这篇文章将为大家详细讲解有关如何通过JavaAPI读写虚拟机里面的HDFS来创建文件夹,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
本讲我们来讲解如何读写另外一台计算机上面的HDFS。在实际的环境中,我们的HDFS存储和应用程序很有可能是运行在不同的计算机上的。
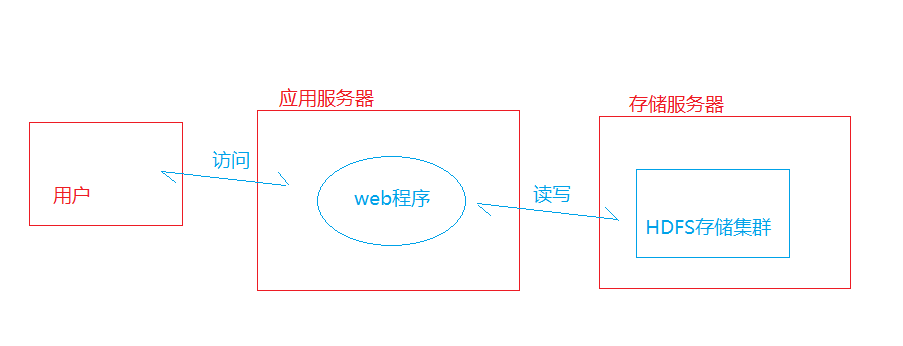
上一讲我们实现了网络的互通,那么这一讲我们来讲解编写一个java程序来读写hdfs.。
步骤:
1、确保两台电脑网络互通(上一讲内容);
2、Centos里面的HDFS运行正常(上一讲内容);
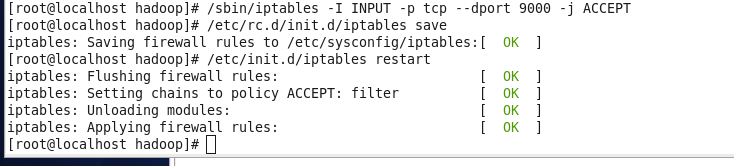
3、Centos里面的防火墙开通9000端口(也就是centos里面的hdfs配置端口)
4、配置Windows里面的JDK;
5、配置Windows里面的Hadoop;
6、配置eclipse相关的hadoop插件或library包
7、创建Java程序。
在centos的防火墙开通9000端口,如下:
centos开启后,在windows里面的浏览器可以访问如下来测试是否能正常访问该端口:(注意这里要用浏览器的极速模式或者谷歌浏览器,ie浏览器或者兼容模式可能无法访问)
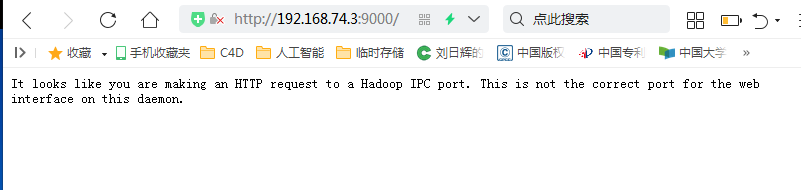
另外,下面的所有的cmd命令都需要在新打开的cmd窗口中操作,如果用之前打开的cmd窗口,有可能测试失败,因为cmd都是针对打开窗口的时候的系统环境生效的。
本次演示的jdk版本
链接:https://pan.baidu.com/s/1X3hqp8DhdF-JEcK4rE6TyQ
提取码:kvgj
我这里的jdk文件存放的位置。

配置java_home
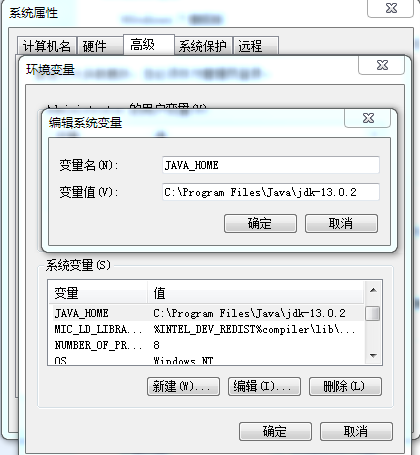
配置class_path
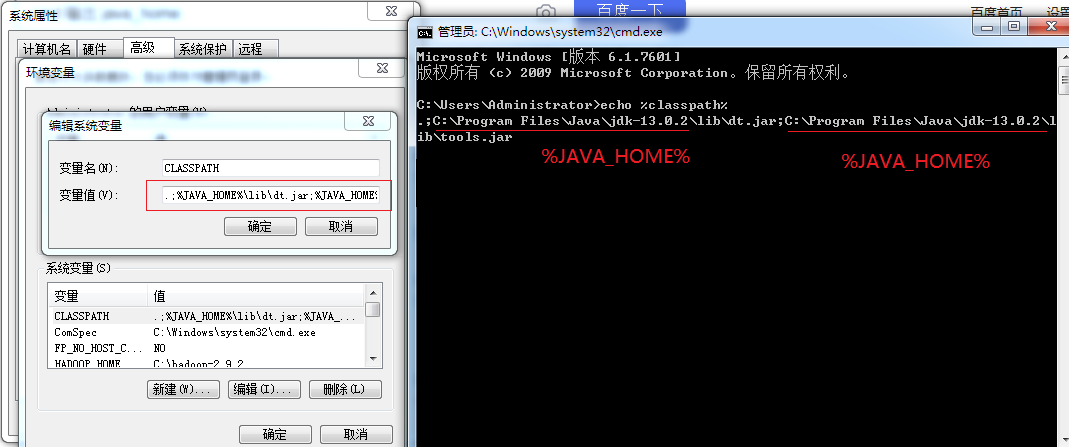
配置path
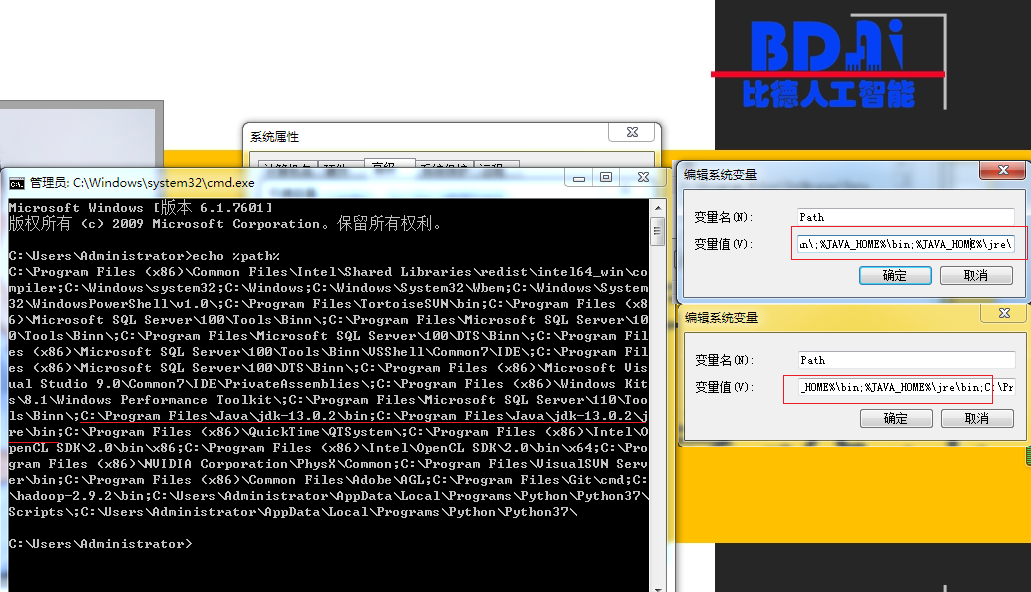
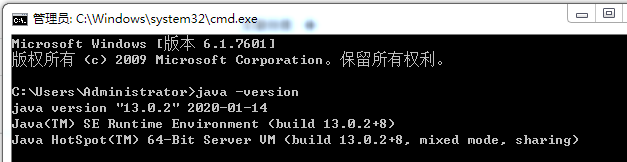
最终测试 java 和javac 命令都正常即可。
把hadoop压缩包解压,和centos里面的是通用的,只不过后缀为tar.zip的压缩包要不断解压才能得到最里面的文件夹。我这里是放在C盘根目录下。
链接:https://pan.baidu.com/s/1AJLenl05gs75XOQJisOyFg
提取码:4t4d
上面的hadoop的版本
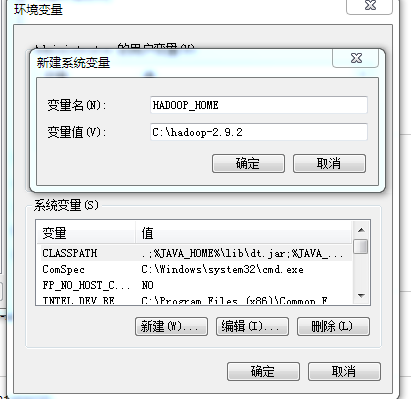
然后配置path,把hadoop_home加入到path里面
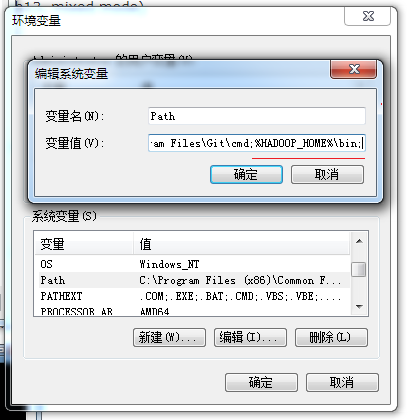
保存后,cmd运行查看版本,或者直接在cmd命令框输入hadoop,如果提示以下错误:
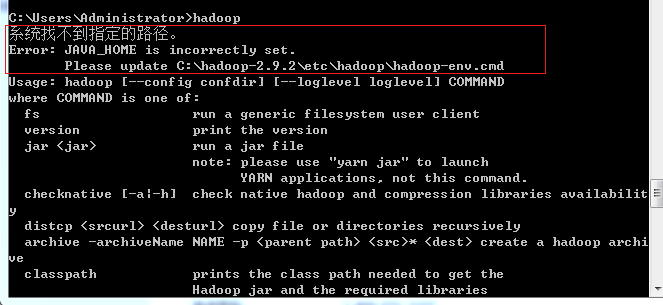
根据提示,打开hadoop下面的hadoop-env.cmd 这里要注意的是cmd后缀是针对windows的,同名的sh后缀的是针对linux系统的。
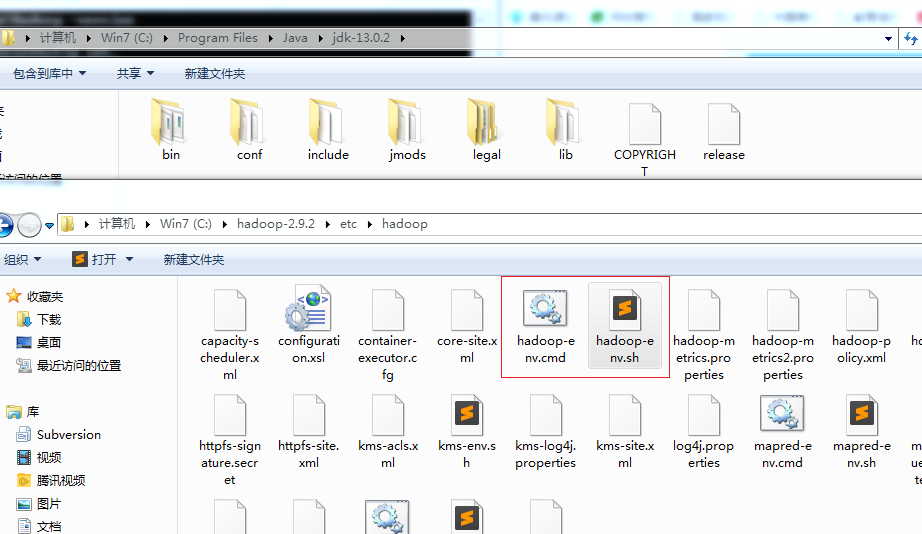
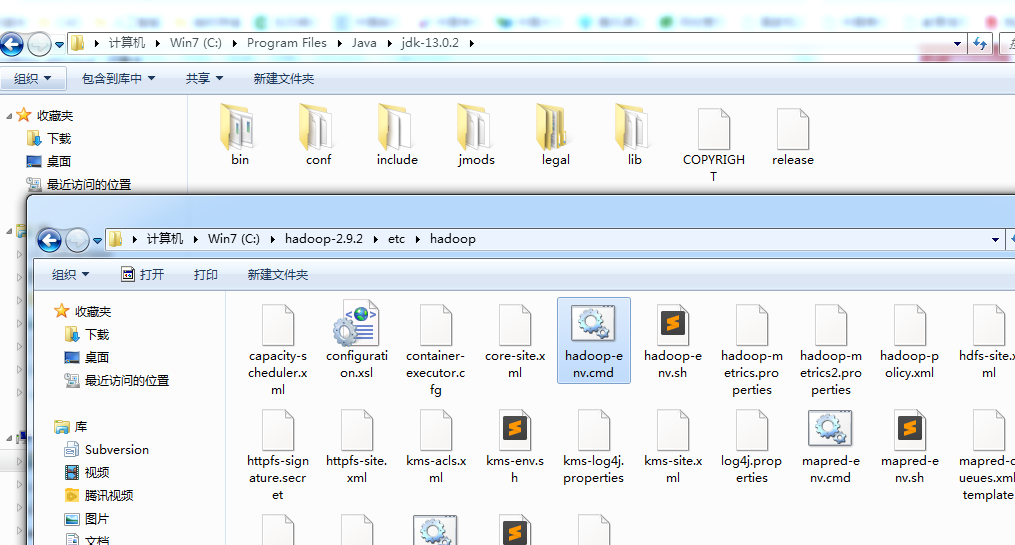
选中hadoop-env.cmd文件,然后点击编辑(双击就直接运行了)。打开后把里面的“set JAVA_HOME=”改成如下:
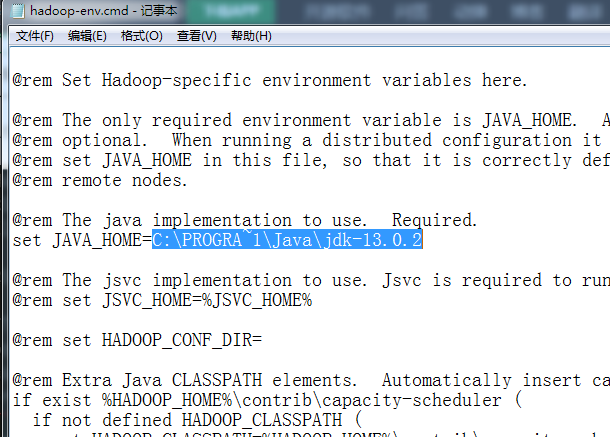
上面要注意的是,因为我的java是放在 C:\Program Files 里面的,如果直接写C:\Program Files\Java\jdk-13.0.2 那么在dos模式下系统是无法识别这个路径的。
dos文件名模式下,“C:\Program Files”的缩写是“PROGRA~1”。或者改成“C:\Program Files”\Java\jdk-13.0.2
也就是用双引号括起来,否则系统无法识别有效的路径。
设置完后,运行cmd,可以看到正常了。
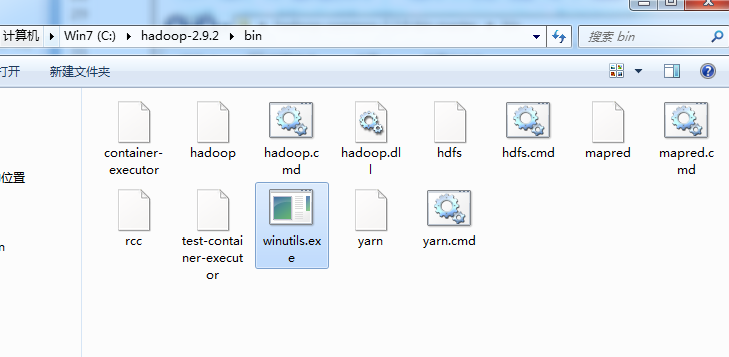
winutils.exe是在Windows系统上需要的hadoop调试环境工具,里面包含一些在Windows系统下调试hadoop、spark所需要的基本的工具类,
单个winutils.exe链接:https://pan.baidu.com/s/1tsnA4dKOaaI-kdtjqZ5gTQ
提取码:ip7h
下载后放在hadoop根目录bin下面
否则会提示:

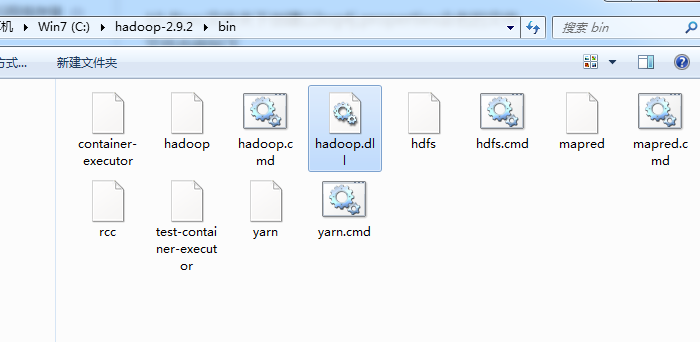
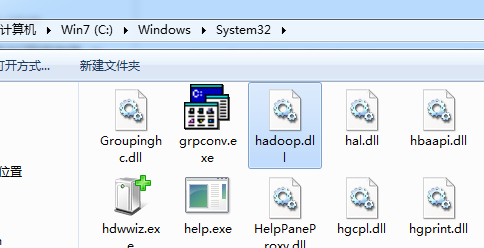
将hadoop.dll分别复制到hadoop根目录的/bin和 C:\windows\system32目录下。
单个hadoop.dll链接:https://pan.baidu.com/s/1kJBEDPXqOKmV1ZvhEbnB_Q
提取码:02hs
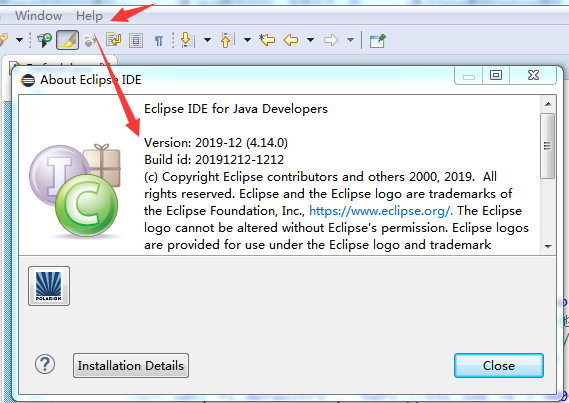
演示用的eclipse版本是4.14:
安装eclipse的hadoop插件,需要下载对应hadoop的eclipse插件版本。这里演示的hadoop版本是2.9.2,所以插件也是匹配的版本。
单个hadoop插件链接:https://pan.baidu.com/s/1cNrQS3tTb3ZsDCb5C3ivlg
提取码:5y5s
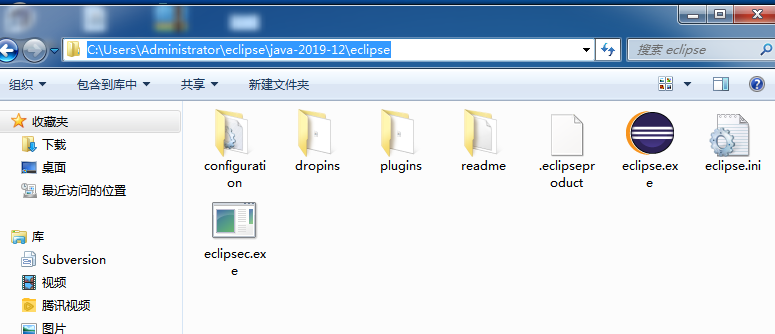
下面是eclipse安装路径:
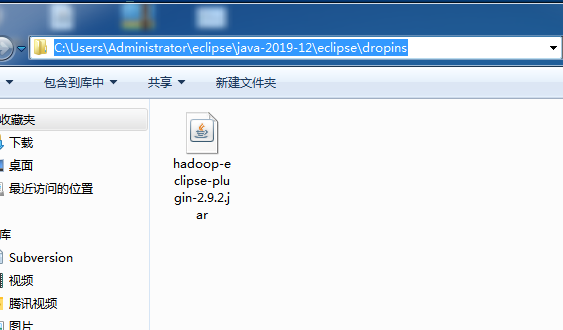
先把eclipse关闭后,再把下载的hadoop-eclipse-plugin-2.9.2.jar放到dropins目录下面。
这里要说下eclipse常见安装插件的方式,网上很多方法都说把上面的jar放到plugins文件夹下面,其实eclipse从3.5版本后已经进行了修改,安装插件一般有3个方法:
1、直接用Eclipse在:“帮助”–>“安装软件”选项下安装。
2、link安装,方法是建一个links,里面建一个link文件把插件的路径配过去。
3、dropins安装方法,把需要的插件复制(拖放)到eclipse\dropins文件夹中,然后插件就安装成功了(当然必须先解压)。如要在其他机器上使用自己的插件。也只需要拷贝自己的dropins覆盖掉原有的。
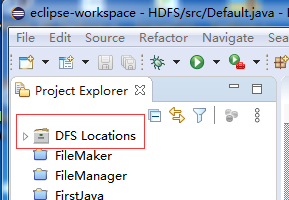
eclipse启动后,可以看到在Project Explorer 多了一个“DFS Locations文件夹”
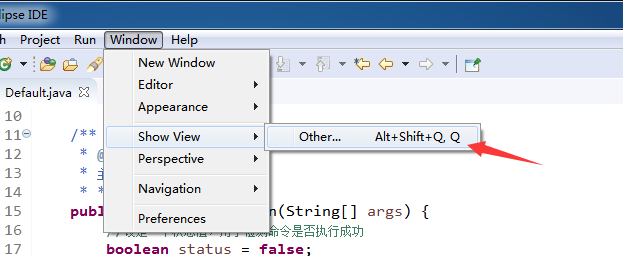
在windows-show view-other 启动hadoop配置窗口
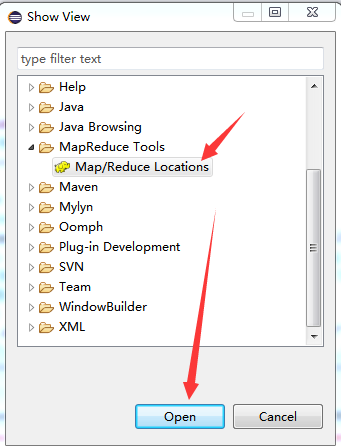
 、
、
选中map/reduce locations 然后点击确定,该窗口就可以显示在IDE底部。
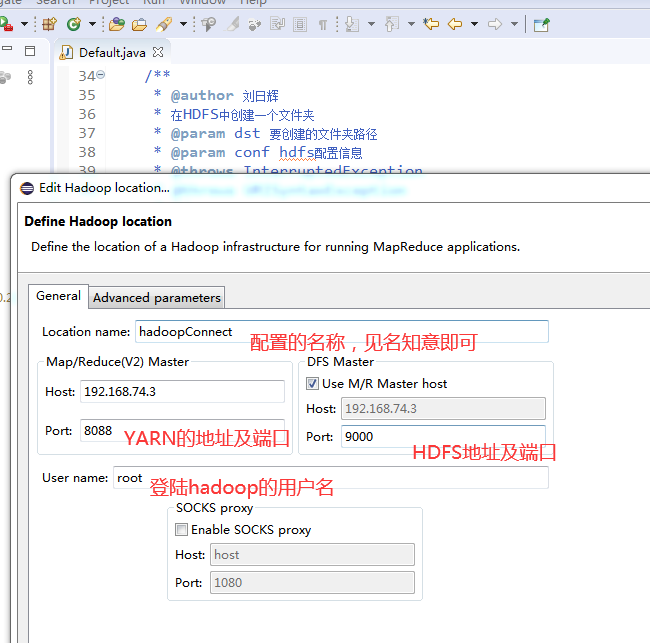
底部可以看到如下,点击右边蓝色的大象图标可以新增配置点:

在配置点中,我们输入以下参数,配置完后点击“Finsh":
然后,再打开:window --> proferences
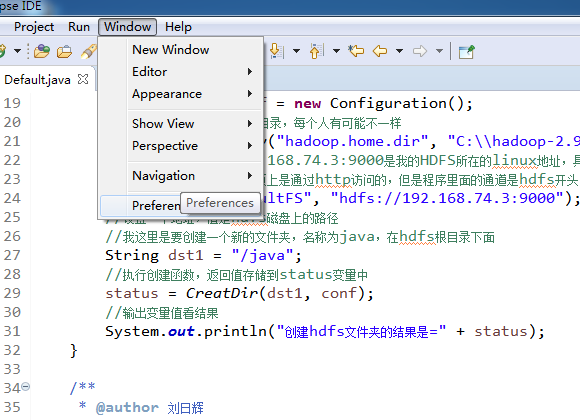
找到Hadoop Map/Reduce 点击右边的browse 配置本地hadoop的安装路径,配置好后点击apply and close 来确认。
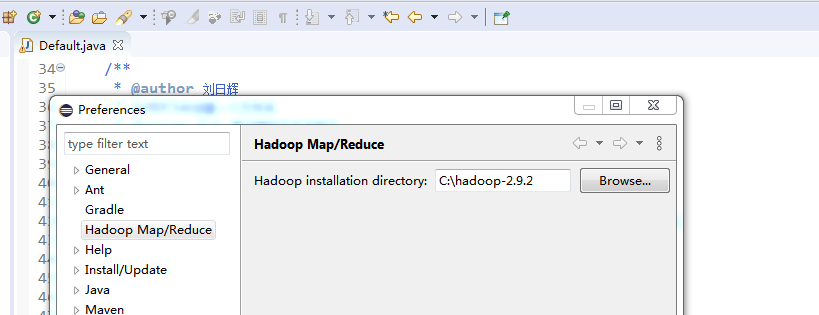
打开eclipse,这里创建一个java项目,名称自定,

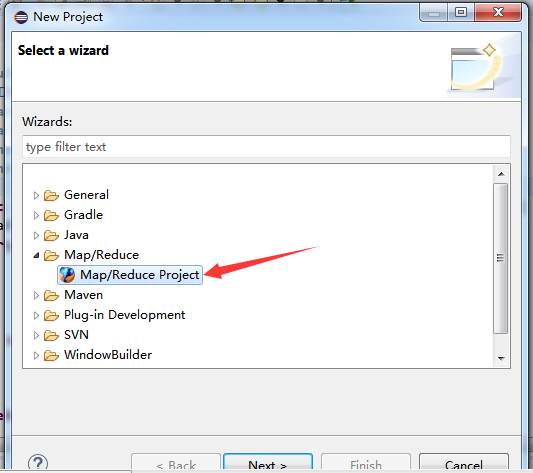
在map/reduce 里面选中 map/reduce project
起一个名称,点击next
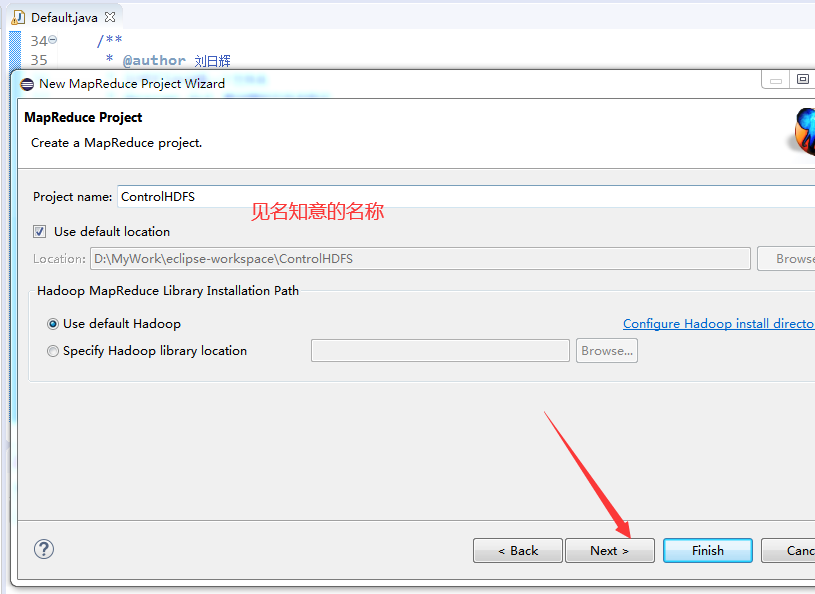
完成后,我们可以看到新建的项目里面多了一个library包,里面包含了hadoop所用到的jar.
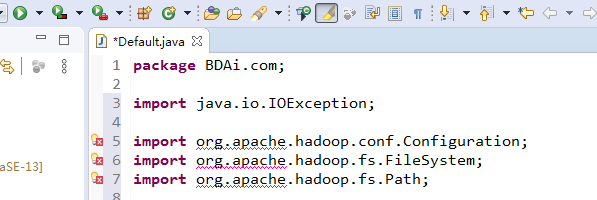
如果不到如hadoop的jar包,我们会发现,很多问题,如下红色波浪线:
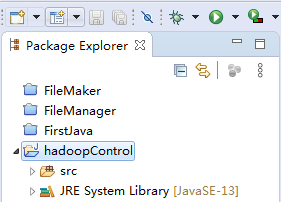
首先:选中你自己创建的项目,如下:
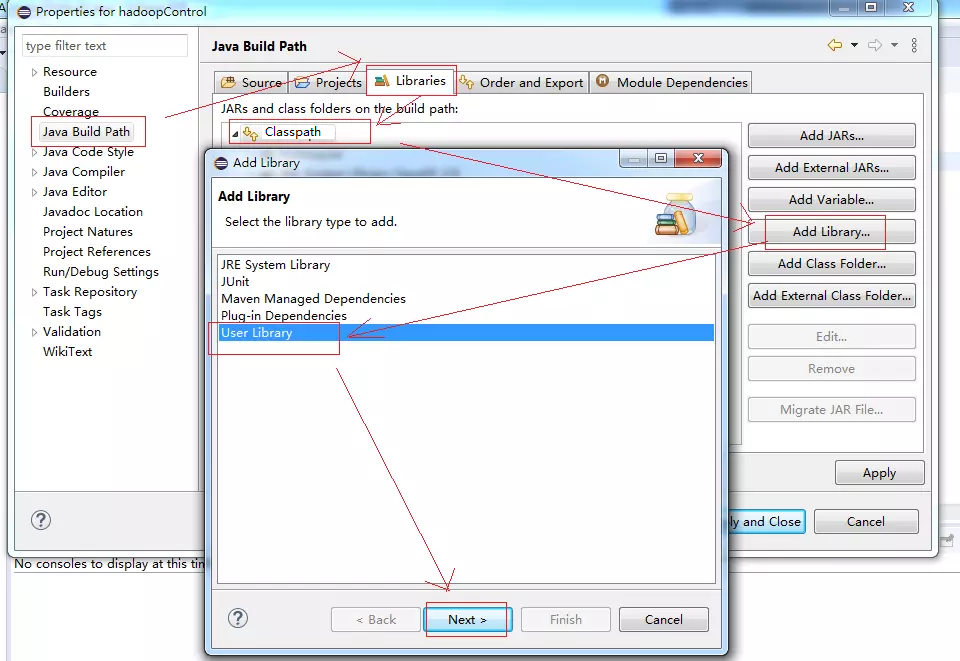
然后点击File->Properties->

然后选中“Java Buile Path->Libraries->ClassPath->Add Library->User Library” 来创建一个自定义的jar包存储位置,然后点击Next
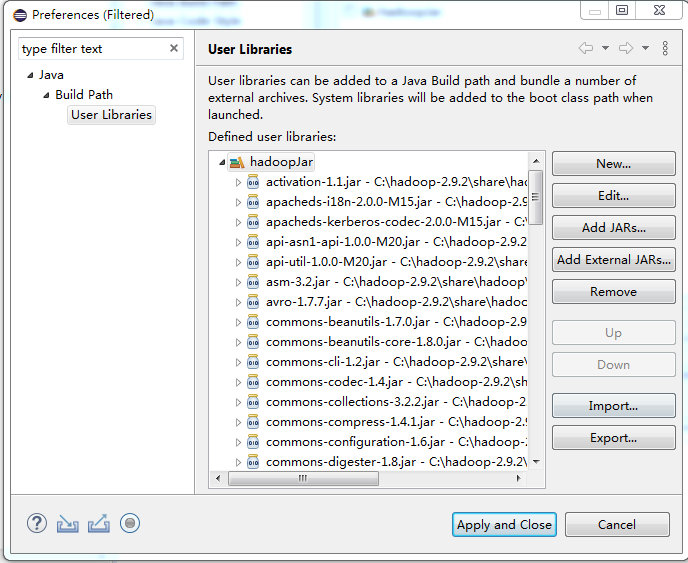
然后点击“User Libraries-->New...”在输入框中输入你要创建的Libraries的名称,这里名称自定,同样是要见名知意。我这里是hadoopJar
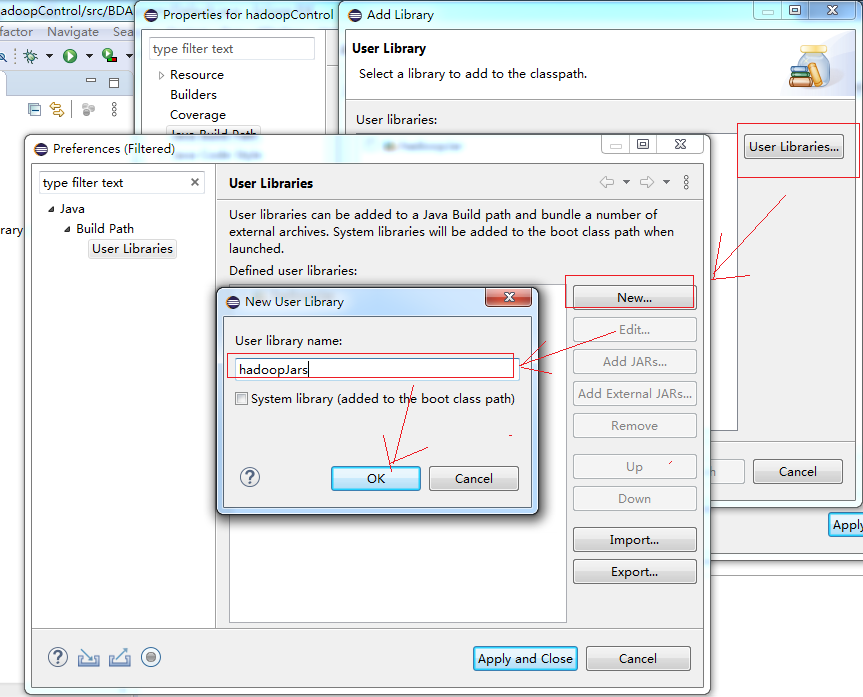
最后点击OK,然后点击应用按钮“Apply and Close”进入到下面的界面。
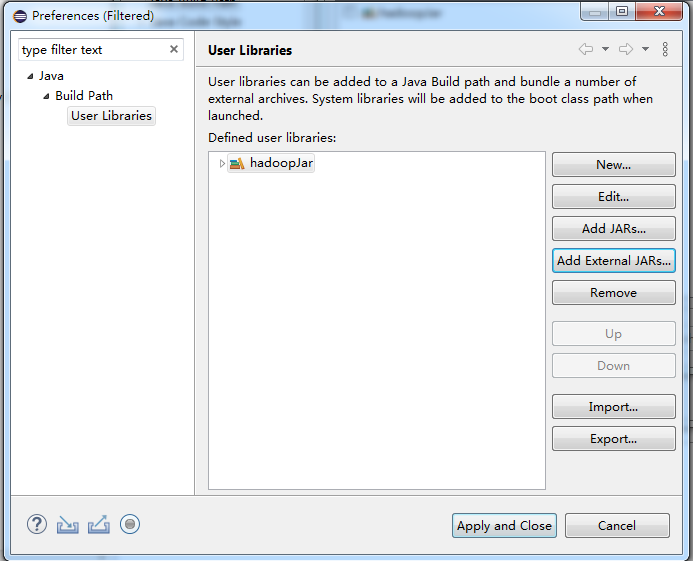
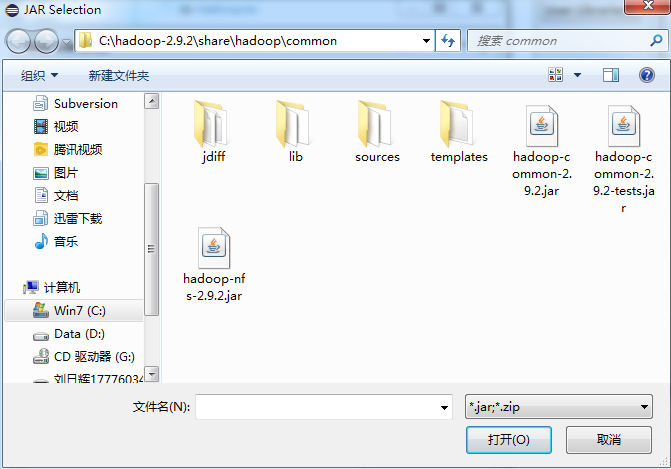
点击add external Jars 来添加jar包的路径。把common下面的所有jar包选中就可以了。
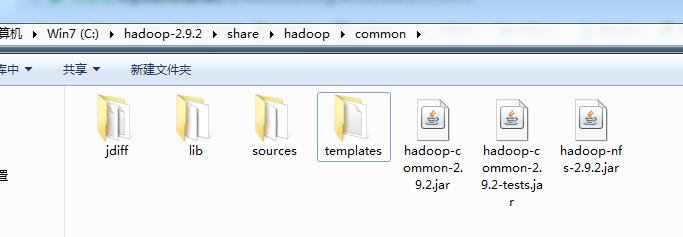
如下common目录下有
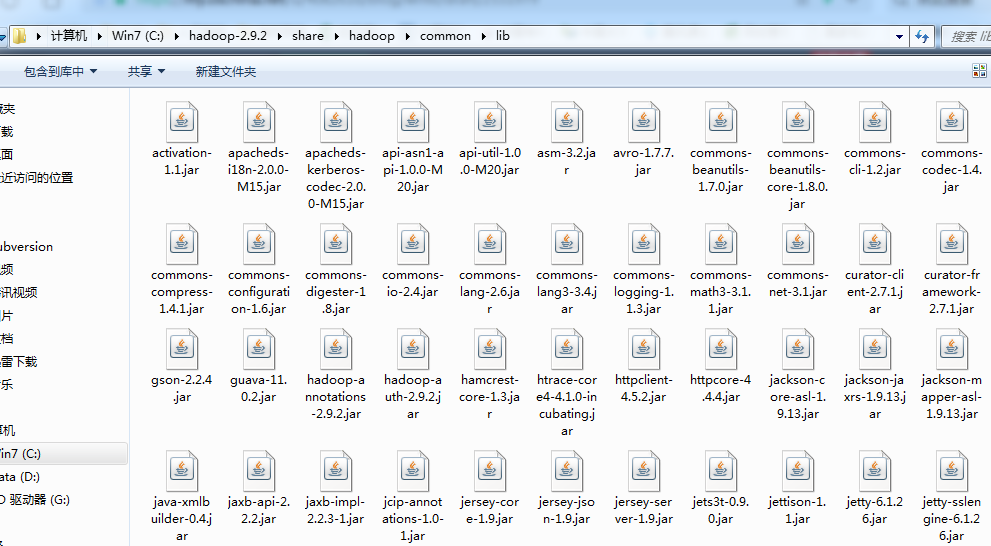
lib目录下也有
souces里面也有
所有选完后我们展开hadoopJar可以看到有了很多jar包
最后点击下面的“apply and close”
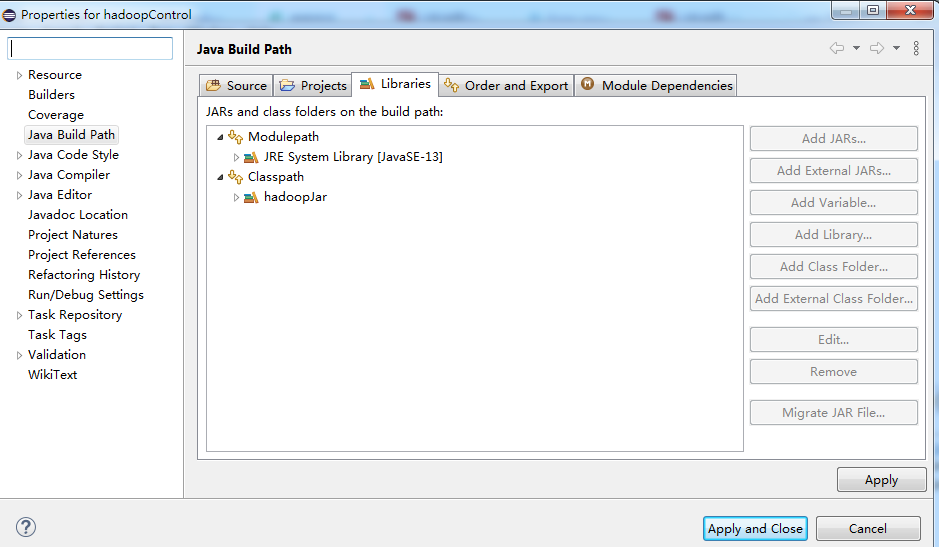
这时候我们可以看到,所有导包的语句没有了波浪线。
注意我这里是要在我的hdfs的根目录下面创建一个java的文件夹。我们看到原来centos的hdfs里面是没有java这个文件夹的。

在项目的src文件夹里面创建一个package,
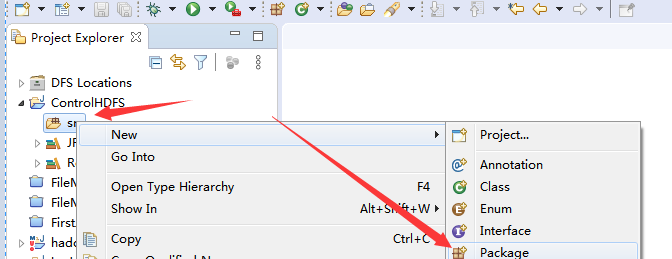
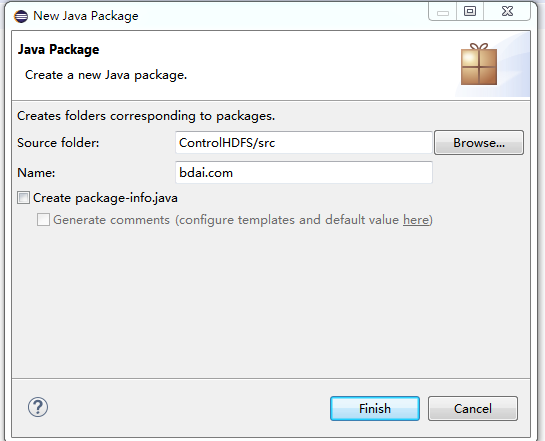
在name这里输入名称,名称自定
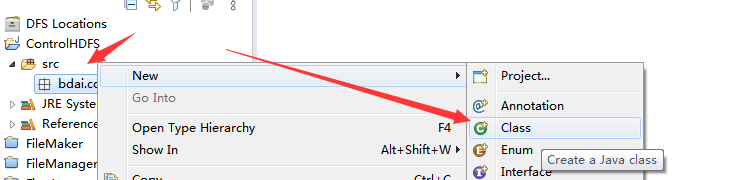
,然后在包里面创建主类,主类名称同样自定。包主要是为了后续给class分类。
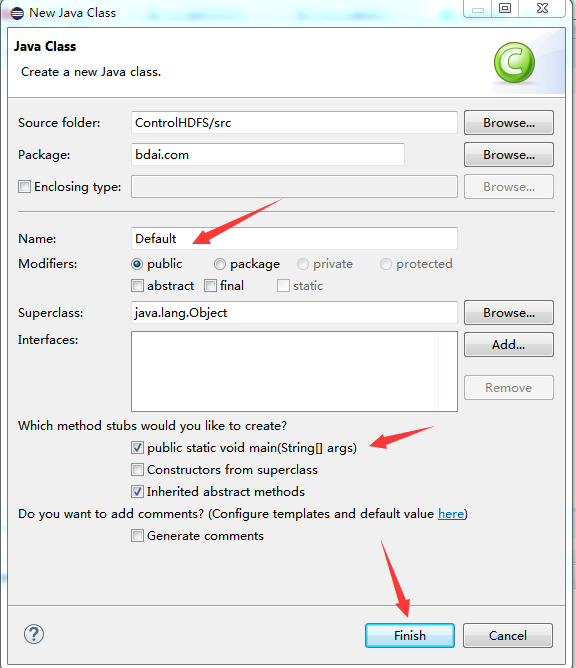
在主类中编写代码如下,不给你们源码了,好好找找写代码的感觉:
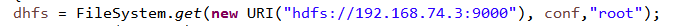
也就是规定通过root
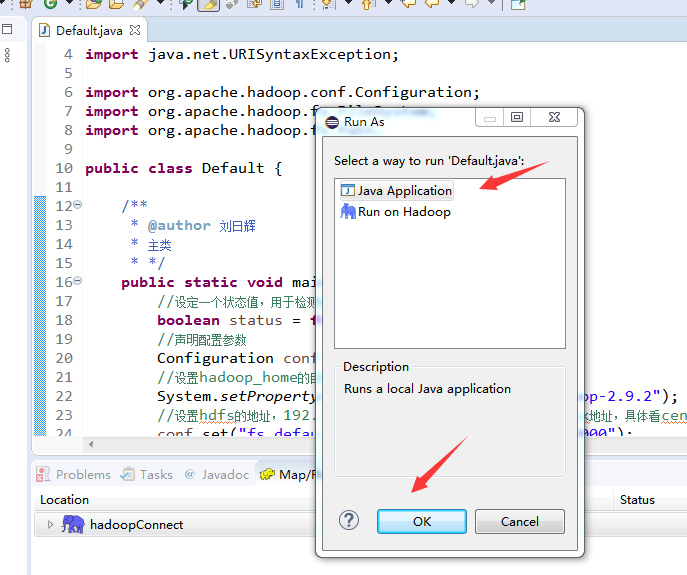
保存后运行结果如下,选择“java application”:
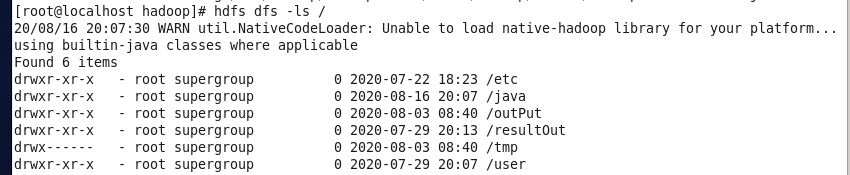
结果如下:
最后,如果想统一下载所有内容的,可以用这个链接(文件比较大):
链接:https://pan.baidu.com/s/1DIHvbSoWvYRLBaP7qQI9ng
提取码:olgh
关于如何通过JavaAPI读写虚拟机里面的HDFS来创建文件夹就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





