今天就跟大家聊聊有关KEGG数据库病毒基因组的下载是怎样的,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
KEGG数据库蛋白序列数据的下载方法中存在两个问题:
1. 在KEGG数据库中病毒物种的命名并非像细胞生物一样为小写字母的缩写,因此在批量下载时遇到病毒会报错而无法下载,如下所示:
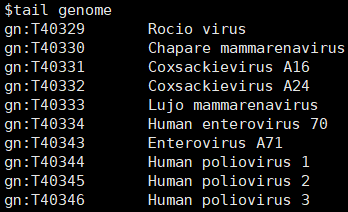
2. 在根据蛋白序列id下载序列时会出现下载不完整的情况,这样在最终的合并时就会出现错误。
现针对以上两个问题提供解决方案。首先针对第一个问题,在KEGG数据库中病毒物种的名称的确没有标准缩写,但是所有病毒可以用缩写“vg”来表示(也即viral genome的缩写),下载方法如下所示:
wget -c http://rest.kegg.jp/list/vg
这样我们就获得了所有病毒的蛋白列表,如下所示:
vg:23892186 CP, DU23_s2gp1; Arhar cryptic virus-II; Coat Proteinvg:24271495 LAT, HHV2s01; Human alphaherpesvirus 2; LATvg:1487286 RL1, HHV2p77; Human alphaherpesvirus 2; neurovirulence protein ICP34.5vg:1487288 RL2, HHV2p76; Human alphaherpesvirus 2; ubiquitin E3 ligase ICP0vg:1487292 UL1, HHV2p75; Human alphaherpesvirus 2; envelope glycoprotein Lvg:1487303 UL2, HHV2p74; Human alphaherpesvirus 2; uracil-DNA glycosylasevg:24271453 UL3, HHV2p73; Human alphaherpesvirus 2; nuclear protein UL3vg:1487326 UL4, HHV2p71; Human alphaherpesvirus 2; nuclear protein UL4vg:1487338 UL5, HHV2p72; Human alphaherpesvirus 2; helicase-primase helicase subunitvg:1487346 UL6, HHV2p70; Human alphaherpesvirus 2; capsid portal protein其中左边第一列即为病毒蛋白序列的id,可以遍历id来获得序列。
针对第二个问题,这是wget命令的一个缺陷,我们可以通过判断每个文件的最后是否为换行符\n来判断文件是否下载完整,如下所示:
tail -n1 <download_file> |wc -l如果文件下载完整,最后一个字符为换行符,那么结果为1,否则为0,如下所示:
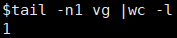
看完上述内容,你们对KEGG数据库病毒基因组的下载是怎样的有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云数据库 MySQL」免部署即开即用,比自行安装部署数据库高出1倍以上的性能,双节点冗余防止单节点故障,数据自动定期备份随时恢复。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4599872/blog/4472997



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



