Spark 可以读取文本,csv和rmdb中的数据,并且带有类型自动检测功能
public final static String DATA_SEPARATOR_TAB = "\t";
session.read().format("csv").option("delimiter", Constants.DATA_SEPARATOR_TAB).option("inferSchema", "true").option("header", "true").option("encoding", charset).csv(path).toDF(columnNames).write().mode(mode).saveAsTable(tempTable);
红色属性决定spark是否自动探测数据类型,如果不开启自动探测,默认都是string
rdbms导入到spark中默认会类型探测和对应,但是在处理sqlserver的时间类型有问题
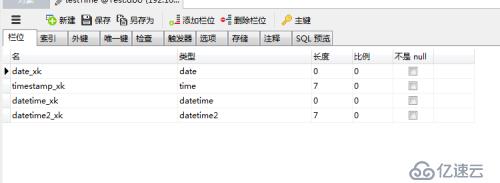
如上图所示
只有datetime可以被spark识别并存储为日期类型,其他的都落地成了String类型,所以在执行data_formate时因为要多做一步转换所以性能会差很多
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





