这篇文章将为大家详细讲解有关使用python爬虫怎么结合唧唧对Bilibili进行爬取,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
1.依赖库
requestsl
xml
2.代码
相关讲解已在注释标注。
'''
author:Ericam
description: 用于爬取b站视频链接
'''
import requests
import re
from lxml import etree
import time
'''
该函数用于解析爬取的网页。
提取出网页里视频的url链接以及对应的视频名。
'''
def getHref(url,page):
try:
req = requests.get(url,timeout=5,headers=headers)
html = req.text
data = etree.HTML(html)
'''
page-1://*[@id="all-list"]/div[1]/div[2]/ul[@class="video-list"]/li
other://*[@id="all-list"]/div[1]/ul[@class="video-list"]/li
'''
pattern = '//*[@id="all-list"]/div[1]/div[2]/ul[contains(@class,"video-list")]/li' if page == 1 else '//*[@id="all-list"]/div[1]/ul[contains(@class,"video-list")]/li'
vurlList = data.xpath(pattern)
for li in vurlList:
vurl = li.xpath(".//a/attribute::href")[0]
title = li.xpath(".//a/attribute::title")[0]
yield vurl,title
except:
print('第%d页爬取失败' % page)
print('Unfortunitely -- An Unknow Error Happened, Please wait 3 seconds')
time.sleep(3)
'''
该函数用于正则提取,将url内的BV号提取出来
'''
def getBv(href):
pattern = re.compile('(BV.*?)\?')
data = re.search(pattern,href)
if data == None:
return ''
return data.group(1)
if __name__ == "__main__":
#头部伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
hrefList = []
titleList = []
#需要爬取多少页,自行进行修改,本代码测试1~2页
for i in range(1,3):
url = "https://search.bilibili.com/all?keyword=歪嘴战神&page={0}".format(i) #修改keyword后的关键字即可
l = getHref(url,i)
for vurl,title in l:
hrefList.append(vurl)
titleList.append(title)
print("第{0}页爬取结束".format(i))
time.sleep(2)
print("---------------------------开始截取BV号-----------------------------")
for i in range(len(hrefList)):
hrefList[i] = getBv(hrefList[i])
with open("bv.txt",'w',encoding='utf-8') as f:
for i in range(len(hrefList)):
f.write(hrefList[i]+"\t"+titleList[i]+"\n")
print("爬取结束")3.爬取结果

给出唧唧的链接,唧唧,很好用的小工具。
我们只需要将刚才爬取好的链接放在一边,不断复制BV号,然后唧唧进行下载即可。
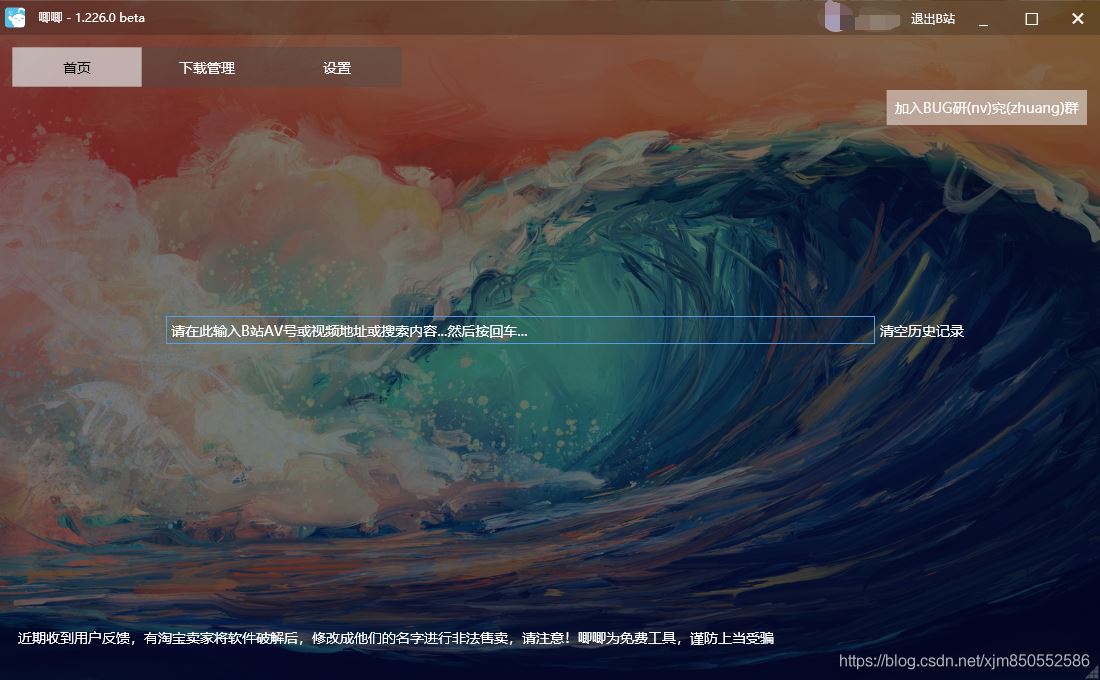
唧唧下载好的视频如下所示:

为什么需要将它们进行改名呢,因为如果当视频数量越来越多时,比如几千几万时,通过名字便会越来越难以管理,同时也难以进行去重,很大概率会不断下载重复的视频。
在B站,BV号便是每个视频的“身份证”(主键),因此用其进行视频命名可以方便日后管理,同时也方便进行去重。
代码
'''
author:Ericam
description: 用于将下载下来的b站视频重命名,命名格式为bv号
'''
import os
import difflib
if __name__ == '__main__':
bvpath = os.path.join("D:/","Coding","python","Python爬虫")
os.chdir(bvpath)
d = {}
'''
bvdownload.txt里存放bv号与title名
若之前爬虫爬取了几千个,而唧唧只下载了几百个,便可以将这些已下载的bv和title复制到
bvdownload.txt中,将已下载的视频进行改名
'''
with open("bvdownload.txt",'r',encoding='utf-8')as f:
lines = f.readlines()
for val in lines:
val = val.strip("\n")
data = val.split("\t")
bv = data[0]
title = data[1]
d[title] = bv
#视频存放位置
path = 'F:/bilibili视频/'
os.chdir(path)
videoList = os.listdir()
#开始进行模糊匹配
for key in d:
video = difflib.get_close_matches(key,videoList,1, cutoff=0.3)
if len(video) == 0:
continue
video = video[0]
#检查视频是否已存在,若存在则删除视频
if os.path.isfile(d[key]+".mp4") and os.path.isfile(video):
os.remove(video)
else:
if os.path.isfile(video):
os.rename(video,d[key]+".mp4")
print("重命名完成!")结果演示
重命名完成的视频列表如下:

关于使用python爬虫怎么结合唧唧对Bilibili进行爬取就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



