怎么解决G1垃圾回收器GC频繁导致的系统波动问题,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
CPU波动如图所示:
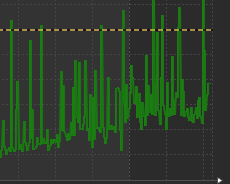
内存波动如图所示:
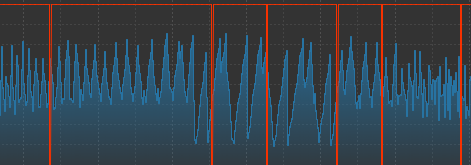
CPU经常达到告警阈值,触发告警信息,第一反应就是去看下java进程里哪个线程耗CPU资源多,其实这里看到内存波动情况就大致能猜测出和GC有关。
top -Hp PID
PID %CPU %MEM TIME+ COMMAND
89011 70.9 31.8 154:44.25 java
89001 7.7 31.8 216:48.06 java
90049 7.7 31.8 57:37.76 java将 89011 转换为十六进制 15bb3
通过jstack导出来的线程快照可以找到 15bb3 对应的线程,结果如下所示:
cat 01_jstack.txt | grep '15bb3' --color
"Gang worker#0 (G1 Parallel Marking Threads)" os_prio=0 tid=0x00117f198005f000 nid=0x15bb3 runnable可以看到是G1在执行GC的时候导致CPU强烈波动,和我们的猜测是吻合的。
马上看了下GC日志,很恐怖
15:30:46.696+0800: 52753.211: [GC pause (G1 Humongous Allocation) (young) (to-space exhausted), 0.3541373 secs]
[Parallel Time: 146.3 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 52753215.2, Avg: 52753215.2, Max: 52753215.2, Diff: 0.0]
[Ext Root Scanning (ms): Min: 3.9, Avg: 4.2, Max: 4.7, Diff: 0.7, Sum: 16.7]
[Update RS (ms): Min: 103.8, Avg: 104.3, Max: 104.4, Diff: 0.6, Sum: 417.1]
[Processed Buffers: Min: 1512, Avg: 1551.5, Max: 1582, Diff: 70, Sum: 6206]
[Scan RS (ms): Min: 1.6, Avg: 1.6, Max: 1.7, Diff: 0.1, Sum: 6.6]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 35.9, Avg: 36.1, Max: 36.2, Diff: 0.3, Sum: 144.2]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 146.2, Avg: 146.2, Max: 146.2, Diff: 0.1, Sum: 584.8]
[GC Worker End (ms): Min: 52753361.4, Avg: 52753361.4, Max: 52753361.4, Diff: 0.0]
[Code Root Fixup: 0.3 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.2 ms]
[Other: 207.3 ms]
[Evacuation Failure: 199.2 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 1.2 ms]
[Ref Enq: 0.1 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.2 ms]
[Humongous Reclaim: 1.9 ms]
[Free CSet: 0.2 ms]
[Eden: 644.0M(1994.0M)->0.0B(204.0M) Survivors: 10.0M->0.0B Heap: 2886.0M(4096.0M)->1675.7M(4096.0M)]
[Times: user=1.29 sys=0.00, real=0.36 secs]几乎是平均5秒一次的大对象分配失败,导致每一次GC耗时300ms以上,不仅仅导致CPU增长,也导致了STW,大量的数据积压。
起初看到这个马上觉得可能是内存不足导致的,偷偷的在一台机器上做了试验,由4G堆内存增加到6G堆内存。
-Xmx6144m -Xms6144m
经过一天的观察,发现CPU和内存的波动较之前没有那么明显,但是依然会有波动,只是拉长了波动范围,GC的间隔时间变长了。 很显然加这点内存这个治标不治本。
因为是是大对象分配失败,我们的预留分配空间也是不小的,根本不可能存在分配失败的情况,配置如下:
-XX:G1ReservePercent=25这时候马上想到了去看下gc时堆空间的变化情况。
jstat -gc PID 500 100
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 10240.0 0.0 10240.0 2232320.0 163840.0 1951744.0 1306537.7 143616.0 136650.1 16896.0 15666.3 66281 9351.321 0 0.000 9351.321
0.0 10240.0 0.0 10240.0 2232320.0 227328.0 1951744.0 1431467.6 143616.0 136650.1 16896.0 15666.3 66282 9351.321 0 0.000 9351.321
0.0 8192.0 0.0 8192.0 2226176.0 86016.0 1959936.0 1156258.9 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2226176.0 151552.0 1959936.0 1228965.3 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2226176.0 219136.0 1959936.0 1377447.6 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2226176.0 286720.0 1959936.0 1505449.5 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2226176.0 358400.0 1959936.0 1697964.5 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2226176.0 415744.0 1959936.0 1863855.0 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2160640.0 481280.0 2025472.0 2023601.4 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 2017280.0 546816.0 2168832.0 2167987.6 143616.0 136650.1 16896.0 15666.3 66282 9351.411 0 0.000 9351.411
0.0 8192.0 0.0 8192.0 1935360.0 581632.0 2250752.0 2249908.9 143616.0 136650.1 16896.0 15666.3 66283 9351.411 0 0.000 9351.411
0.0 0.0 0.0 0.0 221184.0 90112.0 3973120.0 1709604.2 143616.0 136650.1 16896.0 15666.3 66283 9351.727 0 0.000 9351.727
0.0 0.0 0.0 0.0 221184.0 145408.0 3973120.0 1850918.4 143616.0 136650.1 16896.0 15666.3 66283 9351.727 0 0.000 9351.727
0.0 0.0 0.0 0.0 221184.0 208896.0 3973120.0 1992232.5 143616.0 136650.1 16896.0 15666.3 66284 9351.727 0 0.000 9351.727
0.0 4096.0 0.0 4096.0 217088.0 61440.0 3973120.0 1214197.0 143616.0 136650.1 16896.0 15666.3 66284 9351.797 0 0.000 9351.797
0.0 4096.0 0.0 4096.0 217088.0 129024.0 3973120.0 1379063.5 143616.0 136650.1 16896.0 15666.3 66284 9351.797 0 0.000 9351.797
0.0 4096.0 0.0 4096.0 217088.0 192512.0 3973120.0 1538809.9 143616.0 136650.1 16896.0 15666.3 66284 9351.797 0 0.000 9351.797
0.0 6144.0 0.0 6144.0 2252800.0 57344.0 1935360.0 1060884.7 143616.0 136650.1 16896.0 15666.3 66285 9351.873 0 0.000 9351.873
0.0 6144.0 0.0 6144.0 2252800.0 100352.0 1935360.0 1157142.1 143616.0 136650.1 16896.0 15666.3 66285 9351.873 0 0.000 9351.873
0.0 6144.0 0.0 6144.0 2252800.0 182272.0 1935360.0 1335320.9 143616.0 136650.1 16896.0 15666.3 66285 9351.873 0 0.000 9351.873
0.0 6144.0 0.0 6144.0 2252800.0 227328.0 1935360.0 1417242.1 143616.0 136650.1 16896.0 15666.3 66285 9351.873 0 0.000 9351.873
0.0 8192.0 0.0 8192.0 2252800.0 116736.0 1933312.0 1203152.9 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2252800.0 186368.0 1933312.0 1201107.2 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2252800.0 256000.0 1933312.0 1346517.4 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2252800.0 313344.0 1933312.0 1492951.6 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2252800.0 378880.0 1933312.0 1660890.2 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2252800.0 440320.0 1933312.0 1806300.4 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2228224.0 499712.0 1957888.0 1956830.7 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 2095104.0 546816.0 2091008.0 2089952.7 143616.0 136650.1 16896.0 15666.3 66286 9351.970 0 0.000 9351.970
0.0 8192.0 0.0 8192.0 1982464.0 593920.0 2203648.0 2203618.5 143616.0 136650.1 16896.0 15666.3 66287 9351.970 0 0.000 9351.970
0.0 0.0 0.0 0.0 221184.0 75776.0 3973120.0 1607096.3 143616.0 136650.1 16896.0 15666.3 66287 9352.284 0 0.000 9352.284
0.0 0.0 0.0 0.0 221184.0 114688.0 3973120.0 1681849.4 143616.0 136650.1 16896.0 15666.3 66287 9352.284 0 0.000 9352.284
0.0 0.0 0.0 0.0 221184.0 200704.0 3973120.0 1896892.7 143616.0 136650.1 16896.0 15666.3 66287 9352.284 0 0.000 9352.284
0.0 4096.0 0.0 4096.0 217088.0 63488.0 3973120.0 1134152.3 143616.0 136650.1 16896.0 15666.3 66288 9352.356 0 0.000 9352.356
0.0 4096.0 0.0 4096.0 217088.0 116736.0 3973120.0 1279562.6 143616.0 136650.1 16896.0 15666.3 66288 9352.356 0 0.000 9352.356
0.0 4096.0 0.0 4096.0 217088.0 180224.0 3973120.0 1407564.5 143616.0 136650.1 16896.0 15666.3 66288 9352.356 0 0.000 9352.356
0.0 6144.0 0.0 6144.0 2244608.0 65536.0 1943552.0 1115144.2 143616.0 136650.1 16896.0 15666.3 66289 9352.454 0 0.000 9352.454
0.0 6144.0 0.0 6144.0 2244608.0 131072.0 1943552.0 1256458.4 143616.0 136650.1 16896.0 15666.3 66289 9352.454 0 0.000 9352.454
0.0 6144.0 0.0 6144.0 2244608.0 204800.0 1943552.0 1412108.8 143616.0 136650.1 16896.0 15666.3 66289 9352.454 0 0.000 9352.454
0.0 8192.0 0.0 8192.0 2238464.0 77824.0 1947648.0 1108199.4 143616.0 136650.1 16896.0 15666.3 66290 9352.558 0 0.000 9352.558
0.0 8192.0 0.0 8192.0 2238464.0 141312.0 1947648.0 1147881.6 143616.0 136650.1 16896.0 15666.3 66290 9352.558 0 0.000 9352.558
0.0 8192.0 0.0 8192.0 2238464.0 212992.0 1947648.0 1281003.6 143616.0 136650.1 16896.0 15666.3 66290 9352.558 0 0.000 9352.558这很明显是老年代一直在增长,而且增加特别快,当增长到老年代分配的总大小的时候就发生了GC,一次耗时300ms左右。 能直接跃升到老年的对象,且如此之多,很明显是对象的大小超过了 HeapRegionSize 的一半大小以上,直接被扔到了老年代区域。 对于G1来说,如果 HeapRegionSize 没有配置,那么这个值是智能变化的。 region sizes <1MB or >32MB ,通常来说,它的值可以参考如下:
https://stackoverflow.com/questions/46786601/how-to-know-region-size-used-of-g1-garbage-collector
in general these are the region-sizes per heap-size range:
<4GB - 1MB
<8GB - 2MB
<16GB - 4MB
<32GB - 8MB
<64GB - 16MB
64GB+ - 32MBFor G1 GC, any object that is more than half a region size is considered a "Humongous object". Such an object is allocated directly in the old generation into "Humongous regions". These Humongous regions are a contiguous set of regions. StartsHumongous marks the start of the contiguous set and ContinuesHumongous marks the continuation of the set.
参考文献: https://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
这说明是真的一直在分配大对象,在撑死了老年代的时候引发了GC的停顿。
这时候有点尴尬,又在这个夜黑风高的晚上偷偷的问运维要了jmap的命令权限,找了一台生产环境的机器导了N份hprof文件下来。
jmap -dump:live,format=b,file=xxx.hprof PID从服务器拉下来N个hprof文件到本地一对比分析发现了很吓人的东西。
堆里面的 byte[] 对象占堆内存一半以上的空间,且里面一个数组的大小不多不少,正好1M。 每一个 byte[] 的大小是 1048579 的字节。
这到底是什么东西分配了这么多的 byte 数组,且一次就分配1M。
通过使用 jvisualvm 把单独的一个 byte[] 数组的内容导成csv文件看了下,内容大致如下所示:
112, 2, 0, 67, 48, 89, 111, 76, 15, 46, 97, 107, 16, 99, 12, 101, 46, 99, 97, 12, 101, 115, 46, 105, 119, 12, 118, 46, 68, 12, 108, 97, 119, 101, 12, 66, 120, 99, 15, 90, 118, 110, 14, 70, 111, 108, 100, 17, 114, -103, 10, 11, 120, 99, 10, 97, 110... <已截断>看到这些字节数据,我觉得可以写一个工具把这些数据转换为字符,因为可以知道只要用 ASCII 表可以转换过来看到大致的数据内容。
小工具代码如下:
public static void main(String[] args) throws IOException {
int i = 0;
File file = new File("1.csv");
String str = FileUtils.readFileToString(file, "utf-8");
String[] list = str.split(",");
for (String s : list) {
byte b = Byte.valueOf(s);
char c = (char) b;
System.out.print(c);
i++;
if (i > 3000) {
break;
}
}
System.out.println("hello end");
}抽查了几个1M对象导出csv字节文件,执行转换后的大致内容如下所示:
eId inFault outFault exception in out inHeader outHeader
properties0:ID-dcn-15597-1561992626862-68-335522280FFNS {"action":"xxxx","actionTm":"2019-xx-xx 02:26:29","aType":X,"code":"xxxxx","Type":x,"bId":"xxxx","bMessage":{"bOrg":1,"boxName
......看到这里马上就明白了这是我们的kafka消息报文的字节数组,而这一段kafka消息在我们系统的并发量能派件前三,数据量也是稳居前排。
分析这种情况应该是生产消息或者消费接受消息的时候为消息生成的字节数组,马上找到了生产者和消费者的基础组件的核心代码,发现了这样一段代码:
baos = new ByteArrayOutputStream(point.getMaxRequestSizeBytes()); ...... eData = baos.toByteArray();
这是生产者的代码,其中 getMaxRequestSizeBytes 如果没有配置值的话默认大小是 1048576 ,将消息放在了一个如此大的数组里面,这种对象分配直接扔到了老年代。 而这个消息又是并发量比较大,TPS是3000左右,所以导致了老年代空间使用率瞬间就上去了,分配失败,然后GC,接着又上去,又分配失败,接着GC。。。
问题终于水落石出了,解决方案有两种:
设置 getMaxRequestSizeBytes 的值为 1024*256 ,减少每一个消息的数组的大小,使其不会超过 HeapRegionSize 的一半大小,这个缺陷就是需要保证消息的大小必须在 1024*256 字节以内。
调整堆内存大小为8G或以上,同时增加配置 -XX:G1HeapRegionSize=4M ,使得1M的消息数组大小小于 HeapRegionSize 的一半。
HeapRegionSize 常见的大小是:
<4GB - 1MB <8GB - 2MB <16GB - 4MB <32GB - 8MB <64GB - 16MB 64GB+ - 32MB
一般情况下使用堆内存大小/2048个Region。
看完上述内容,你们掌握怎么解决G1垃圾回收器GC频繁导致的系统波动问题的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/110NotFound/blog/3084898



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



