本篇文章为大家展示了如何用R语言和Python实现因子变量与分类重编码,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
今天介绍数据类型中因子变量的运用在R语言和Python中的实现。
因子变量是数据结构中用于描述分类事物的一类重要变量。其在现实生活中对应着大量具有实际意义的分类事物。
比如年龄段、性别、职位、爱好,星座等。
之所以给其单独列出一个篇幅进行讲解,除了其在数据结构中的特殊地位之外,在数据可视化和数据分析与建模过程中,因子变量往往也承担中描述某一事物重要维度特征的作用,其意义非同寻常,无论是在数据处理过程中还是后期的分析与建模,都不容忽视。
通常意义上,按照其所描述的维度实际意义,因子变量一般又可细分为无序因子(类别之间没有特定顺序,水平相等)和有序因子(类别中间存在某种约定俗成的顺序,如年龄段、职称、学历、体重等)。
在统计学中对变量进行了如下四类划分:定类变量、定序变量、定距变量、定比变量。而其中的定类和定比变量就对应着我们今天将要讲解的因子变量(无序因子和有序因子变量)。
因子变量从信息含量上来看,其要比单纯的定性变量(文本变量)所包含的描述信息多一些,但是又比数值型变量(定距变量和定比变量)所表述的信息含量少一些。
因而原则上来讲,数值型变量可以转换为因子变量,因子变量可以转换为文本型变量,但是以上顺序却是不可逆的(信息含量多的变量可以放弃信息量,转换为信息含量较少的变量类型,但是信息含量较少的变量却无法增加信息含量)。
在R语言中,通常使用factor直接生成因子变量,我们仅需一个向量(原则上可以是文本型、也可以是数字型,但是通常从实际意义上来说,被转换的应该是一个含有多类别的类别型文本变量)。
factor(x, levels,labels=levels,ordered=)
以上参数中,x即是我们将要转换的变量,levels是将要设定的因子水平(可选参数,省略则自动以向量中的不重复对象为因子水平),labels作为因子标签(可选参数,与前述因子水平对应,若设置,则打印时显示的是对应因子标签,省略则同因子水平一样,使用向量中不重复值【即类别】作为标签),ordered是逻辑参数,设定是否对因子水平排序。
vector<-rep(LETTERS[1:5],6);print(vector);plyr::count(vector)
myfactor<-(factor(vector,levels=c("E","D","C","B","A"),labels=c("EEE","DDD","CCC","BBB","AAA"),ordered=TRUE)

通常来说,factor函数中,levels一般不用设置,函数会自动判断向量内有几个水平,但是倘若要生成有序因子的话,默认会根据字母顺序排列,如果自然顺序与目标有序因子顺序不一致,则一定要指定levels,labels则视具体需求而定,如果本身就是文本类别的话,一般无需设定标签。
如果是问卷类数据,而且编码为数值,则一定要通过labels标签的设定来还原每一个编码的真实意义。
factor(vector,labels=c("AAA","BBB","CCC","DDD","EEE"),ordered=TRUE)
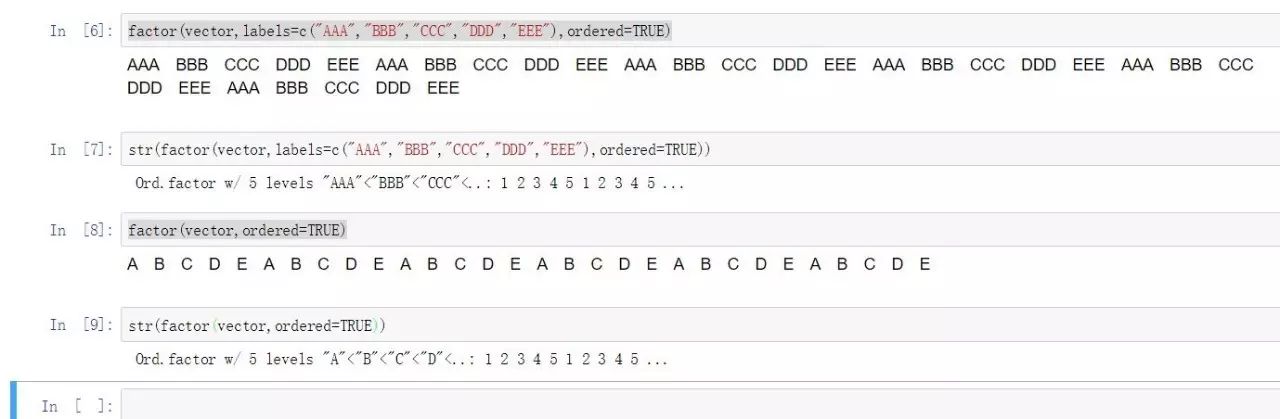
因子变量与文本变量数值变量之间的互转则通过as.character()或者as.numeric()函数来实现。
library(dplyr)
as.character(as.factor(1:10))%>%str()
as.numeric(as.factor(1:10))%>%str()
R语言中的因子变量重编码
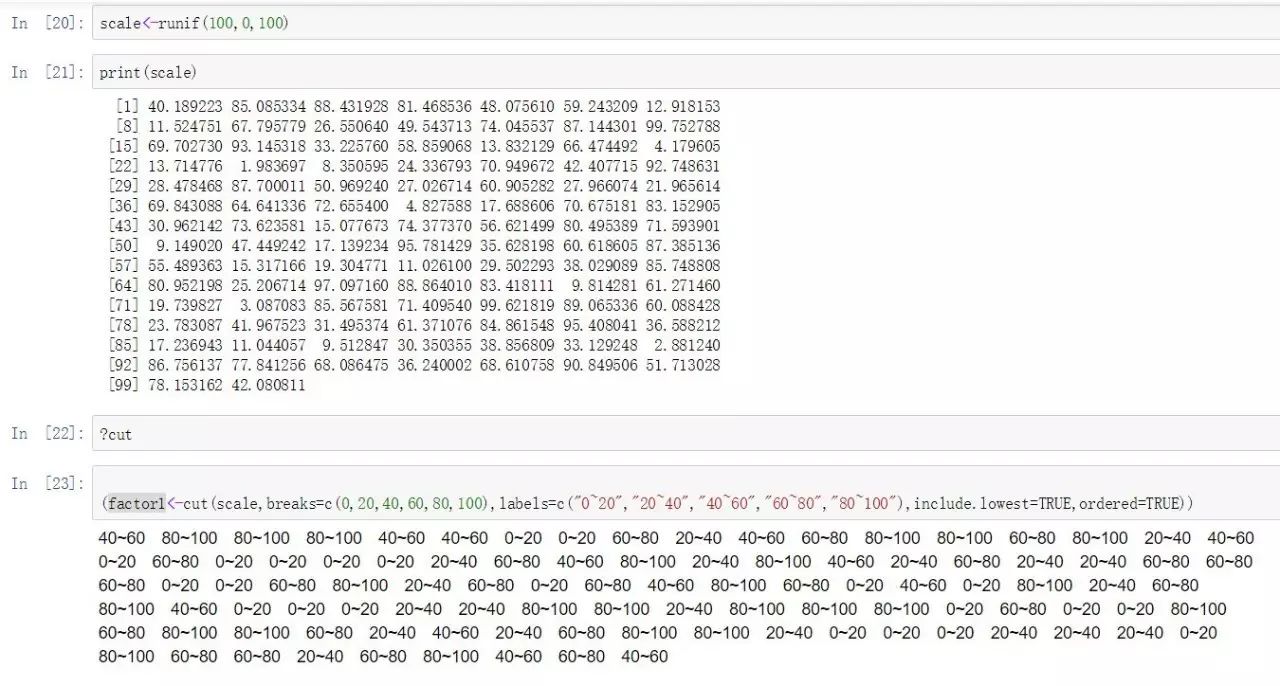
如果你有一个度量指标,需要将其转换为分段的因子变量,则可以通过cut函数来实现这种转换。
scale<-runif(100,0,100)
cut(x,breaks,labels=NULL,include.lowest=FALSE,right=TRUE,ordered=)
cut函数参数如上,接受一个数值型向量,breaks接受一个数值向量(标识分割点)或者单个数值(分割 数目)。
right是逻辑参数,设定分割带是左开右闭或者左闭右开。(默认左开右闭)。
include.lowest则根据right的设定,决定是否应该包含端点值(如果right为TRUE,左开右闭区间,则包含最小值,如果right为FALSE,左闭右开区间则包含最大值),默认为FALSE。
ordered则设定是否对因子水平进行排序。
(factor1<-cut(scale,breaks=c(0,20,40,60,80,100),labels=c("0~20","20~40","40~60","60~80","80~100"),include.lowest=TRUE,ordered=TRUE))
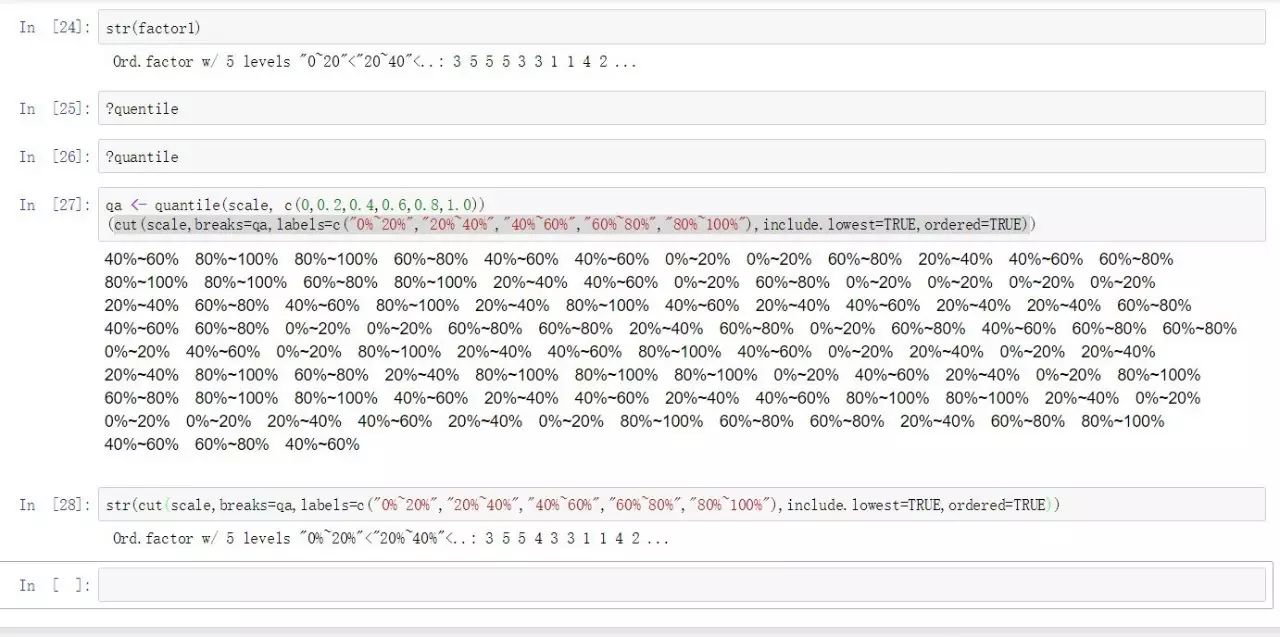
另一种分割场景是使用分位数函数进行分割,
qa <- quantile(scale, c(0,0.2,0.4,0.6,0.8,1.0))
(cut(scale,breaks=qa,labels=c("0%~20%","20%~40%","40%~60%","60%~80%","80%~100%"),include.lowest=TRUE,ordered=TRUE))
以上分割方法在是较为常用的因子变量转换方法,当然你可以使用if函数进行类似分割,但是相比较来讲,使用cut函数进行分割要高效很多。
Python
在Python中,Pandas库包含了处理因子变量的一整套完整语法函数。
import pandas as pd
import numpy as np
import string
在pandas中的官方在线文档中,给出了pandas因子变量的详细论述,并在适当位置与R语言进行了对比描述。
http://pandas.pydata.org/pandas-docs/stable/categorical.html#working-with-categories
当利用pandas生成序列时,可以在序列函数内的dtype参数设定因子变量类型。
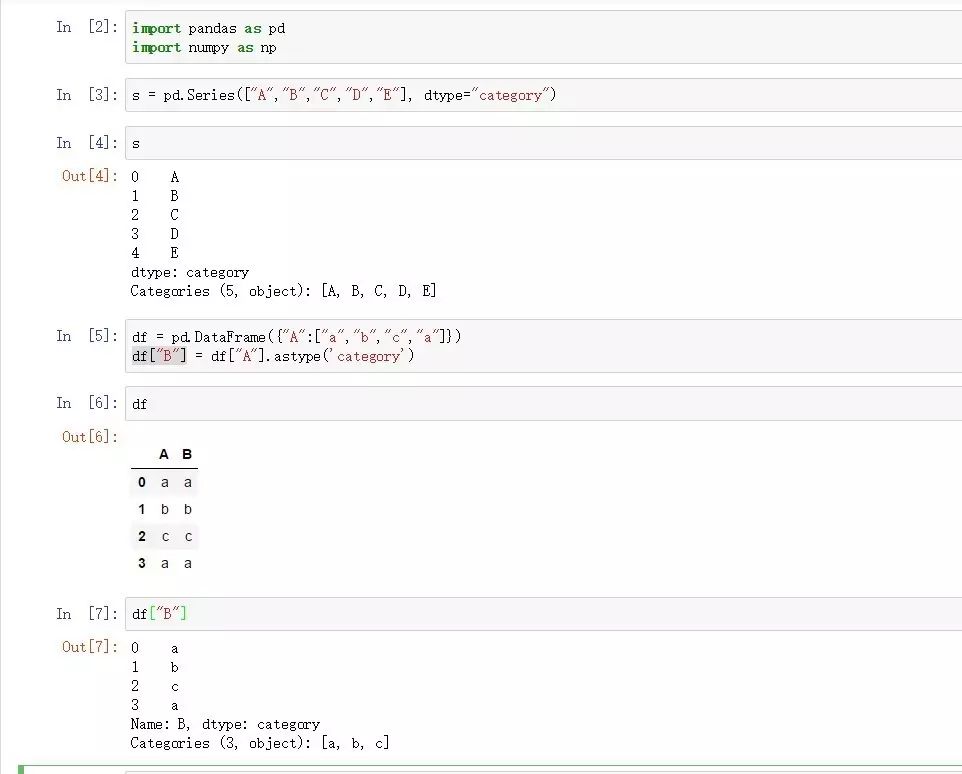
s = pd.Series(["A","B","C","D","E"], dtype="category")
生成数据框时,也可以直接生成因子变量。
df = pd.DataFrame({"A":["a","b","c","a"]})
df["B"] = df["A"].astype('category')
除了直接在生成序列或者数据框时生成因子变量之外,也可以通过一个特殊的函数pd.Categorical来完成在序列和数据框中创建因子变量。
s = pd.Series(pd.Categorical(["a","b","c","a"], categories=["a","b","c"],ordered=False))
df = pd.DataFrame({"A":["a","b","c","a"]})
df["B"] =pd.Series(pd.Categorical(["a","b","c","a"], categories=["a","b","c"],ordered=False))

因子顺序的添加可以通过设定序列或者数框框列的.astype来进行详细的操作。
s = pd.Series(["a","b","c","a"])
s_cat = s.astype("category", categories=["a","b","c"], ordered=True)
无论是序列中还是数据框中的因子变量生成之后,都可以通过以下属性查看其具体的类型、因子类别、以及是否含有顺序。
s_cat.dtypes
s_cat.cat.categories
s_cat.cat.ordered
一种比较迂回的方法是,先生成普通序列,然后通过设定序列类型完成因子变量的转化。而想要舍弃因子变量,还原成普通的文本序列,则同样只需再其astype中进行格式设定。
s = pd.Series(["a","b","c","a"])
s2 = s.astype('category',categories=["a","b","c"],ordered=True)
s2.astype(str)
最后讲一下,如何在数据框中分割数值型变量为因子变量,pandas的数据框也有与R语言同名的函数——cut。
df = pd.DataFrame({'value': np.random.randint(0, 100, 20)})
labels = [ "{0} - {1}".format(i, i + 9) for i in range(0,100,10) ]
df['group'] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels)
pd.cut(x, bins, right=, labels=,include_lowest=False)#df.value代表待风格的变量,第二项是bins可以是一个列表(作为分割点),也可以是一个整数(作为分割带箱数),right控制带宽是左开右闭还是左闭右开,labels设定输出显示标签,include_lowest=控制是否包含边界点(以上参数可以类比R语言中的cut函数)。

最后做一个小总结:
关于因子变量在R语言和Python中涉及到的操作函数;
R语言:
创建因子变量:
factor
转换因子变量:
as.factor
as.numeric(as.character)
分割因子变量:
cut函数
Python:
创建因子变量:
pd.Categorical(categories=,ordered=)
pd.Series(dtype="category")
转换因子变量:
df.astype('category',categories,ordered)
分割因子变量:
df.cut(df.value,breaks=,right=,labels)
上述内容就是如何用R语言和Python实现因子变量与分类重编码,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3335309/blog/4391861



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



