如何利用scrapy进行八千万用户数据爬取与优化,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
最近准备把数据分析这块补一下,加上一直在听喜马拉雅的直播,有一个比较喜欢的主播,突然萌生了爬取喜马拉雅所有主播信息以及打赏信息,来找一找喜马拉雅上比较火的主播和有钱的大哥,看看这些有钱人是怎么挥霍的。
打开喜马拉雅的主播页面,查看人气主播
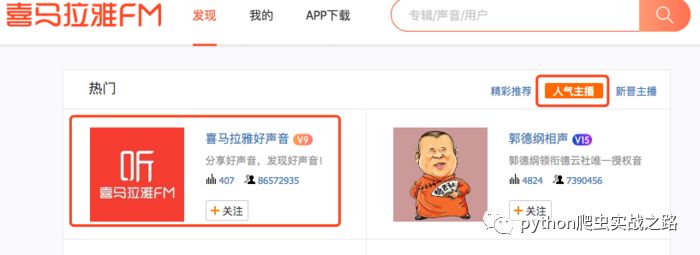
第一个是喜马拉雅好声音,官方的账号,很多人的喜马拉雅账号应该会默认关注这个。我们看到粉丝关注数有八千多万,实际的喜马拉雅用户量肯定超过这个数值,我们暂且估计可爬取数量为一亿,主播页面只显示五50页,每页20个用户,我的思路是爬取显示的主播信息,进入主播主页
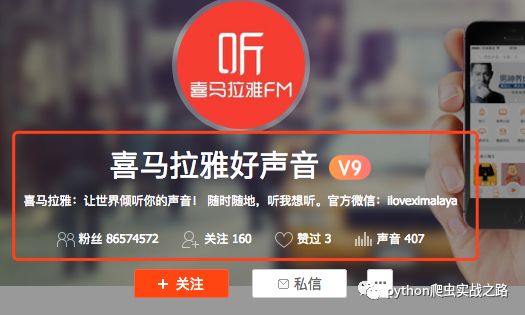
爬取相关信息,然后查看粉丝信息

粉丝页只显示10页,每页10个用户。虽然看起来不多,但是我们可以进行扩展,每个粉丝点进去后又是一个用户主页,又可以爬取他的粉丝信息。就这样一直进行扩展,然后使用去重处理,过滤已经爬取过的用户数据。
我们要爬取的数据:用户名、简介、粉丝数、关注数、声音、专辑数。
另外还有赞赏信息需要通过APP抓取,我们先抓用户信息吧。
这么大量的数据爬取,优秀的框架是必不可少的,我们就使用大名鼎鼎的scrapy框架为基础来进行爬取。另外分布式爬取也是必不可少,虽然我没有那么多机器去做,但是我琢磨了一下,百度云、阿里云、腾讯云、华为云等一系列云服务器新用户都有几天试用期,这集群机器不就有了吗?嘿嘿

数据库我们使用MongoDB,因为我们的数据并不要求多精确。Redis肯定是必选了。但是作为内存数据库,占用内存的大小这就是我们必须要考虑的。我们的去重过滤都是放在redis中的,所以必须对齐进行优化。具体原因请看:
我先在自己机器上抓取了部分数据,查看redis中的请求列表和去重列表
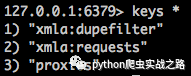

从请求列表中的数据量可以知道下载还是比较慢的,这就是为什么我们要用分布式进行爬取了。然后再看去重数据,七十五万条。不大的数据量,但是看下内存占用情况。


执行删除语句flushall后,再查看内存使用情况
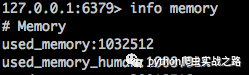

在我8G内存的Mac上占用260M的内存可以忍受,但是在我那可怜的只有1G的云服务器上,卡到我都快链接不上了,我们可是以八千万数据为目标的,实际才爬取了二十多万条有效数据,去重记录都七十多万了,如果到了一亿条数据,以目前的情况来看,卡爆服务器也到不了。
本来还有一个xmla:items结构,存储我们的抓取数据,我把它提取到了MongoDB当中。xmla:requests中是待爬取请求列表,我们爬取下载的时候这个数据量还是会逐渐减少的,至少不会无限增大。但是这个xmla:dupefilter中存取的是去重数据,每一次请求都会记录下来,所以这个数据只会随着我们的爬取一直增大。那么这就是我们要进行优化的重点。
下面我们来规划一下下来要做的事情,按步骤来:
docker环境安装部署
redis集群配置操作
用户数据抓取流程分析
用户打赏信息抓取流程分析
使用BloomFilter修改scrapy-redis,减少过滤内存占用
反爬处理:IP代理池、User-Agent池
使用Gerapy和docker部署分布式环境
抓取数据清理,数据分析规划
看完上述内容,你们掌握如何利用scrapy进行八千万用户数据爬取与优化的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





