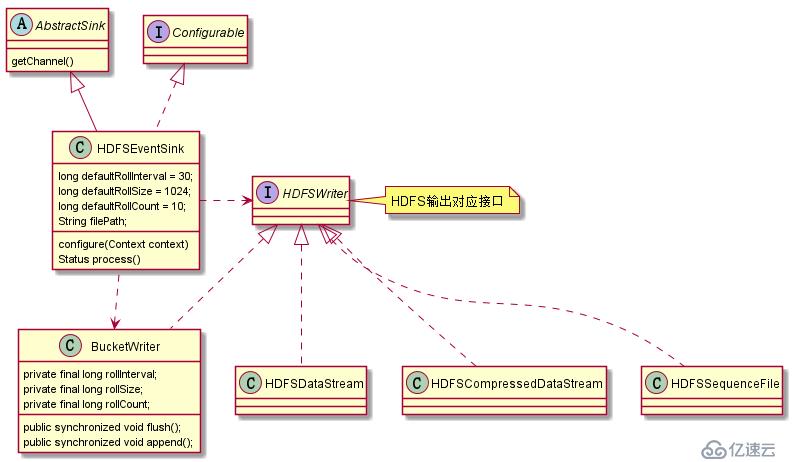
HDFSSink组件中,主要由HDFSEventSink,BucketWriter,HDFSWriter几个类构成。
其中HDFSEventSink主要功能呢是判定Sink的配置条件是否合法,并负责从Channel中获取events,通过解析event的header信息决定event对应的BucketWriter。
BucketWriter负责按照rollCount,rollSize等条件在HDFS端生成(roll)文件,通过配置文件配置的文件数据格式以及序列化的方式,在每个BucetWriter同一处理。
HDFSWriter作为接口,其具体实现有HDFSSequenceFile,HDFSDataStream,HDFSCompressedDataStream这三种
HDFSSink功能中关键类类图
HDFSEventSink类
走通HDFSEventSink之前,肯定要对其中配置参数有了解(Flume-HDFSSink配置参数说明)
1、configure()方法中,从配置文件中获取filePath,fileName等信息,具体参数含义可以参考(Flume-HDFSSink配置参数说明)
2、start()方法,初始化固定大小线程池callTimeoutPool, 周期执行线程池timedRollerPool,以及sfWriters,并启动sinkCounter
callTimeoutPool
timedRollerPool,周期执行线程池中主要有HDFS文件重命名的线程(根据retryInterval),达到生成文件要求进行roll操作的线程(根据idleTimeout),关闭闲置文件的线程等(rollInterval)
sfWriters sfWriters实际是一个LinkedHashMap的实现类,通过重写removeEldestEntry方法,将最久未使用的writer移除,保证sfWriters中能够维护一个固定大小(maxOpenFiles)的最大打开文件数
sinkCounter sink组件监控指标的计数器
3、process() 方法是HDFSEventSink中最主要的逻辑(部分关键节点通过注释写到代码中),
process()方法中获取到Channel,
并按照batchSize大小循环从Channel中获取event,通过解析event得到event的header等信息,确定该event的HDFS目的路径以及目的文件名
每个event可能对应不同的bucketWriter和hdfswriter,将每个event添加到相应的writer中
当event个数达到batchSize个数后,writer进行flush,同时提交事务
其中bucketWriter负责生成(roll)文件的方式,处理文件格式以及序列化等逻辑
其中hdfsWriter具体实现有"SequenceFile","DataStream","CompressedStream";三种,用户根据hdfs.fileType参数确定具体hdfsWriter的实现
public Status process() throws EventDeliveryException {
Channel channel = getChannel(); //调用父类getChannel方法,建立Channel与Sink之间的连接
Transaction transaction = channel.getTransaction();//每次batch提交都建立在一个事务上
transaction.begin();
try {
Set<BucketWriter> writers = new LinkedHashSet<>();
int txnEventCount = 0;
for (txnEventCount = 0; txnEventCount < batchSize; txnEventCount++) {
Event event = channel.take();//从Channel中取出event
if (event == null) {//没有新的event的时候,则不需要按照batchSize循环取
break;
}
// reconstruct the path name by substituting place holders
// 在配置文件中会有“a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S”这样的%表示的变量
// 解析配置文件中的变量构造realPath 和 realName
String realPath = BucketPath.escapeString(filePath, event.getHeaders(),
timeZone, needRounding, roundUnit, roundValue, useLocalTime);
String realName = BucketPath.escapeString(fileName, event.getHeaders(),
timeZone, needRounding, roundUnit, roundValue, useLocalTime);
String lookupPath = realPath + DIRECTORY_DELIMITER + realName;
BucketWriter bucketWriter;
HDFSWriter hdfsWriter = null;
WriterCallback closeCallback = new WriterCallback() {
@Override
public void run(String bucketPath) {
LOG.info("Writer callback called.");
synchronized (sfWritersLock) {
sfWriters.remove(bucketPath);//sfWriters以LRU方式维护了一个maxOpenFiles大小的map.始终保持最多打开文件个数
}
}
};
synchronized (sfWritersLock) {
bucketWriter = sfWriters.get(lookupPath);
// we haven't seen this file yet, so open it and cache the handle
if (bucketWriter == null) {
hdfsWriter = writerFactory.getWriter(fileType);//通过工厂获取文件类型,其中包括"SequenceFile","DataStream","CompressedStream";
bucketWriter = initializeBucketWriter(realPath, realName,
lookupPath, hdfsWriter, closeCallback);
sfWriters.put(lookupPath, bucketWriter);
}
}
// Write the data to HDFS
try {
bucketWriter.append(event);
} catch (BucketClosedException ex) {
LOG.info("Bucket was closed while trying to append, " +
"reinitializing bucket and writing event.");
hdfsWriter = writerFactory.getWriter(fileType);
bucketWriter = initializeBucketWriter(realPath, realName,
lookupPath, hdfsWriter, closeCallback);
synchronized (sfWritersLock) {
sfWriters.put(lookupPath, bucketWriter);
}
bucketWriter.append(event);
}
// track the buckets getting written in this transaction
if (!writers.contains(bucketWriter)) {
writers.add(bucketWriter);
}
}
if (txnEventCount == 0) {
sinkCounter.incrementBatchEmptyCount();
} else if (txnEventCount == batchSize) {
sinkCounter.incrementBatchCompleteCount();
} else {
sinkCounter.incrementBatchUnderflowCount();
}
// flush all pending buckets before committing the transaction
for (BucketWriter bucketWriter : writers) {
bucketWriter.flush();
}
transaction.commit();
if (txnEventCount < 1) {
return Status.BACKOFF;
} else {
sinkCounter.addToEventDrainSuccessCount(txnEventCount);
return Status.READY;
}
} catch (IOException eIO) {
transaction.rollback();
LOG.warn("HDFS IO error", eIO);
return Status.BACKOFF;
} catch (Throwable th) {
transaction.rollback();
LOG.error("process failed", th);
if (th instanceof Error) {
throw (Error) th;
} else {
throw new EventDeliveryException(th);
}
} finally {
transaction.close();
}
}BucketWriter
flush() 方法:
BucketWriter中维护了一个batchCounter,在这个batchCounter大小不为0的时候会进行doFlush(), doFlush()主要就是对batch中的event进行序列化和输出流flush操作,最终结果就是将events写入HDFS中。
如果用户设置了idleTimeout参数不为0,在doFlush()操作之后,会往定时执行线程池中添加一个任务,该关闭当前连接HDFS的输出对象HDFSWriter,执行时间间隔为idleTimeout,并将这个延迟调度的任务赋值给idleFuture变量。
append()方法:
在介绍flush()方法中,会介绍一个idleFuture变量对应的功能,在append()方法执行前首先会检查idleFuture任务是否执行完毕,如果没有执行完成会设置一个超时时间callTimeout等待该进程完成,然后再进行append之后的操作。这样做主要是为了防止关闭HdfsWriter的过程中还在往HDFS中append数据,在append一半时候,HdfsWriter关闭了。
之后,在正是append()之前,又要首先检查当前是否存在HDFSWirter可用于append操作,如果没有调用open()方法。
每次将event往hdfs中append的时候都需要对rollCount,rollSize两个参数进行检查,在满足这两个参数条件的情况下,就需要将临时文件重命名为(roll)正式的HDFS文件。之后,重新再open一个hdfswriter,往这个hdfswriter中append每个event,当event个数达到batchSize时,进行flush操作。
public synchronized void append(final Event event) throws IOException, InterruptedException {
checkAndThrowInterruptedException();
// idleFuture是ScheduledFuture实例,主要功能关闭当前HDFSWriter,在append event之前需要判断
// idleFuture是否已经执行完成,否则会造成在append一半的时候 hdfswriter被关闭
if (idleFuture != null) {
idleFuture.cancel(false);
// There is still a small race condition - if the idleFuture is already
// running, interrupting it can cause HDFS close operation to throw -
// so we cannot interrupt it while running. If the future could not be
// cancelled, it is already running - wait for it to finish before
// attempting to write.
if (!idleFuture.isDone()) {
try {
idleFuture.get(callTimeout, TimeUnit.MILLISECONDS);
} catch (TimeoutException ex) {
LOG.warn("Timeout while trying to cancel closing of idle file. Idle" +
" file close may have failed", ex);
} catch (Exception ex) {
LOG.warn("Error while trying to cancel closing of idle file. ", ex);
}
}
idleFuture = null;
}
// If the bucket writer was closed due to roll timeout or idle timeout,
// force a new bucket writer to be created. Roll count and roll size will
// just reuse this one
if (!isOpen) {
if (closed) {
throw new BucketClosedException("This bucket writer was closed and " +
"this handle is thus no longer valid");
}
open();
}
// 检查rollCount,rollSize两个roll文件的参数,判断是否roll出新文件
if (shouldRotate()) {
boolean doRotate = true;
if (isUnderReplicated) {
if (maxConsecUnderReplRotations > 0 &&
consecutiveUnderReplRotateCount >= maxConsecUnderReplRotations) {
doRotate = false;
if (consecutiveUnderReplRotateCount == maxConsecUnderReplRotations) {
LOG.error("Hit max consecutive under-replication rotations ({}); " +
"will not continue rolling files under this path due to " +
"under-replication", maxConsecUnderReplRotations);
}
} else {
LOG.warn("Block Under-replication detected. Rotating file.");
}
consecutiveUnderReplRotateCount++;
} else {
consecutiveUnderReplRotateCount = 0;
}
if (doRotate) {
close();
open();
}
}
// write the event
try {
sinkCounter.incrementEventDrainAttemptCount();// sinkCounter统计metrix
callWithTimeout(new CallRunner<Void>() {
@Override
public Void call() throws Exception {
writer.append(event); //writer是通过配置参数hdfs.fileType创建的HDFSWriter实现
return null;
}
});
} catch (IOException e) {
LOG.warn("Caught IOException writing to HDFSWriter ({}). Closing file (" +
bucketPath + ") and rethrowing exception.",
e.getMessage());
try {
close(true);
} catch (IOException e2) {
LOG.warn("Caught IOException while closing file (" +
bucketPath + "). Exception follows.", e2);
}
throw e;
}
// update statistics
processSize += event.getBody().length;
eventCounter++;
batchCounter++;
if (batchCounter == batchSize) {
flush();
}
}亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



