本篇内容主要讲解“怎么用requests爬取漂亮照片”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“怎么用requests爬取漂亮照片”吧!
selenium是什么?
selenium自动化浏览器。就是这样!你如何运用这种力量完全取决于你自己。它主要用于自动化web应用程序以进行测试,但当然不限于此。无聊的基于web的管理任务也可以(也应该)自动化。
一些大型浏览器厂商已经(或正在)采取措施使Selenium成为其浏览器的本地部分,这些厂商支持Selenium。它也是无数其他浏览器自动化工具、api和框架的核心技术。
可以说selenium的本职工作并不是用来爬虫的,而是用于自动化Web应用程序的测试目的。所以用selenium来爬知乎上面的图其实是一种比较剑走偏锋的做法,这也解释为了为什么爬取量不是很乐观。
什么是Requests
来看看 Requests的文档:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
从这个幽默的介绍中,不难看出来Requests作者对于Requests非常有自信,我们用Requests爬知乎图片也刚好验证了这一点。
我们按照惯例简要说明一下爬虫步骤:

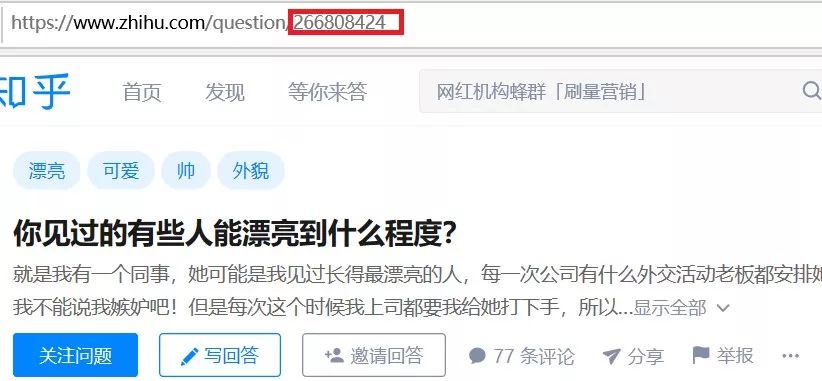
如上图所示,我们需要的id就在红色框线里面。
核心代码:
get_url = 'https://www.zhihu.com/api/v4/questions/'+id+'/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics&limit=5&offset='+str(offset)+'&sort_by=default' header = { 'User-Agent': "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:34.0) Gecko/20100101 Firefox/34.0", 'Host': "www.zhihu.com", } r = requests.get(get_url, verify=False, headers=header) content = r.content.decode("utf-8") txt = json.loads(content)我们把网页信息解析到了txt中。
核心代码:
imgUrls = re.findall(r'data-original="([^"]+)"', str(txt))imgUrls = list(set(imgUrls))for imgUrl in imgUrls: try: splitPath = imgUrl.split('.') fTail = splitPath.pop() print(fTail) if len(fTail) > 3 : fTail = 'jpg' fileName = path +"/" + str(number) + "."+fTail img_data = urllib.request.urlopen(imgUrl).read()在获取txt后,我们需要用正则表达式匹配图片的地址,然后根据这个地址下载图片到本地。
到此,相信大家对“怎么用requests爬取漂亮照片”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4599719/blog/4461871



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



