这篇文章将为大家详细讲解有关python如何爬取bilibili的弹幕制作词云,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
需要知道cid,可以F12,F5刷新,找cid,找到之后拼接url
也可以写代码,解析response获取cid,然后再拼接
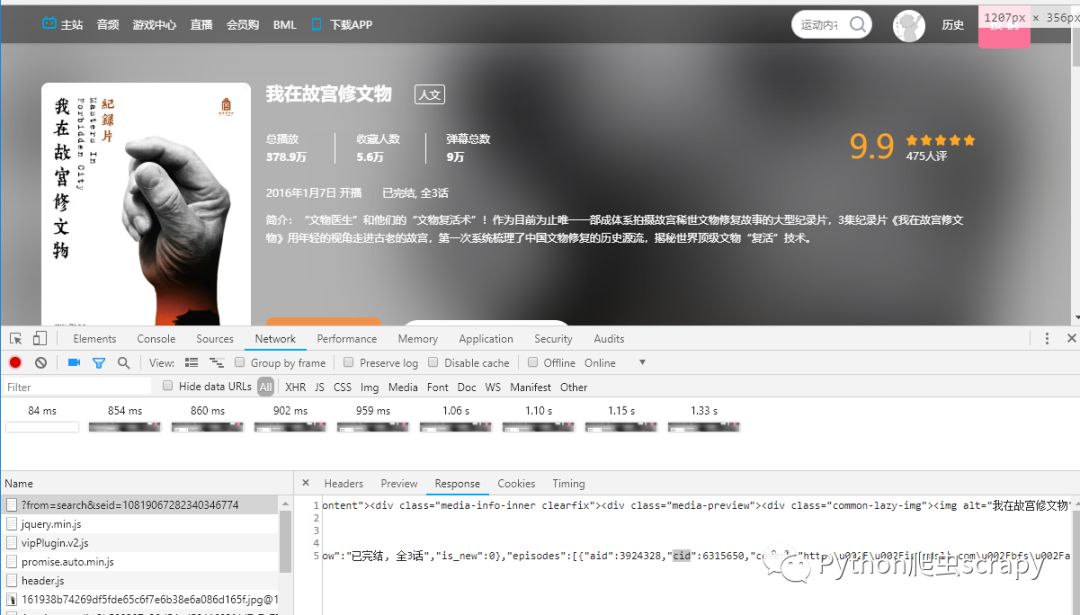

使用requests或者urllib都可以
我是用requests,请求该链接获取到xml文件
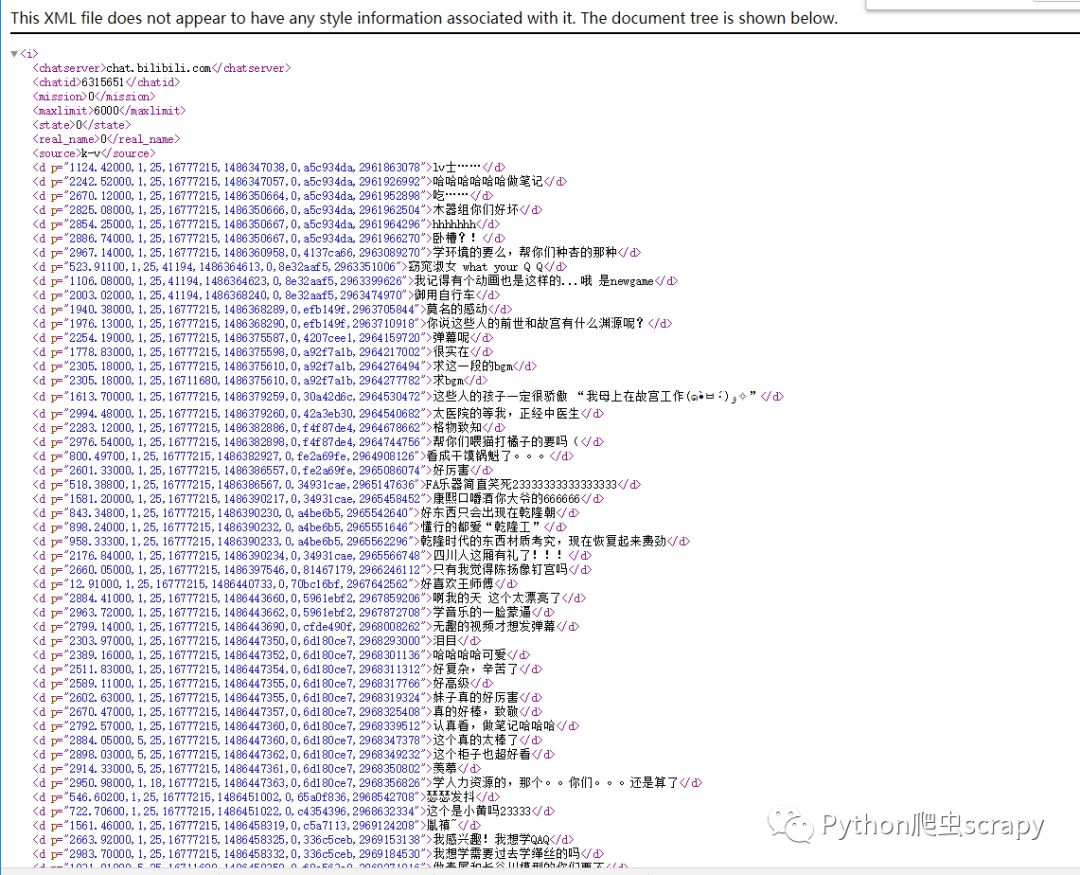
代码:获取xml
def get_data(): res = requests.get('http://comment.bilibili.com/6315651.xml') res.encoding = 'utf8' with open('gugongdanmu.xml', 'a', encoding='utf8') as f: f.writelines(res.text)解析xml,
def analyze_xml(): f1 = open("gugongdanmu.xml", "r", encoding='utf8') f2 = open("tanmu2.txt", "w", encoding='utf8') count = 0 # 正则匹配解决xml的多余的字符 dr = re.compile(r'<[^>]+>', re.S) while 1: line = f1.readline() if not line: break pass # 匹配到之后用空代替 dd = dr.sub('', line) # dd = re.findall(dr, line) count = count+1 f2.writelines(dd) print(count)去掉无用的字符和数字,找出所有的汉字
def analyze_hanzi(): f1 = open("tanmu2.txt", "r", encoding='utf8') f2 = open("tanmu3.txt", "w", encoding='utf8') count = 0 # dr = re.compile(r'<[^>]+>',re.S) # 所有的汉字[一-龥] dr = re.compile(r'[一-龥]+',re.S) while 1: line = f1.readline() if not line: break pass # 找出无用的符号和数字 # dd = dr.sub('',line) dd = re.findall(dr, line) count = count+1 f2.writelines(dd) print(count) # pattern = re.compile(r'[一-龥]+')使用jieba分词,生成词云
def show_sign(): content = read_txt_file() segment = jieba.lcut(content) words_df = pd.DataFrame({'segment': segment}) stopwords = pd.read_csv("stopwords.txt", index_col=False, quoting=3, sep=" ", names=['stopword'], encoding='utf-8') words_df = words_df[~words_df.segment.isin(stopwords.stopword)] print(words_df) print('-------------------------------') words_stat = words_df.groupby(by=['segment'])['segment'].agg(numpy.size) words_stat = words_stat.to_frame() words_stat.columns = ['计数'] words_stat = words_stat.reset_index().sort_values(by=["计数"], ascending=False) # 设置词云属性 color_mask = imread('ciyun.png') wordcloud = WordCloud(font_path="simhei.ttf", # 设置字体可以显示中文 background_color="white", # 背景颜色 max_words=1000, # 词云显示的最大词数 mask=color_mask, # 设置背景图片 max_font_size=100, # 字体最大值 random_state=42, width=1000, height=860, margin=2, # 设置图片默认的大小,但是如果使用背景图片的话, # 那么保存的图片大小将会按照其大小保存,margin为词语边缘距离 ) # 生成词云, 可以用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数 word_frequence = {x[0]: x[1] for x in words_stat.head(1000).values} print(word_frequence) # for key,value in word_frequence: # write_txt_file(word_frequence) word_frequence_dict = {} for key in word_frequence: word_frequence_dict[key] = word_frequence[key] wordcloud.generate_from_frequencies(word_frequence_dict) # 从背景图片生成颜色值 image_colors = ImageColorGenerator(color_mask) # 重新上色 wordcloud.recolor(color_func=image_colors) # 保存图片 wordcloud.to_file('output.png') plt.imshow(wordcloud) plt.axis("off") plt.show()运行程序,结果:


统计的结果
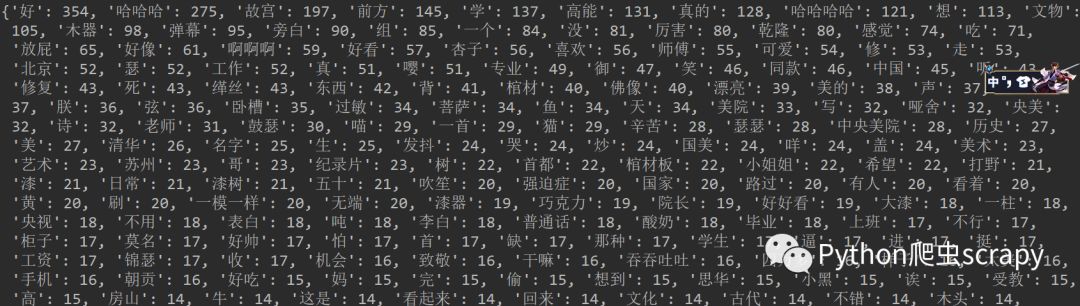
完成!
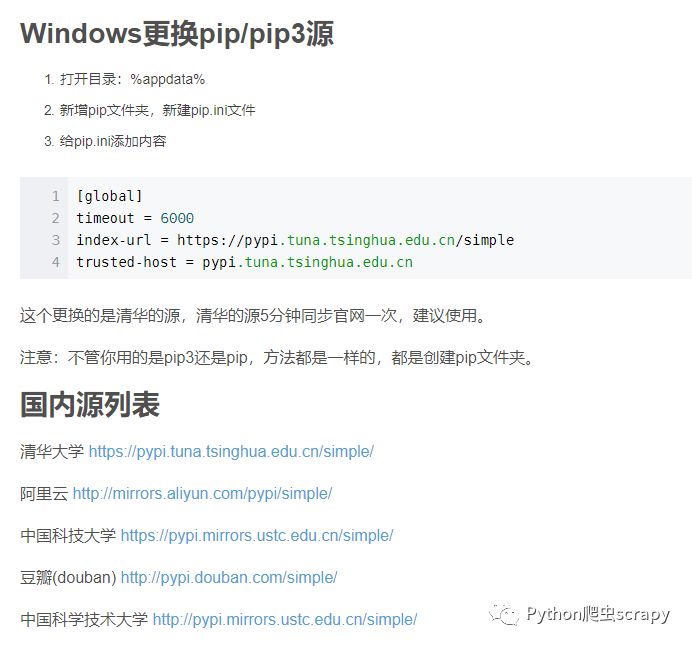
pip的换源,原来的太慢,然后将你自己没有库装上
关于“python如何爬取bilibili的弹幕制作词云”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4080705/blog/4419390



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



