这篇文章将为大家详细讲解有关c语言中哈希表的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
当我们在一个 链表 或者 顺序表 中 查找 一个数据元素 是否存在 的时候,唯一的方法就是遍历整个表,这种方法称为 线性枚举。

如果这时候,顺序表是有序的情况下,我们可以采用折半的方式去查找,这种方法称为 二分枚举。
线性枚举 的时间复杂度为 O ( n ) O(n) O(n)。二分枚举 的时间复杂度为 O(log2n)。是否存在更快速的查找方式呢?这就是本要介绍的一种新的数据结构 —— 哈希表。
由于它不是顺序结构,所以很多数据结构书上称之为 散列表,下文会统一采用 哈希表 的形式来说明,作为读者,只需要知道这两者是同一种数据结构即可。
我们把需要查找的数据,通过一个 函数映射,找到 存储数据的位置 的过程称为 哈希。这里涉及到几个概念:
a)需要 查找的数据 本身被称为 关键字;
b)通过 函数映射 将 关键字 变成一个 哈希值 的过程中,这里的 函数 被称为 哈希函数;
c)生成 哈希值 的过程过程可能产生冲突,需要进行 冲突解决;
d)解决完冲突以后,实际 存储数据的位置 被称为 哈希地址,通俗的说,它就是一个数组下标;
e)存储所有这些数据的数据结构就是 哈希表,程序实现上一般采用数组实现,所以又叫 哈希数组。整个过程如下图所示:

为了方便下标索引,哈希表 的底层实现结构是一个数组,数组类型可以是任意类型,每个位置被称为一个槽。如下图所示,它代表的是一个长度为 8 的 哈希表,又叫 哈希数组。
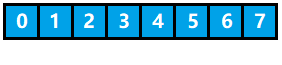
关键字 是哈希数组中的元素,可以是任意类型的,它可以是整型、浮点型、字符型、字符串,甚至是结构体或者类。如下的 A、C、M 都可以是关键字;
int A = 5;
char C[100] = "Hello World!";
struct Obj { };
Obj M; 哈希表的实现过程中,我们需要通过一些手段,将一个非整型的 关键字 转换成 数组下标,也就是 哈希值,从而通过O(1) 的时间快速索引到它所对应的位置。
而将一个非整型的 关键字 转换成 整型 的手段就是 哈希函数。
哈希函数可以简单的理解为就是小学课本上那个函数,即
y = f ( x )
,这里的 f(x) 就是哈希函数,x是关键字,y是哈希值。好的哈希函数应该具备以下两个特质:
a)单射;
b)雪崩效应:输入值x的 1比特的变化,能够造成输出值y至少一半比特的变化;
单射很容易理解,图 ( a ) (a) (a) 中已知哈希值 y 时,键 x 可能有两种情况,不是一个单射;而图 (b) 中已知哈希值 y时,键 x 一定是唯一确定的,所以它是单射。由于 x 和 y 一一对应,这样就从本原上减少了冲突。
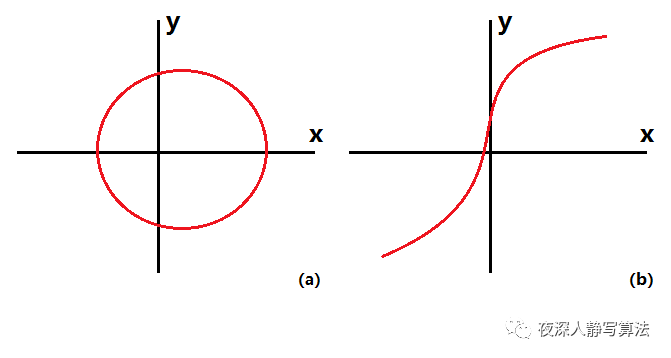
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。
哈希函数在生成 哈希值 的过程中,如果产生 不同的关键字得到相同的哈希值 的情况,就被称为 哈希冲突。
即对于哈希函数y=f(x),当关键字 x1≠x2 ,但是却有f(x1)=f(x2),这时候,我们需要进行冲突解决。
冲突解决方法有很多,主要有:开放定址法、再散列函数法、链地址法、公共溢出区法 等等。有关解决冲突的内容,下文会进行详细讲解。
哈希地址 就是一个 数组下标 ,即哈希数组的下标。通过下标获得数据,被称为 索引。通过数据获得下标,被称为 哈希。平时工作的时候,和同事交流时用到的一个词 反查 就是说的 哈希。
直接定址法 就是 关键字 本身就是 哈希值,表示成函数值就是
f(x)=x
例如,我们需要统计一个字符串中每个字符的出现次数,就可以通过这种方法。任何一个字符的范围都是 [0,255],所以只要用一个长度为 256 的哈希数组就可以存储每个字符对应的出现次数,利用一次遍历枚举就可以解决这个问题。C代码实现如下:
int i, hash[256];
for(i = 0; str[i]; ++i) {
++hash[ str[i] ];
} 这个就是最基础的直接定址法的实现。hash[c]代表字符c在这个字符串str中的出现次数。
平方取中法 就是对 关键字 进行平方,再取中间的某几位作为 哈希值。
例如,对于关键字 1314,得到平方为1726596,取中间三位作为哈希值,即265。
平方取中法 比较适用于 不清楚关键字的分布,且位数也不是很大 的情况。
折叠法 是将关键字分割成位数相等的几部分(注意最后一部分位数不够可以短一些),然后再进行求和,得到一个 哈希值。
例如,对于关键字 5201314,将它分为四组,并且相加得到:52+01+31+4=88,这就是哈希值。
折叠法 比较适用于 不清楚关键字的分布,但是关键字位数较多 的情况。
除留余数法 就是 关键字 模上 哈希表 长度,表示成函数值就是
f(x)=x mod m
其中 m 代表了哈希表的长度,这种方法,不仅可以对关键字直接取模,也可以在 平方取中法、折叠法 之后再取模。
例如,对于一个长度为 4 的哈希数组,我们可以将关键字 模 4 得到哈希值,如图所示:
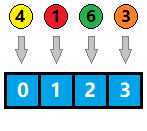
哈希数组的长度一般选择 2 的幂,因为我们知道取模运算是比较耗时的,而位运算相对较为高效。
选择 2 的幂作为数组长度,可以将 取模运算 转换成 二进制位与。
令 m = 2^k,那么它的二进制表示就是:
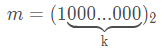
,任何一个数模上 m,就相当于取了 m 的二进制低 k 位,而
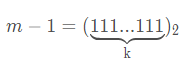
,所以和 位与m−1 的效果是一样的。即:
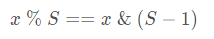
除了直接定址法,其它三种方法都有可能导致哈希冲突,接下来,我们就来讨论下常用的一些哈希冲突的解决方案。
开放定址法 就是一旦发生冲突,就去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的 哈希地址。公式如下:
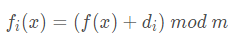
这里的di 是一个数列,可以是常数列(1,1,1,...,1),也可以是等差数列(1,2,3,...,m−1)。
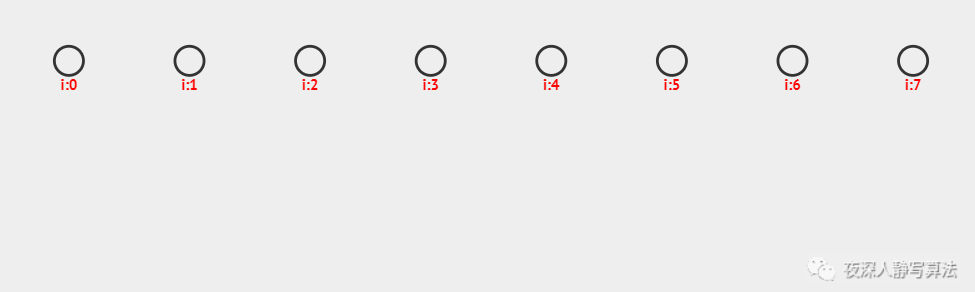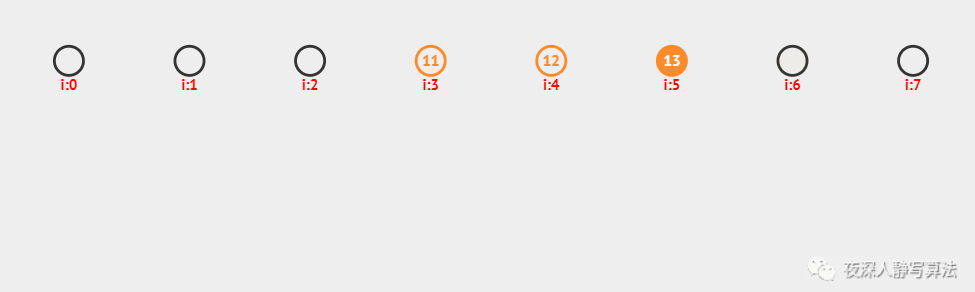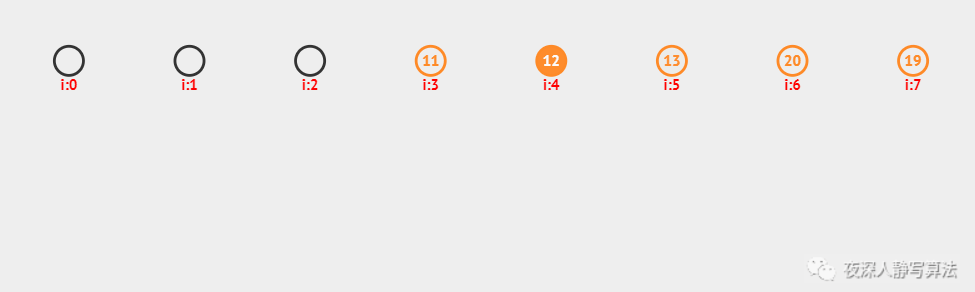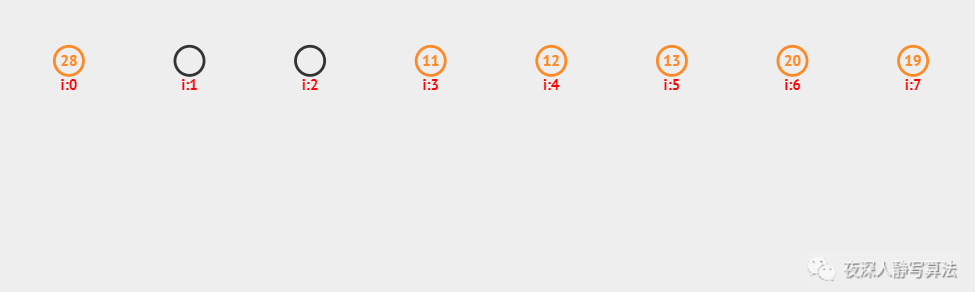
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 开放定址法,哈希表的每个数据就是一个关键字,插入之前需要先进行查找,如果找到的位置未被插入,则执行插入;否则,找到下一个未被插入的位置进行插入;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
这种方法需要注意的是,当插入数据超过哈希表长度时,不能再执行插入。
本文在第四章讲解 哈希表的现实 时采用的就是常数列的开放定址法。
再散列函数法 就是一旦发生冲突,就采用另一个哈希函数,可以是 平方取中法、折叠法、除留余数法 等等的组合,一般用两个哈希函数,产生冲突的概率已经微乎其微了。
再散列函数法 能够使关键字不产生聚集,当然,也会增加不少哈希函数的计算时间。
待补充
当然,产生冲突后,我们也可以选择不换位置,还是在原来的位置,只是把 哈希值 相同的用链表串联起来。这种方法被称为 链地址法。
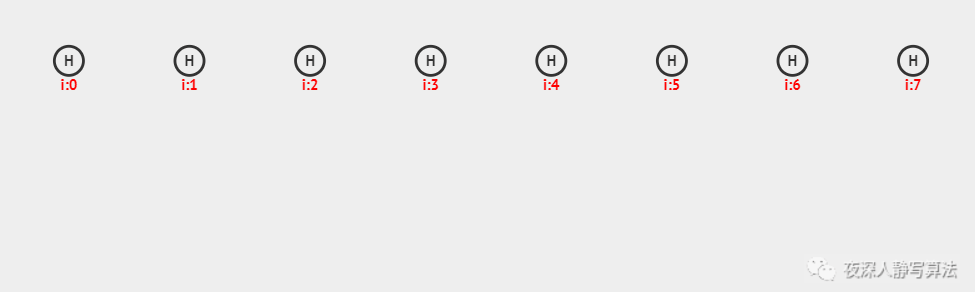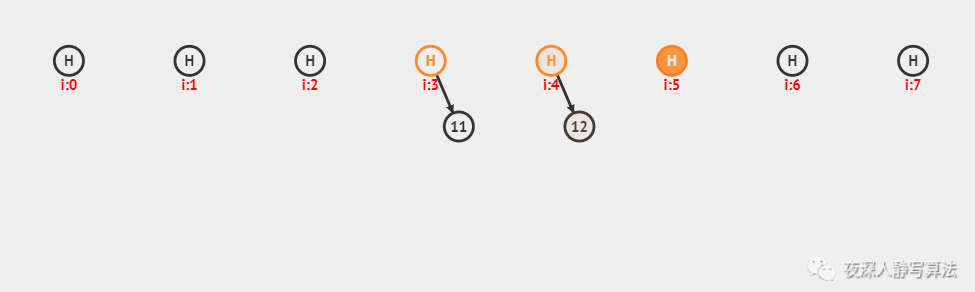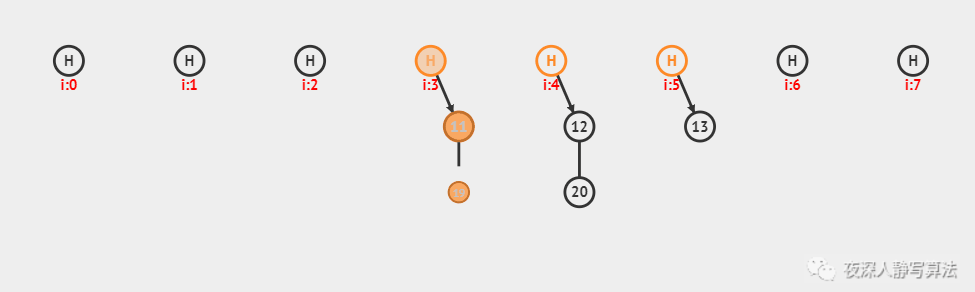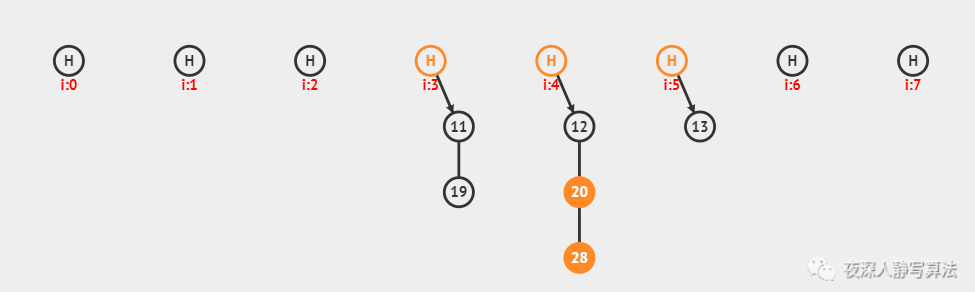
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 链地址法,哈希表的每个数据保留了一个 链表头结点 和 尾结点,插入之前需要先进行查找,如果找到的位置,链表非空,则插入尾结点并且更新尾结点;否则,生成一个新的链表头结点和尾结点;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
一旦产生冲突的数据,统一放到另外一个顺序表中,每次查找数据,在哈希数组中到的关键字和给定关键字相等,则认为查找成功;否则,就去公共溢出区顺序查找,这种方法被称为 公共溢出区法。
这种方法适合冲突较少的情况。
待补充
由于哈希表的底层存储还是数组,所以我们可以定义一个结构体,结构体中定义一个数组类型的成员,如果需要记录哈希表元素的个数,还可以记录一个 size字段。
C语言实现如下:
#define maxn (1<<17) // (1)
#define mask (maxn-1) // (2)
#define DataType int // (3)
#define Boolean int // (4)
#define NULLKEY (maxn+2) // (5)
typedef struct {
DataType data[maxn];
}HashTable;(1) 利用位运算计算哈希函数进行加速,哈希表的长度为 2 的幂;
(2) 利用上文提到的 位与法 作为哈希函数,进行位与的掩码必须是二进制表示都是1的,所以等于 2 的幂减一;
(3) 定义关键字类型为整型int;
(4) 定义一个布尔变量类型;
(5) NULLKEY作为哈希表对应位置为空时的标记,必须是一个非关键字能取到的值;
哈希表初始化要做的事情,就是把哈希表的每个位置都置空。C语言代码实现如下:
void HashInit(HashTable *ht) {
int i;
for(i = 0; i < maxn; ++i) {
ht->data[i] = NULLKEY; // (1)
}
}(1) 将哈希表的每个位置都置空;
哈希函数计算采用 除留余数法 的优化版本 位与法。C语言代码实现如下:
int HashGetAddr(DataType key) {
return key & mask;
}查找需要采用和插入时相同的哈希冲突方案,即开放寻址法。C语言代码实现如下:
Boolean HashSearchKey(HashTable *ht, DataType key, int *addr) {
int startaddr = HashGetAddr(key); // (1)
*addr = startaddr; // (2)
while(ht->data[*addr] != key) { // (3)
*addr = HashGetAddr(*addr + 1); // (4)
if(ht->data[*addr] == NULLKEY) // (5)
return 0;
if(*addr == startaddr) // (6)
return 0;
}
return 1; // (7)
}(1) 根据 哈希函数HashGetAddr计算得到一个哈希值startaddr;
(2) addr是需要作为返回值的,所以要用解引用;
(3) 在哈希表的addr对应查找,如果不是空位,则继续(4);否则,跳出循环;
(4) 往后找一个位置;
(5) 如果发现一个空位,说明这个关键字在哈希表中没有对应数据,直接返回 0,代表查找失败;
(6) 代表整个 哈希表 都已经遍历完毕,都没有找到合适的关键字,直接返回 0,代表查找失败;
(7) 否则,返回 1 代表查找成功;
哈希冲突时(即当没有合适位置),就找下一相邻位置,即寻址数列为常数列 (1,1,1,...,1)。插入需要注意当哈希表慢时,不能再执行插入操作。C语言代码实现如下:
int HashInsert(HashTable *ht, DataType key) {
int addr = HashGetAddr(key); // (1)
int retaddr;
if ( HashSearchKey(ht, key, &retaddr ) ) { // (2)
return retaddr;
}
while(ht->data[addr] != NULLKEY) // (3)
addr = HashGetAddr(addr + 1); // (4)
ht->data[addr] = key; // (5)
return addr; // (6)
} (1) 根据 哈希函数HashGetAddr计算得到一个哈希值addr;
(2) 插入前需要先查找是否存在,如果已经存在,则不执行插入;
(3) 在哈希表的addr对应查找,如果不是空位,则继续 (3);否则,跳出循环;
(4) 往后找一个位置,继续判断是否为空;
(5) 跳出循环则代表当前哈希表的addr位置没有其它元素占据,则可以作为当前key的位置进行插入;
(6) 返回addr作为key的哈希地址;
有了查找的基础,删除操作就比较简单了,如果不能找到一个关键字的位置,则不对哈希表进行任何操作,返回空关键字;否则,将找到的位置赋为空关键字,并且返回删除的位置;
int HashRemove(HashTable *ht, DataType key) {
int addr;
if ( !HashSearchKey(ht, key, &addr ) ) { // (1)
return NULLKEY;
}
ht->data[addr] = NULLKEY; // (2)
return addr;
}(1) 首先执行查找;
(2) 对找到的位置,将找到位置关键字清空;
最后,给出一个 开放定址法 的哈希表的完整实现,如下:
/******************** 哈希表 开放定址法 ********************/
#define maxn (1<<17)
#define mask (maxn-1)
#define DataType int
#define Boolean int
#define NULLKEY (1<<30)
typedef struct {
DataType data[maxn];
}HashTable;
void HashInit(HashTable *ht) {
int i;
for(i = 0; i < maxn; ++i) {
ht->data[i] = NULLKEY;
}
}
int HashGetAddr(DataType key) {
return key & mask;
}
Boolean HashSearchKey(HashTable *ht, DataType key, int *addr) {
int startaddr = HashGetAddr(key);
*addr = startaddr;
while(ht->data[*addr] != key) {
*addr = HashGetAddr(*addr + 1);
if(ht->data[*addr] == NULLKEY) {
return 0;
}
if(*addr == startaddr) {
return 0;
}
}
return 1;
}
int HashInsert(HashTable *ht, DataType key) {
int addr = HashGetAddr(key);
int retaddr;
if ( HashSearchKey(ht, key, &retaddr ) ) {
return retaddr;
}
while(ht->data[addr] != NULLKEY)
addr = HashGetAddr(addr + 1);
ht->data[addr] = key;
return addr;
}
int HashRemove(HashTable *ht, DataType key) {
int addr;
if ( !HashSearchKey(ht, key, &addr ) ) {
return NULLKEY;
}
ht->data[addr] = NULLKEY;
return addr;
}
/******************** 哈希表 开放定址法 ********************/关于“c语言中哈希表的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



