这篇文章主要讲解了“HashedWheelTimer的作用是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“HashedWheelTimer的作用是什么”吧!
和同事讨论一个定时审核的需求,运营设定审核通过的时间,到了这个时间之后,相关内容自动审核通过,本是个小的需求,但是考虑到如果需要定时审核的东西很多,这样大量的定时任务带来的一系列问题,然后逐步的讨论到了netty的HashedWheelTimer这个的实现。
把所有需要定时审核的资源放到redis中,例如sorted set中,需要审核通过的时间作为score值。后台启动一个定时器,定时轮询sortedSet,当score值小于当前时间,则运行任务审核通过。
这个方案在小批量数据的情况下没有问题,但是在大批量任务的情况下就会出现问题了,因为每次都要轮询全量的数据,逐个判断是否需要执行,一旦轮询任务执行比较长,就会出现任务无法按照定时的时间执行的问题。
每个需要定时完成的任务都启动一个定时任务,然后等待完成之后销毁
这个方案带来的问题很明显,定时任务比较多的情况下,会启动很多的线程,这样服务器会承受不了之后崩溃。基本上不会采取这个方案。
和方案一类似,针对每一个需要定时审核的任务,设定过期时间,过期时间也就是审核通过的时间,订阅redis的过期事件,当这个事件发生时,执行相应的审核通过任务。
这个方案来说是借用了redis这种中间件来实现我们的功能,这中实际上属于redis的发布订阅功能中的一部分,针对redis发布订阅功能是不推荐我们在生产环境中做业务操作的,通常redis内部(例如redis集群节点上下线,选举等等来使用),我们业务系统使用它的这个事件会产生如下两个问题 1、redis发布订阅的不稳定问题 2、redid发布订阅的可靠性问题 具体可以参考 https://my.oschina.net/u/2457218/blog/3065021 (redis的发布订阅缺陷)
也许你和我一样都是第一次听说这个东西,这个东西就是专为大批量定时任务管理而生。具体论文详见参考文献[2]
简要的说这个是一个轮,里面有指针,指针会根据设定的时间单位旋转,任务根据一些算法会落在相应的槽位上。如下图 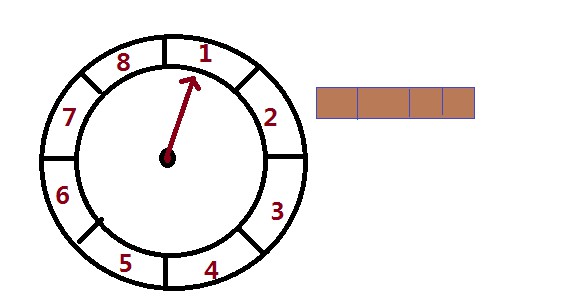
首先会有一个轮,这个轮在这里分成了8个槽位,任务任务添加的时候会根据相应的算法对槽位个数取模,得到任务会存储在具体哪个槽位,每个槽位是一个链表结构,任务存储了任务的过期时间(任务执行时间),任务需要执行需要指针转的轮数,指针(tick) 每间隔一个单位的时间会往下走一个槽位,然后会查询这个槽位上的存储的任务,并且任务的存储的剩余轮数会减一,当剩余轮数小于等于零时,就会开始执行这个任务,执行之后会把任务从这个槽位上给删除掉。
例如上图: 槽位为8个槽位 Bucket 指针每个时间间隔(100ms)会往下走一个槽位,这个时间间隔叫做tickDuration 那相当于每隔8*100ms=800ms,会轮询一圈。
算法理解起来比较简单,并且也有成熟的实现,那就是在netty中有一个HashedWheelTimer这个类,把这个算法实现了出来。接下来分析分析一下它的这个代码。
在这个类上定义的有几个比较重要的属性
/** *这个work是一个内部类,实现了Runable接口,是比较核心的一个类,包装了具体任务的运行,把任务放到具体如何放到某个槽位上,指针往下走的具体方法,任务取消等。 */ private final Worker worker = new Worker(); /** *工作线程,这个就是整个HashedWheelTimer启动的起点 */ private final Thread workerThread; /** *当前任务的状态,1代表任务已经开始执行,0任务初始化,2任务已关闭 */ public static final int WORKER_STATE_INIT = 0; public static final int WORKER_STATE_STARTED = 1; public static final int WORKER_STATE_SHUTDOWN = 2; /** *这个很核心的一个概念,就是指针往下走的单位,在HashedWheelTimer这个类中,默认是100ms指针往下走一个单位 */ private final long tickDuration; /** * 这个就是指的时间轮,有多少个槽位,wheel的大小就是多大,HashedWheelTimer中默认槽位有512个 */ private final HashedWheelBucket[] wheel; /** * 主要辅助计算任务会存储在哪个槽位上,mask =wheel.length-1 */ private final int mask; /** *所有要执行的任务的任务队列 */ private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue(); /** *所有要取消的任务的任务队列 */ private final Queue<HashedWheelTimeout> cancelledTimeouts = PlatformDependent.newMpscQueue(); /** *HashedWheelTimer实例开始运行的时间,是纳秒数,开始时间是System.nanotime() */ private volatile long startTime;
这些属性的定义和概念映射到上面时间轮算法上就是下图的样子了。 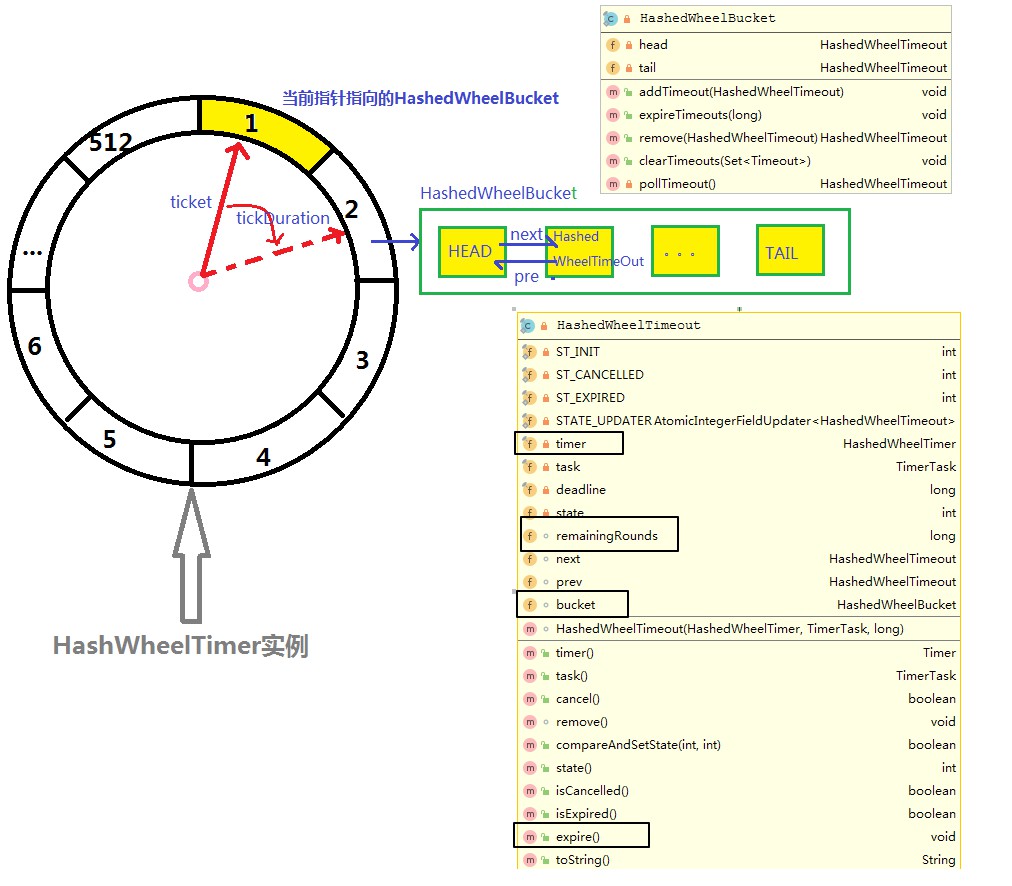
HashedWheelTimer初始化主要是在它的构造函数中,提供了多种重载方式,只需要看最全的构造函数即可。
/**
* Creates a new timer.
* @param threadFactory 执行任务的工厂
* @param tickDuration 指针往下走一步的时间间隔
* @param unit 指针往下走一步的时间单位,秒,毫秒。纳秒等
* @param ticksPerWheel 时间轮的大小,也就是槽位的个数
*/
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
/**
* 先校验参数的合法性,对threadFactory,时间单位,时间间隔,时间轮大小做了限制
*/
if (threadFactory == null) {
throw new NullPointerException("threadFactory");
}
if (unit == null) {
throw new NullPointerException("unit");
}
if (tickDuration <= 0) {
throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
}
if (ticksPerWheel <= 0) {
throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
}
// 创建槽位,实际上就是初始化HashedWheelBucket数组,直接new出来的
wheel = createWheel(ticksPerWheel);
//用来计算槽位的辅助变量,一会儿会在Worker中寻找槽位时使用到
mask = wheel.length - 1;
...
//初始化线程,是用threadFactory创建出来的一个worker线程
workerThread = threadFactory.newThread(worker);
...
}当需要添加一个定时任务的时候,是通过newTimeout方法添加的,添加的任务必须实现TimerTask接口的run方法。任务添加之后,无需显式的开启任务,添加之后任务会自动开启,等到了执行的时间会被自动执行。客户端使用的方式如下:
@Test
public void testRun() throws Exception{
final CountDownLatch latch = new CountDownLatch(1);
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer();
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("hello world");
latch.countDown();
}, 5, TimeUnit.SECONDS);
latch.await();
System.out.println("执行结束");
}5秒钟之后会被输出"hello world",然后任务执行完毕。既然任务的添加和执行入口都是通过newTimeout这个方法搞定的,那就看一下这个方法里面有哪些秘密吧。
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
...
start();
...
/**
* 可以看到任务存活的时间计算,当前时间的毫秒数加上我们设定的时间,然后减去程序开始执行的时间。这是一个时间段
*/
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}进去看了之后,这个方法很简单,有两个关键的方法调用 1、start(),这个方法主要是看当前HashedWheelTimer的状态是否已经启动,如果没有启动则会调用workThread线程的启动方法。2、计算超时时间和任务添加。我们传进来的任务会被包装成一个HashWheelTimeout这个类,包装之后会把这个包装类放到timeouts这个阻塞队列中去,实际上这时候任务并没有放到某个具体槽位中,只是先放到阻塞队列中,等待work从这个队列中取值然后放到具体的槽位上,HashedWheelTimer是一个双向链表,上面图中已经有这个类的类图结构,再贴一次: 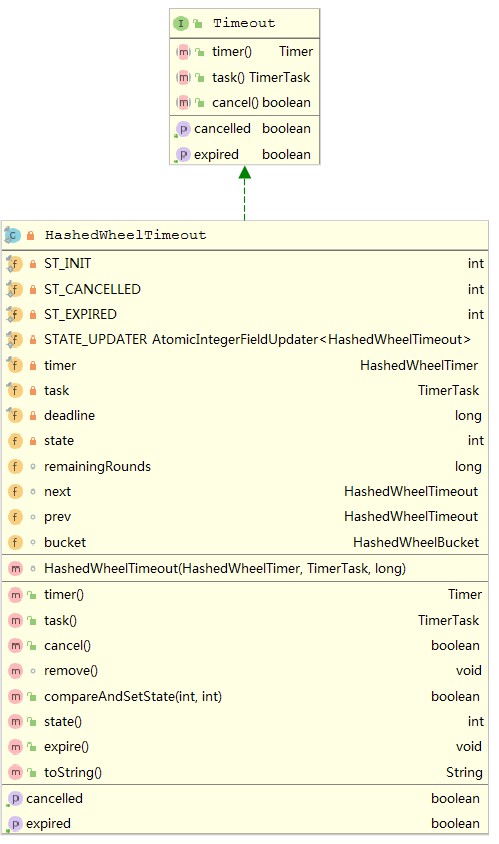
我们传进来的任务就是它的task属性,然后会根据当前时间、过期时间和任务开始时间计算出它的deadline,同事计算出它剩余的轮数(remainingRounds)。
任务执行实际上是调用的它的expire方法。当expire的时候会调用具体的业务任务的run方法。
那HashedWheelTimer的expire方法是什么时候被执行的呢。上面也也说到在HashedWheelTimer中有一个workThread,这里面会运行work。能读到这个地方来的人应该很少了吧,不过能到这个地方你是幸运的,因为work这个类也就是实现这个算法中最核心的一个类了,先来概览一下这个类 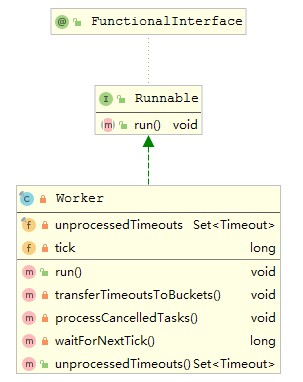
这个类实现了Runable接口,也就说是一个线程类,然后它会被workTread调用执行启动。
transferTimeoutsToBuckets 把新加入的定时任务从阻塞队列中取出然后放到相应的bucket中
processCancelledTasks 把取消的定时任务从阻塞队列中取出,然后从相应的bucket中remove掉
waitForNextTick 指针往下走的方法,经过一个时间单位,指针会往下走,指向下一个bucket
run方法会一直循环从阻塞队列中取值,然后放到bucket中,指针循环往下走,对remainderRounds对于0的任务进行执行,不是0的减一
do {
/**
* 里面是一个Thread.sleep操作,模拟指针一步一步往下走的操作。
*/
final long deadline = waitForNextTick();
if (deadline > 0) {
/**
* 计算任务将要落到槽位,这本应该是个取模运算,不过这里用了一个小技巧,就是把取模运算换为了“按位与”,因为“按位与”要比取模运算快的多,
* 这个技巧就是当mast的值为2的n次方-1时,能达到取模的效果。这里要感谢一下王洪涛的分享
*/
int idx = (int) (tick & mask);
processCancelledTasks();
//取到具体bucket,然后把任务放从阻塞队列中拿到,放到bucket中
HashedWheelBucket bucket =
wheel[idx];
transferTimeoutsToBuckets();
//这里面会调用所有HashedWheelTimeout的方法,就是看他的剩余的轮数是不是大于0,如果是的话则会被执行,不是的话剩余轮数减1
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);当然HashedWheelTimer这个类属于全内存任务计算,通常在我们真正的业务中,是不会把这些任务直接放到jvm内存中的,要不然重启之后任务不都会消失了么,这样我们需要重写HashedWheelTimer,只需要对它任务的添加和获取进行重写到相应的持久化中间件中即可(例如数据库或者es等等)
[1][redis的发布订阅缺陷]
[[2]][Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil] [Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil]: http://www.cs.columbia.edu/~nahum/w6998/papers/sosp87-timing-wheels.pdf "Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facil"
[[3]][Hashed and Hierarchical Timing Wheels] [Hashed and Hierarchical Timing Wheels]: http://www.cse.wustl.edu/~cdgill/courses/cs6874/TimingWheels.ppt "Hashed and Hierarchical Timing Wheels"
感谢各位的阅读,以上就是“HashedWheelTimer的作用是什么”的内容了,经过本文的学习后,相信大家对HashedWheelTimer的作用是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





