本篇内容介绍了“python过拟合实例分析”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
如下图便直观形象的展示出这种最严重的的过拟合情况:
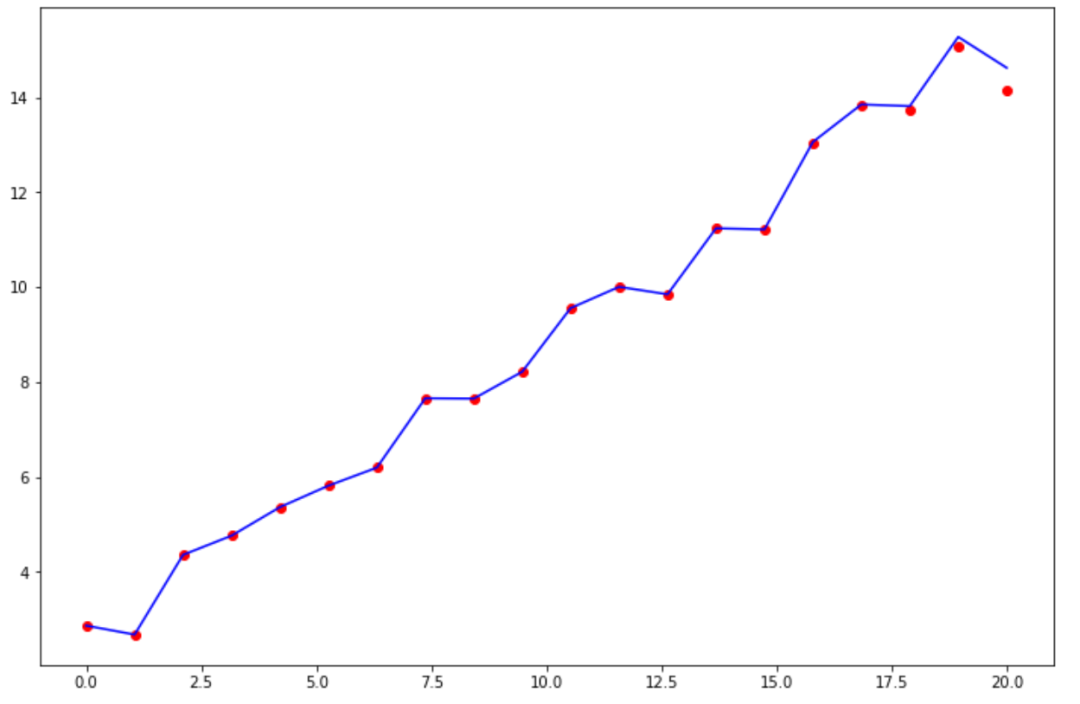
模型几乎拟合所有点,也就是在训练集上的准确度接近 100%,这类模型有什么特点呢?不妨看看这个模型的参数:
1.24700471e-13, -2.35752755e-11, 2.06759733e-09, -1.11665116e-07,
4.15722794e-06, -1.13161697e-04, 2.33087852e-03, -3.70886530e-02,
4.61321531e-01, -4.50943817e+00, 3.46373724e+01, -2.07949995e+02,
9.65158102e+02, -3.40164962e+03, 8.85765503e+03, -1.63366853e+04,
1.99303609e+04, -1.41930185e+04, 4.37094529e+03, 2.87198980e+00一共有 20 个,正好等于需要拟合的点数。
以上图形是用拉格朗日插值方法拟合出来的,借助 scipy 包完成插值,代码如下所示。
数据准备阶段:
from scipy.interpolate import lagrange
import numpy as np
import matplotlib.pyplot as plt
#使用样本个数
n = 20
# seed 保证每次都生成一个固定随机数
np.random.seed(2)
eps = np.random.rand(n) * 2
# 构造样本数据
x = np.linspace(0, 20, n)
y = np.linspace(2, 14, n) + eps调用拉格朗日插值,得到插值函数 p,然后输入待插值点 x, 完成插值得到插值点(xx,yy)
# 调用拉格朗日插值,得到插值函数p
p = lagrange(x, y)
xx = x
yy = p(xx)拉格朗日插值得到一个多项式模型,参数个数等于样本个数。
以上我们还原拟合所有样本点的一个方法。
机器学习中为了模型泛化能力更强,所以需要简化模型参数,换句话说对参数做正则化处理,这也符合奥卡姆剃刀定律,即简单有效原理。
常用的L1 正则会使参数稀疏化,它会将其中一些参数权重归 0. 当然就今天将要拟合的数据点而言,直接简化模型参数为 2个,拟合效果就不会差。
选用 sklearn 最最简单的线型回归模型:
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(x.reshape(len(x),-1),y)
# 得到2个参数值
reg.coef_,reg.intercept_
(array([0.62182096]), 2.644854261121125)再plot下拟合效果:
plt.figure(figsize=(12,8))
plt.scatter(x, y, color="r")
# 拉格朗日插值复杂模型
plt.plot(xx, yy, color="b",label='lagrange')
# 线型回归极简模型
plt.plot(xx,xx*reg.coef_+reg.intercept_,color='green',label='linear_model')
plt.show()
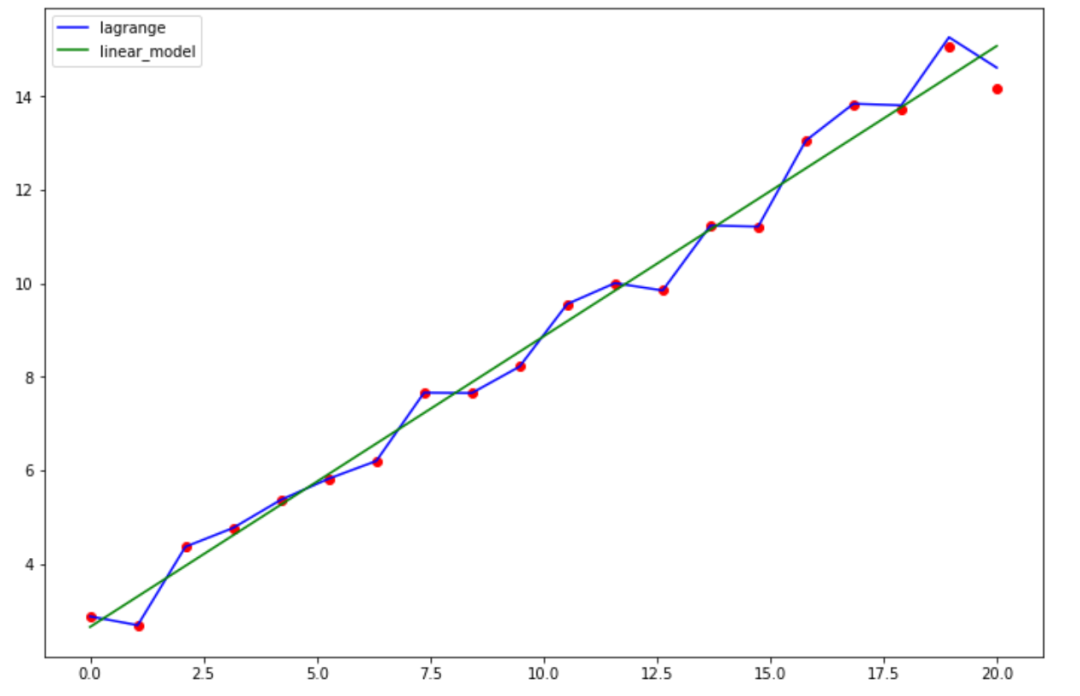
“python过拟合实例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





