这篇文章主要介绍“Python爬虫怎么实现下载网易云音乐”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“Python爬虫怎么实现下载网易云音乐”文章能帮助大家解决问题。
Selenium(配置方法参照:Selenium配置)
Chrome浏览器(其它的也可以,需要进行相应的修改)
解析
以前抓取过网易云网页的朋友可能都清楚网易云有反爬虫策略的,post时要对部分信息的参数完成加密函数的模拟。为了方便,入门新手也可以了解,直接采用Selenium来模拟登录,之后用接口来下载音乐和歌词。
实验步骤:
通过歌手id得到当前歌手的热门歌曲信息,歌名与网址,并且存储到CSV文件里面;
载入csv文件,通过音乐链接,获取歌曲ID,之后借助相应的接口,下载歌曲和歌词;
将歌曲和歌词存储到本地。
Python实现
这里针对几个主要的函数来说明…
抓取歌手信息
通过Selenium就不用看对页面的请求了,能直接从页面源代码中提取对应的数据,查看歌手网页源代码能够看到在iframe框架里有我们需要的信息,因此,要先切换到iframe:
browser.switch_to.frame('contentFrame')
接着看下去,在id=”hotsong-list”标签中能看到需要的歌名以及链接,然后每一行对应的是一个tr标签。因此先取得全部的tr内容,然后遍历单个tr。
data = browser.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
注意:前一个是find_element,后一个是find_elements,后者返回一个列表。
然后就是解析单个tr标签的内容,得到歌名与链接,可以发现两者在class=”txt”标签中,而且链接是href属性,名字是title属性,能直接通过get_attribute()函数获取。
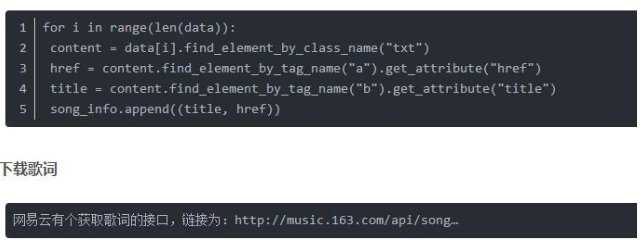
链接中的数字就是歌曲的id,因此我们得到歌曲id后,能够同时从该链接下载歌词,歌词文件是json格式,因此我们还要用到json包。
并且同时获取的歌词中,每行有一个时间轴,还要用正则表达式来去除,完整代码如下:

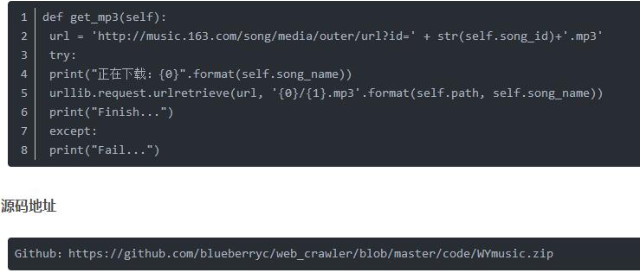
链接中的数字为歌曲的id,可以直接根据歌曲的id来下载音频文件。完整代码如下:
关于“Python爬虫怎么实现下载网易云音乐”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3711840/blog/4468433



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



