这篇文章将为大家详细讲解有关Kafka Stream是什么意思,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
首先,KafkaStream相比于主流的Storm、SparkStreaming、Flink等,优势在于轻量级,不要要特别指定容器资源等。非常适合一些轻量级的ETL场景,比如在常用的ETL中,大部分轻量级的Filter、LookUp、WriteStorage等操作可以使用KafkaStreams进行。理想的架构是,KafkaStream这样的轻量级计算框架+Lamdba,就能做到安全按需使用的流计算模式。
Kafka Streams构建在Kafka上,建立在流处理的一系列重要功能基础之上,比如正确区分事件事件和处理时间,处理迟到数据以及高效的应用程序状态管理。
功能强大
高拓展性,弹性,容错
有状态和无状态处理
基于事件时间的Window,Join,Aggergations
轻量级
无需专门的集群
没有外部依赖
一个库,而不是框架
完全集成
100%的Kafka 版本兼容
易于集成到现有的应用程序
程序部署无需手工处理(这个指的应该是Kafka多分区机制对Kafka Streams多实例的自动匹配)
实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
更简单的流处理:Kafka Streams的设计目标为一个轻量级的库,就像Kafka的Producer和Consumer似得。可以轻松将Kafka Streams整合到自己的应用程序中。对应用程序的额外要求仅仅是打包和部署到应用程序所在集群罢了。
除了Apache Kafka之外没有任何其它外部依赖, 并且可以在任何Java应用程序中使用。不需要为流处理需求额外部署一个其它集群。
使用Kafka作为内部消息通讯存储介质,不需要重新加入其它外部组件来做消息通讯。Kafka Streams使用Kafka的分区水平拓展来对数据做有序高效的处理。这样同时兼顾了高性能,高扩展性,并使操作简便。不必了解和调整两个不同的消息传输层(数据在不同伸缩介质中间移动和流处理的独立消息处理层),同样,Kafka的性能和高可靠性方面的改进,都会使得Kafka Streams直接受益。
Kafka Streams能够更加无缝的集成到现有的开发、打包、部署和业务实践当中去。你可以自由地使用自己喜欢的工具,比如java 应用服务器,Puppet, Ansible,Mesos,Yarn,Docket, 甚至在一台手工运行你自己应用程序进行验证的机器上。
支持本地状态容错。这样就可以进行非常高效快速的包含状态的Join和Window 聚合操作。本地状态被保存在Kafka中,在机器故障的时候,其他机器可以自动恢复这些状态继续处理。
每次处理一条数据以实现低延时,这也是Kafka Streams和其他基于微批处理的流处理框架的不同。另外,KafkaStreams的API与Spark中的非常相似,有非常多相同意义的算子,但是目前版本对于scala支持还是有些问题,不过对于擅长Spark编程的人员来说,写一个Kafka流处理不需要额外进行太多的学习。
Stream是KafkaStream中最重要的概念,代表大小没有限制且不断更新的数据集,一个Stream是一个有序的,允许重复的不可变的数据集,被定义为一个容错的键值对。
一个流处理程序可以是任何继承了KafkaSteams库的程序,在实际使用中,也就是我们写的Java代码。
处理拓扑定义了由流处理应用程序进行数据处理的计算逻辑,一般情况下,我们可以通过 StreamsBuilder builder = new StreamsBuilder();StrinmBuilder会在类内部为我们创建一个处理拓扑,如果需要自定义处理拓扑,可以通过Low-level API或者通过Kafka Streams的DSL来构建拓扑。
流处理器用来处理拓扑中的各个节点,代表拓扑中的每个处理步骤,用来完成数据转换功能。一个流处理同一时间从上游接收一条输入数据,产生一个或多个输出记录到下个流处理器。Kafka有两种方法定义流处理器:
DSL API,也就是map,filter等算子。
Low-Level API,低级API,允许开发人员定义和连接处理器的状态存储器进行交换。
一些比如窗口函数的算子就是基于时间界限定义的。
事件时间:时间或者记录产生的时间,也就是时间在源头最初创建的时间
处理时间:流处理应用程序开始处理时间的时间点,即时间进入流处理系统的时间
摄取时间:数据记录由KafkaBroker保存到kafka topic对应分区的时间点,类似于时间时间,都是嵌入数据记录中的时间戳字段,不过摄取时间是KafkaBroker附加在目标Topic上的.
事件时间和摄取时间的选择是通过在Kafka(不是KafkaStreams)上进行配置实现的。从Kafka 0.10.X起,时间戳会被自动嵌入到Kafka的Message中,可以根据配置选择事件时间或者摄取时间。配置可以在broker或者topic中指定。Kafka Streams默认提供的时间抽取器会将这些嵌入的时间戳恢复原样。因此,应用程序的有效时间语义上依赖于这种嵌入时时间戳读取的配置。请参考:Developer Guide
如果每个消息处理都是彼此独立的,那么其就不需要状态,比如只需要进行消息转换,或者是筛选,那么流处理的拓扑也非常简单。如果能够保存状态,流处理可以应用在更多场景,可以进行Join、Group By或者Aggregate擦左,KafkaStreams DSL提供了很多这样的包含状态的DSL。
首先,流和表具有双重性,一位着一个流可以作为表,表也可以作为流。Kafka的Log compact功能就是利用了这种双重性。Kafka日志压缩的影响, 考虑KStream和KTable的另一种形式,如果一个KTable存储到Kafka的topic中,你就需要启用Kafka的日志压缩功能以节省空间。然而,这种方式在KStream的情况下是不安全的,因为,一旦开启日志压缩,Kafka就会删除比较旧的Key值,这样就会破坏数据的语义。以数据重放为例,你会突然得到一个值为3的alice,而不是4,因为以前的记录都被日志压缩功能删除了。因此,日志压缩在KTable中使用是安全的,但是在KStream中使用是错误的
表的简单形式就是一个KV对的集合。
Stream as table:流可以被认为是一张表,可以通过重建日志的方式变成一张真正的表。
Table as Stream:一个表可以被认为是流上一个时间点的快照,每行记录都代表该键的最新值。可以通过遍历表中的每个KV很容易形成一个真正的流。
只有KafkaStreams的DSL才有KSteam的概念。一个KSteam是一个事件流,每条时间记录代表了无限的包含数据的数据集的抽象,用表来解释流的概念,数据的记录始终被解释为Insert,只有追加,因为没有办法替换当前已经存在的相同的key的行数据。
只有KafkaSteams的DSL才有KTable的概念。一个KTable是一个changelog的更新日志流。每个数据记录代表一个更新的抽象。每个条记录都是该Key最后一个值的更新结果。KTable提供了通过key查找数据值的功能,该功能可以用在Join等功能上。
Join可以实现在Key上对应两个流的记录和并,产生新流。一个基于流上的Join通常是基于窗口的,否则所有数据都会被保存,记录就回无限增长。KafkaStreamsDSL支持不同的Join,比如KSteam之间的Join以及KStream和KTable之间的Join。
####(11)Aggregations 聚合操作,比如sum、count,需要一个输入流,并且以多个输入记录为单位组成单个记录并产生新流。流上的聚合必须基于敞口进行,负责数据和join一样会无限制增长。聚合输入可以是KStream或者KTable,但输出一定是KTable,使得KafkaStreams的输出结果会不断被更新,当数据乱序到达之后,数据也可以被即使更新,因为输出的是KTable,数据会被及时覆盖。
首先放一张架构图:
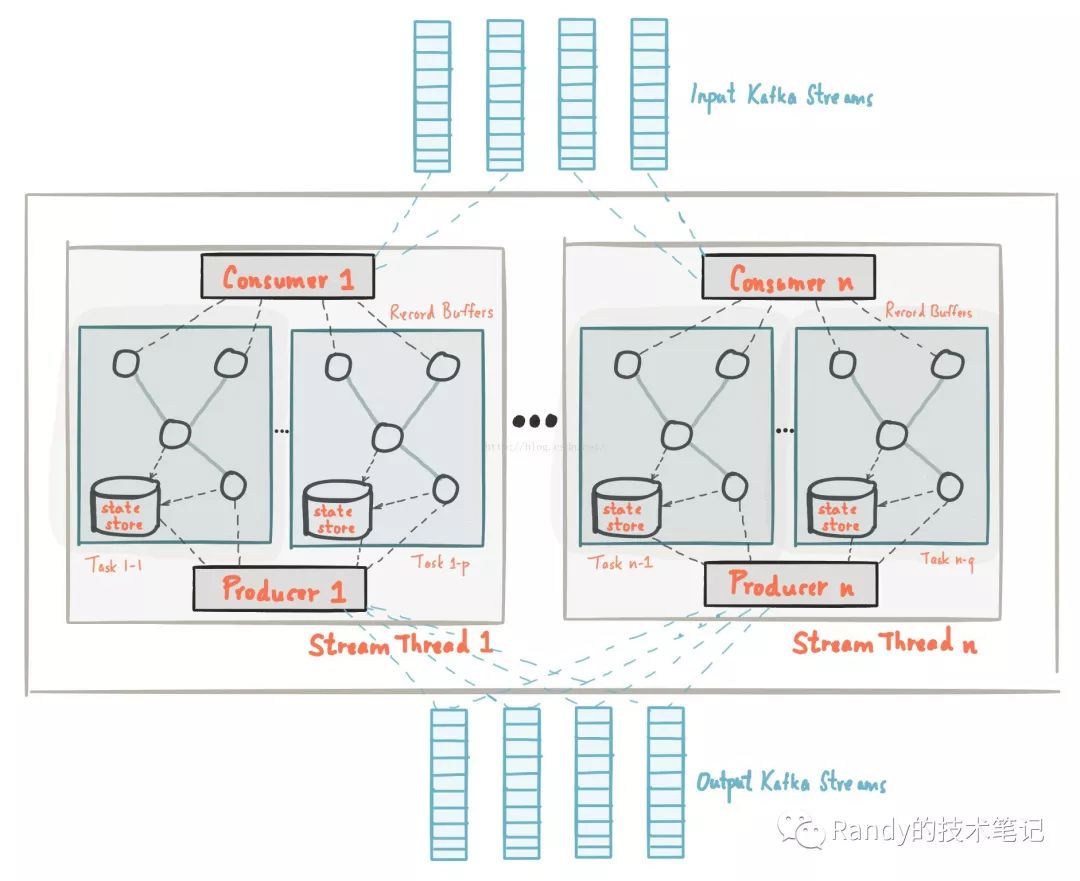
一个拓扑算子或者说简单拓扑定义了流处理应用的计算逻辑,也就是输入数据是如何转为输出数据的。一个拓扑算子是包含了用户流处理代码的逻辑抽象。在运行时,逻辑拓扑被实例化和复制在应用程序中并行执行。
每个Stream分区是kafka的一个分区中完整有序的数据记录;一个Stream数据记录映射中的数据记录直接来自于Kafka topic 数据的key值是Kafak和KafkaStreams的关键,决定了数据是如何被路由到特定分区的。在流任务执行的过程中,输入流的分区数决定了Task的数量,每个Task负责该分区的数据处理,kafkaStreams为每个分配到的分区分配了对应的缓冲区,基于缓冲区提供一次处理一条消息的时间处理机制。需要注意的是,KafkaStreams不是一个资源管理器,而是一个库,可以运行在任何流处理应用程序中,应用程序的多个实例可以运行在相同的机器或者是被资源管理器分发到不同的节点上运行;分配给该Task的分区永远不会改变,如果一个示例故障了,任务会被重新分配并在其他实例上启动,并从相同分区继续消费数据。
开发人员可以配置每个应用程序中的并行处理的线程数,每个线程与他们的拓扑算子独立执行一个或者多个任务。比如一个线程中可以执行2个Task,这两个Task对应Topic1的两个分区,也可以同时处理Topic2的两个分区,但是同一个Topic的不同分区必须使用不同的Task进行处理。
Kafka提供的状态存储,可以在流处理应用程序中保存和查询数据。每个Task都内置了一个或多个状态存储空间,可以通过API来保存或查询。这些状态存储空间是RocksDB数据库,一个基于内存的HashMap或者其他更方便的数据结构。并且kafkaStreams基于本地状态提供了容错和自动恢复能力。
因为Kafka本身分区就是高可用可复制的,所以当流保存到Kafka的时候也是高可用的,即使流处理失败了也没有关系,KafkaStreams会在其他实例中重启对应Task,利用了KafkaConsumer的失败处理功能。而本地数据存储可靠性依赖于更新日志,为每个状态Kafkatopic保存一个可复制的changelog。changelog在本地存储使用分区划分,每个task都有自己的专用分区,如果一个task失败了,kafka将会在其他实例上重启并使用该topic上的changelog来更新task 的最新状态。changelog的topic如果开启kafka的日志压缩永能,九数据就会被安全清除,放置changelog无限增长。
Kafka实现了至少一次的消息处理机制,即使发生鼓掌也不会有数据丢失和没有处理,但是部分数据可能被处理多次。但是有一些非幂等操作,比如计数,在at-least-once可能会出现计算结果错误,KafkaStreams将在以后的版本中支持exactly-once的语义处理。
KafkaStreams通过同步调节所有输入流的消息记录上呃时间戳来进行流控,KafkaStreams默认提供了event-time的处理语义。
关于“Kafka Stream是什么意思”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/264914/blog/4456013



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



