都写在一个url中是下面形式的
url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h6&callback=&_=%d'%int(stamp*1000)
按照这个思路就可以获得疫情数据了。两种方案任你选择。
找url和参数是一项需要耐心,需要一定的分析能力的,才能正确甄别url和参数的含义,进行正确的编程实现。参数是否可以空,是否可以硬编码写死,是否有特殊要求,其实是一个很考验经验的事情。
有的url很简单,返回一个.dat文件,里面直接就是json格式的数据,这种是最友好的了。有的需要你设置大量参数,才能获得,而且获得的是html格式的,需要解析才能提取数据。
关于不使用selenium插件如何抓取网页的动态加载数据问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3944234/blog/4469337



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



