MindSporeиҮӘе®ҡд№үжЁЎеһӢжҚҹеӨұеҮҪж•°зҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іMindSporeиҮӘе®ҡд№үжЁЎеһӢжҚҹеӨұеҮҪж•°зҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒжҠҖжңҜиғҢжҷҜ
жҚҹеӨұеҮҪж•°жҳҜжңәеҷЁеӯҰд№ дёӯзӣҙжҺҘеҶіе®ҡи®ӯз»ғз»“жһңеҘҪеқҸзҡ„дёҖдёӘжЁЎеқ—пјҢиҜҘеҮҪж•°з”ЁдәҺе®ҡд№үи®Ўз®—еҮәжқҘзҡ„з»“жһңжҲ–иҖ…жҳҜзҘһз»ҸзҪ‘з»ңз»ҷеҮәзҡ„жҺЁжөӢз»“и®әдёҺжӯЈзЎ®з»“жһңзҡ„еҒҸе·®зЁӢеәҰпјҢеҒҸе·®зҡ„и¶ҠеӨҡпјҢе°ұиЎЁжҳҺеҜ№еә”зҡ„еҸӮж•°и¶Ҡе·®гҖӮиҖҢжҚҹеӨұеҮҪж•°зҡ„еҸҰдёҖдёӘйҮҚиҰҒжҖ§еңЁдәҺдјҡеҪұе“ҚеҲ°дјҳеҢ–еҮҪж•°зҡ„收ж•ӣжҖ§пјҢеҰӮжһңжҚҹеӨұеҮҪж•°зҡ„жҢҮж•°е®ҡд№үзҡ„еӨӘй«ҳпјҢзЁҚжңүеҸӮж•°жіўеҠЁе°ұеҜјиҮҙз»“жһңзҡ„е·ЁеӨ§жіўеҠЁзҡ„иҜқпјҢйӮЈд№Ҳи®ӯз»ғе’ҢдјҳеҢ–е°ұеҫҲйҡҫ收ж•ӣгҖӮдёҖиҲ¬жҲ‘们常用зҡ„жҚҹеӨұеҮҪж•°жҳҜMSEпјҲеқҮж–№иҜҜе·®пјүе’ҢMAEпјҲе№іеқҮж ҮеҮҶе·®пјүзӯүгҖӮйӮЈд№ҲиҝҷйҮҢжҲ‘们е°қиҜ•еңЁMindSporeдёӯеҺ»иҮӘе®ҡд№үдёҖдәӣжҚҹеӨұеҮҪж•°пјҢеҸҜз”ЁдәҺйҖӮеә”иҮӘе·ұзҡ„зү№ж®ҠеңәжҷҜгҖӮ
дәҢгҖҒMindSporeеҶ…зҪ®зҡ„жҚҹеӨұеҮҪж•°
еҲҡжүҚжҸҗеҲ°зҡ„MSEе’ҢMAEзӯүеёёи§ҒжҚҹеӨұеҮҪж•°пјҢMindSporeдёӯжҳҜжңүеҶ…зҪ®зҡ„пјҢйҖҡиҝҮnet_loss = nn.loss.MSELoss()еҚіеҸҜи°ғз”ЁпјҢеҶҚдј е…ҘModelдёӯиҝӣиЎҢи®ӯз»ғпјҢе…·дҪ“дҪҝз”Ёж–№жі•еҸҜд»ҘеҸӮиҖғеҰӮдёӢжӢҹеҗҲдёҖдёӘйқһзәҝжҖ§еҮҪж•°зҡ„жЎҲдҫӢпјҡ
# test_nonlinear.py
from mindspore import context
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
import mindspore as ms
ms.common.set_seed(0)
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 10
repeat_number = 10
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
start_time = time.time()
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
net_loss = nn.loss.MSELoss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, net_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))и®ӯз»ғзҡ„з»“жһңеҰӮдёӢпјҡ
epoch: 1 step: 160, loss is 2.5267093
Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[1.0694231 0.12706374]]
Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [5.186701]
The total time cost is: 8.412306308746338s
жңҖз»ҲдјҳеҢ–еҮәжқҘзҡ„lossеҖјжҳҜ2.5пјҢдёҚиҝҮеңЁжҚҹеӨұеҮҪж•°е®ҡд№үдёҚеҗҢзҡ„жғ…еҶөдёӢпјҢеҚ•зәҜеҸӘзңӢlossеҖјжҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮжүҖд»ҘйҖҡеёёжҳҜеӨ§е®¶з»ҹдёҖе®ҡдёҖдёӘжөӢиҜ•зҡ„ж ҮеҮҶпјҢжҜ”еҰӮеӨ§е®¶йғҪз”ЁMAEжқҘиЎЎйҮҸжңҖз»Ҳи®ӯз»ғеҮәжқҘзҡ„жЁЎеһӢзҡ„еҘҪеқҸпјҢдҪҶжҳҜдёӯй—ҙи®ӯз»ғзҡ„иҝҮзЁӢдёҚдёҖе®ҡйҮҮз”ЁMAEжқҘдҪңдёәжҚҹеӨұеҮҪж•°гҖӮ
дёүгҖҒиҮӘе®ҡд№үжҚҹеӨұеҮҪж•°
з”ұдәҺpythonиҜӯиЁҖзҡ„зҒөжҙ»жҖ§пјҢдҪҝеҫ—жҲ‘们еҸҜд»Ҙ继жүҝеҹәжң¬зұ»е’ҢеҮҪж•°пјҢеҸӘиҰҒдҪҝз”Ёmindsporeе…Ғи®ёиҢғеӣҙеҶ…зҡ„з®—еӯҗпјҢе°ұеҸҜд»Ҙе®һзҺ°иҮӘе®ҡд№үзҡ„жҚҹеӨұеҮҪж•°гҖӮжҲ‘们е…ҲзңӢдёҖдёӘз®ҖеҚ•зҡ„жЎҲдҫӢпјҢжҡӮж—¶е°ҶжҲ‘们иҮӘе®ҡд№үзҡ„жҚҹеӨұеҮҪж•°е‘ҪеҗҚдёәL1Lossпјҡ
# test_nonlinear.py
from mindspore import context
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
import mindspore as ms
import mindspore.ops as ops
from mindspore.nn.loss.loss import Loss
ms.common.set_seed(0)
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 10
repeat_number = 10
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
start_time = time.time()
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
class L1Loss(Loss):
def __init__(self, reduction="mean"):
super(L1Loss, self).__init__(reduction)
self.abs = ops.Abs()
def construct(self, base, target):
x = self.abs(base - target)
return self.get_loss(x)
user_loss = L1Loss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, user_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))иҝҷйҮҢиҮӘе·ұе®ҡд№үзҡ„еҶ…е®№е®һйҷ…дёҠжңүдёӨдёӘйғЁеҲҶпјҢдёҖдёӘжҳҜconstructеҮҪж•°дёӯзҡ„и®Ўз®—з»“жһңзҡ„еҮҪж•°пјҢжҜ”еҰӮиҝҷйҮҢдҪҝз”Ёзҡ„жҳҜжұӮз»қеҜ№еҖјгҖӮеҸҰеӨ–дёҖдёӘе®ҡд№үзҡ„йғЁеҲҶжҳҜreductionеҸӮж•°пјҢжҲ‘们д»Һmindsporeзҡ„жәҗз ҒдёӯеҸҜд»ҘзңӢеҲ°пјҢиҝҷдёӘreductionеҮҪж•°еҸҜд»ҘеҶіе®ҡи°ғз”Ёе“ӘдёҖз§Қи®Ўз®—ж–№жі•пјҢе®ҡд№үеҘҪзҡ„жңүе№іеқҮеҖјгҖҒжұӮе’ҢгҖҒдҝқжҢҒдёҚеҸҳдёүз§Қзӯ–з•ҘгҖӮ
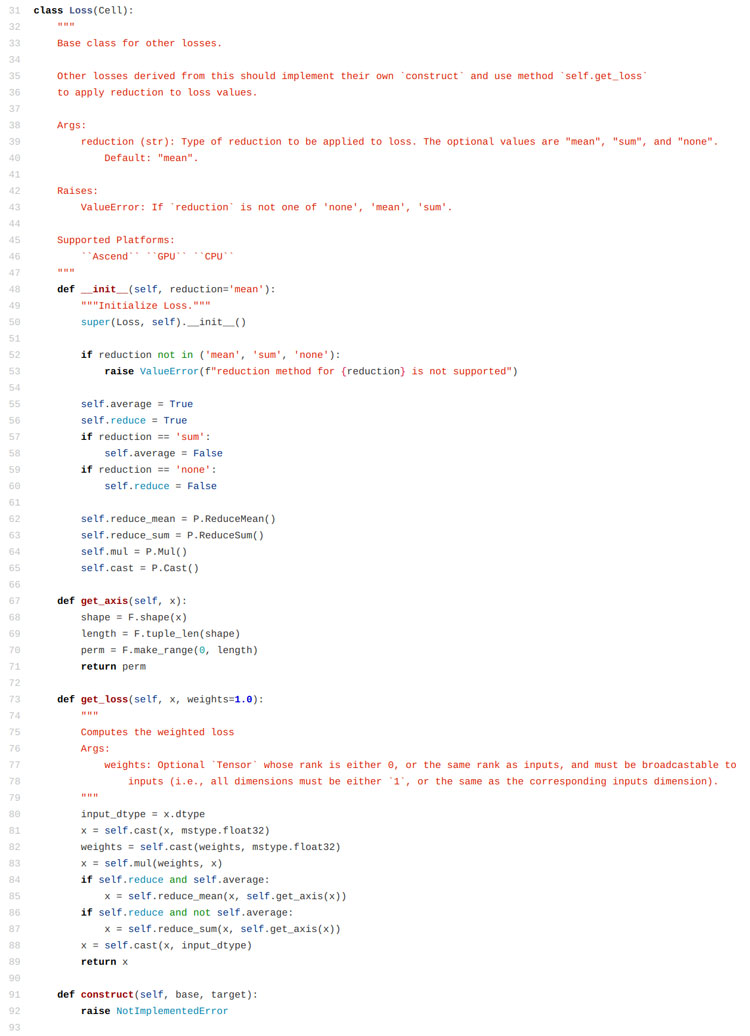
йӮЈд№ҲжңҖеҗҺзңӢдёӢиҮӘе®ҡд№үзҡ„иҝҷдёӘжҚҹеӨұеҮҪж•°зҡ„иҝҗиЎҢз»“жһңпјҡ
epoch: 1 step: 160, loss is 1.8300734
Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[ 1.2687287 -0.09565887]]
Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [3.7297544]
The total time cost is: 7.0749146938323975s
иҝҷйҮҢдёҚеҝ…еӨӘеңЁд№Һlossзҡ„еҖјпјҢеӣ дёәеүҚйқўд№ҹжҸҗеҲ°дәҶпјҢдёҚеҗҢзҡ„жҚҹеӨұеҮҪж•°жЎҶжһ¶дёӢпјҢи®Ўз®—еҮәжқҘзҡ„еҖје°ұжҳҜдёҚдёҖж ·зҡ„пјҢе°ҸдёҖзӮ№еӨ§дёҖзӮ№е№¶жІЎжңүеӨӘеӨ§ж„Ҹд№үпјҢжңҖз»ҲиҝҳжҳҜйңҖиҰҒеӨ§е®¶з»ҹдёҖдёҖдёӘж ҮеҮҶжүҚиғҪеӨҹиҝӣиЎҢеҫҲеҘҪзҡ„иЎЎйҮҸе’ҢеҜ№жҜ”гҖӮ
еӣӣгҖҒиҮӘе®ҡд№үе…¶д»–з®—еӯҗ
иҝҷйҮҢжҲ‘们仅仅жҳҜжӣҝжҚўдәҶдёҖдёӘabsзҡ„з®—еӯҗдёәsquareзҡ„з®—еӯҗпјҢд»ҺжұӮз»қеҜ№еҖјеҸҳеҢ–еҲ°жұӮеқҮж–№иҜҜе·®пјҢиҝҷйҮҢеҸӘжҳҜдҝ®ж”№дәҶдёҖдёӘз®—еӯҗпјҢеҶ…е®№иҫғдёәз®ҖеҚ•пјҡ
# test_nonlinear.py
from mindspore import context
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
import mindspore as ms
import mindspore.ops as ops
from mindspore.nn.loss.loss import Loss
ms.common.set_seed(0)
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 10
repeat_number = 10
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
start_time = time.time()
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
class L1Loss(Loss):
def __init__(self, reduction="mean"):
super(L1Loss, self).__init__(reduction)
self.square = ops.Square()
def construct(self, base, target):
x = self.square(base - target)
return self.get_loss(x)
user_loss = L1Loss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, user_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))е…ідәҺжӣҙеӨҡзҡ„з®—еӯҗеҶ…е®№пјҢеҸҜд»ҘеҸӮиҖғдёӢиҝҷдёӘй“ҫжҺҘ
(https://www.mindspore.cn/doc/api_python/zh-CN/r1.2/mindspore/mindspore.ops.html)дёӯзҡ„еҶ…е®№пјҢ
дёҠиҝ°д»Јз Ғзҡ„иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
epoch: 1 step: 160, loss is 2.5267093
Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[1.0694231 0.12706374]]
Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [5.186701]
The total time cost is: 6.87545919418335s
еҸҜд»Ҙд»ҺиҝҷдёӘз»“жһңдёӯеҸ‘зҺ°зҡ„жҳҜпјҢи®Ўз®—еҮәжқҘзҡ„з»“жһңи·ҹжңҖејҖе§ӢдҪҝз”Ёзҡ„еҶ…зҪ®зҡ„MSELossз»“жһңжҳҜдёҖж ·зҡ„пјҢиҝҷжҳҜеӣ дёәжҲ‘们иҮӘе®ҡд№үзҡ„иҝҷдёӘжұӮжҚҹеӨұеҮҪж•°зҡ„еҪўејҸдёҺеҶ…зҪ®зҡ„MSEжҳҜеҗ»еҗҲзҡ„гҖӮ
дә”гҖҒеӨҡеұӮз®—еӯҗзҡ„еә”з”Ё
дёҠйқўзҡ„дёӨдёӘдҫӢеӯҗйғҪжҳҜз®ҖеҚ•зҡ„иҜҙжҳҺдәҶдёҖдёӢйҖҡиҝҮеҚ•дёӘз®—еӯҗжһ„йҖ зҡ„жҚҹеӨұеҮҪж•°пјҢе…¶е®һеҰӮжһңжҳҜдёҖдёӘеӨҚжқӮзҡ„жҚҹеӨұеҮҪж•°пјҢд№ҹеҸҜд»ҘйҖҡиҝҮеӨҡдёӘз®—еӯҗзҡ„з»„еҗҲж“ҚдҪңжқҘиҝӣиЎҢе®һзҺ°пјҡ
# test_nonlinear.py
from mindspore import context
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
import mindspore as ms
import mindspore.ops as ops
from mindspore.nn.loss.loss import Loss
ms.common.set_seed(0)
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 10
repeat_number = 10
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
start_time = time.time()
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
class L1Loss(Loss):
def __init__(self, reduction="mean"):
super(L1Loss, self).__init__(reduction)
self.square = ops.Square()
def construct(self, base, target):
x = self.square(self.square(base - target))
return self.get_loss(x)
user_loss = L1Loss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, user_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))иҝҷйҮҢдҪҝз”Ёзҡ„еҮҪж•°жҳҜдёӨдёӘе№іж–№з®—еӯҗпјҢд№ҹе°ұжҳҜеӣӣж¬Ўж–№зҡ„еқҮж–№иҜҜе·®пјҢиҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
epoch: 1 step: 160, loss is 16.992222
Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[0.14460069 0.32045612]]
Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [5.6676607]
The total time cost is: 7.253541946411133s
еңЁе®һйҷ…зҡ„иҝҗз®—иҝҮзЁӢдёӯпјҢжҲ‘们иӮҜе®ҡдёҚиғҪеӨҹиҜҙжҸҗеҚҮжҚҹеӨұеҮҪж•°зҡ„е№Ӯж¬Ўе°ұдёҖе®ҡиғҪеӨҹжҸҗеҚҮз»“жһңзҡ„дјҳеҠЈпјҢдҪҶжҳҜйҖҡиҝҮеӨҡз§ҚеҹәзЎҖз®—еӯҗзҡ„з»„еҗҲпјҢзҗҶи®әдёҠиҜҙжҲ‘们еңЁдёҖе®ҡзҡ„иҜҜе·®е…Ғи®ёиҢғеӣҙеҶ…пјҢжҳҜеҸҜд»Ҙе®һзҺ°д»»ж„Ҹзҡ„дёҖдёӘжҚҹеӨұеҮҪж•°пјҲйҖҡиҝҮжі°еӢ’еұ•ејҖеҸ–жҲӘж–ӯйЎ№пјүзҡ„гҖӮ
е…ӯгҖҒйҮҚе®ҡд№үreduction
ж–№жүҚжҸҗеҲ°иҝҷйҮҢйқўиҮӘе®ҡд№үжҚҹеӨұеҮҪж•°зҡ„дёӨдёӘйҮҚзӮ№пјҢдёҖдёӘжҳҜдёҠйқўдёүдёӘз« иҠӮдёӯжүҖжј”зӨәзҡ„constructеҮҪж•°зҡ„йҮҚеҶҷпјҢиҝҷйғЁеҲҶе®һйҷ…дёҠжҳҜйҮҚж–°и®ҫи®ЎжҚҹеӨұеҮҪж•°зҡ„еҮҪж•°иЎЁиҫҫејҸгҖӮеҸҰдёҖдёӘжҳҜreductionзҡ„иҮӘе®ҡд№үпјҢиҝҷйғЁеҲҶе…ізі»еҲ°дёҚеҗҢзҡ„еҚ•зӮ№жҚҹеӨұеҮҪж•°еҖјд№Ӣй—ҙзҡ„е…ізі»гҖӮдёҫдёӘдҫӢеӯҗжқҘиҜҙпјҢеҰӮжһңжҲ‘们е°Ҷreductionи®ҫзҪ®дёәжұӮе’ҢпјҢйӮЈд№Ҳget_loss()иҝҷйғЁеҲҶзҡ„еҮҪж•°еҶ…е®№е°ұжҳҜжҠҠжүҖжңүзҡ„еҚ•зӮ№еҮҪж•°еҖјеҠ иө·жқҘиҝ”еӣһдёҖдёӘжңҖз»Ҳзҡ„еҖјпјҢжұӮе№іеқҮеҖјд№ҹжҳҜзұ»дјјзҡ„гҖӮйӮЈд№ҲйҖҡиҝҮиҮӘе®ҡд№үдёҖдёӘж–°зҡ„get_loss()еҮҪж•°пјҢжҲ‘们е°ұеҸҜд»Ҙе®һзҺ°жӣҙеҠ зҒөжҙ»зҡ„дёҖдәӣж“ҚдҪңпјҢжҜ”еҰӮжҲ‘们еҸҜд»ҘйҖүжӢ©е°ҶжүҖжңүзҡ„з»“жһңд№ҳиө·жқҘжұӮз§ҜиҖҢдёҚжҳҜжұӮе’ҢпјҲеҸӘжҳҜдёҫдёӘдҫӢеӯҗпјҢеӨ§йғЁеҲҶжғ…еҶөдёӢдёҚдјҡиҝҷд№Ҳж“ҚдҪңпјүгҖӮеңЁpythonдёӯиҰҒйҮҚеҶҷиҝҷдёӘеҮҪж•°д№ҹе®№жҳ“пјҢе°ұжҳҜеңЁз»§жүҝзҲ¶зұ»зҡ„иҮӘе®ҡд№үзұ»дёӯе®ҡд№үдёҖдёӘеҗҢеҗҚеҮҪж•°еҚіеҸҜпјҢдҪҶжҳҜжіЁж„ҸжҲ‘们жңҖеҘҪжҳҜдҝқз•ҷеҺҹеҮҪж•°дёӯзҡ„дёҖдәӣеҶ…е®№пјҢеңЁеҺҹеҶ…е®№зҡ„еҹәзЎҖдёҠеҠ дёҖдәӣдёңиҘҝпјҢеҶ’然改模еқ—жңүеҸҜиғҪеҜјиҮҙдёҚеҘҪе®ҡдҪҚзҡ„иҝҗиЎҢжҠҘй”ҷгҖӮ
# test_nonlinear.py
from mindspore import context
import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor
import mindspore as ms
import mindspore.ops as ops
from mindspore.nn.loss.loss import Loss
ms.common.set_seed(0)
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32)
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data
data_number = 160
batch_number = 10
repeat_number = 10
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02)
def construct(self, x):
x = self.fc(x)
return x
start_time = time.time()
net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
class L1Loss(Loss):
def __init__(self, reduction="mean", config=True):
super(L1Loss, self).__init__(reduction)
self.square = ops.Square()
self.config = config
def construct(self, base, target):
x = self.square(base - target)
return self.get_loss(x)
def get_loss(self, x, weights=1.0):
print ('The data shape of x is: ', x.shape)
input_dtype = x.dtype
x = self.cast(x, ms.common.dtype.float32)
weights = self.cast(weights, ms.common.dtype.float32)
x = self.mul(weights, x)
if self.reduce and self.average:
x = self.reduce_mean(x, self.get_axis(x))
if self.reduce and not self.average:
x = self.reduce_sum(x, self.get_axis(x))
if self.config:
x = self.reduce_mean(x, self.get_axis(x))
weights = self.cast(-1.0, ms.common.dtype.float32)
x = self.mul(weights, x)
x = self.cast(x, input_dtype)
return x
user_loss = L1Loss()
optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
model = Model(net, user_loss, optim)
epoch = 1
model.train(epoch, ds_train, callbacks=[LossMonitor(10)], dataset_sink_mode=True)
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
print ('The total time cost is: {}s'.format(time.time() - start_time))дёҠиҝ°д»Јз Ғе°ұжҳҜдёҖдёӘз®ҖеҚ•зҡ„жЎҲдҫӢпјҢиҝҷйҮҢжҲ‘们жүҖеҒҡзҡ„ж“ҚдҪңпјҢд»…д»…жҳҜжҠҠд№ӢеүҚеқҮж–№иҜҜе·®зҡ„жұӮе’Ңж”№жҲҗдәҶжұӮе’Ңд№ӢеҗҺеҸ–иҙҹж•°гҖӮиҝҳжҳҜйңҖиҰҒеҶҚејәи°ғдёҖйҒҚзҡ„жҳҜпјҢиҷҪ然жҲ‘们е®ҡд№үзҡ„еҮҪж•°жҳҜйқһеёёз®ҖеҚ•зҡ„еҶ…е®№пјҢдҪҶжҳҜеҖҹз”ЁиҝҷдёӘж–№жі•пјҢжҲ‘们еҸҜд»ҘжӣҙеҠ зҒөжҙ»зҡ„еҺ»жҢүз…§иҮӘе·ұзҡ„и®ҫи®Ўе®ҡд№үдёҖдәӣе®ҡеҲ¶еҢ–зҡ„жҚҹеӨұеҮҪж•°гҖӮдёҠиҝ°д»Јз Ғзҡ„жү§иЎҢз»“жһңеҰӮдёӢпјҡ
The data shape of x is:
(10, 10, 1)
...
The data shape of x is:
(10, 10, 1)
epoch: 1 step: 160, loss is -310517200.0
Parameter (name=fc.weight, shape=(1, 2), dtype=Float32, requires_grad=True) [[-6154.176 667.4569]]
Parameter (name=fc.bias, shape=(1,), dtype=Float32, requires_grad=True) [-16418.32]
The total time cost is: 6.681089878082275s
дёҖе…ұжү“еҚ°дәҶ160дёӘThe data shape of x is...пјҢиҝҷжҳҜеӣ дёәжҲ‘们еңЁеҲ’еҲҶиҫ“е…Ҙзҡ„ж•°жҚ®йӣҶзҡ„ж—¶еҖҷпјҢйҖүжӢ©дәҶе°Ҷ160дёӘж•°жҚ®еҲ’еҲҶдёәжҜҸдёӘbatchеҗ«10дёӘе…ғзҙ зҡ„жЁЎеқ—пјҢйӮЈд№ҲдёҖе…ұе°ұжңү16дёӘbatchпјҢеҸҲеҜ№иҝҷ16дёӘbatchйҮҚеӨҚ10ж¬ЎпјҢйӮЈд№Ҳе°ұжҳҜдёҖе…ұжңү160дёӘbatchпјҢи®Ўз®—жҚҹеӨұеҮҪж•°ж—¶жҳҜд»ҘbatchдёәеҚ•дҪҚзҡ„пјҢдҪҶжҳҜеҰӮжһңеҸӘжҳҜи®Ўз®—жұӮе’ҢжҲ–иҖ…жұӮе№іеқҮеҖјзҡ„иҜқпјҢдёҚз®ЎеҲ’еҲҶеӨҡе°‘дёӘbatchз»“жһңйғҪжҳҜдёҖиҮҙзҡ„гҖӮ
д»Ҙ
е…ідәҺвҖңMindSporeиҮӘе®ҡд№үжЁЎеһӢжҚҹеӨұеҮҪж•°зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





