小编给大家分享一下Vue3中AST解析器的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
首先我们来重温一下 baseCompile 函数中有关 ast 的逻辑及后续的使用:
export function baseCompile(
template: string | RootNode,
options: CompilerOptions = {}
): CodegenResult {
/* 忽略之前逻辑 */
const ast = isString(template) ? baseParse(template, options) : template
transform(
ast,
{/* 忽略参数 */}
)
return generate(
ast,
extend({}, options, {
prefixIdentifiers
})
)
}因为我已经将咱们不需要关注的逻辑注释处理,所以现在看函数体内的逻辑会非常清晰:
生成 ast 对象
将 ast 对象作为参数传入 transform 函数,对 ast 节点进行转换操作
将 ast 对象作为参数传入 generate 函数,返回编译结果
这里我们主要关注 ast 的生成。可以看到 ast 的生成有一个三目运算符的判断,如果传进来的 template 模板参数是一个字符串,那么则调用 baseParse 解析模板字符串,否则直接将 template 作为 ast 对象。baseParse 里做了什么事情才能生成 ast 呢?一起来看一下源码,
export function baseParse(
content: string,
options: ParserOptions = {}
): RootNode {
const context = createParserContext(content, options) // 创建解析的上下文对象
const start = getCursor(context) // 生成记录解析过程的游标信息
return createRoot( // 生成并返回 root 根节点
parseChildren(context, TextModes.DATA, []), // 解析子节点,作为 root 根节点的 children 属性
getSelection(context, start)
)
}在 baseParse 的函数中我添加了注释,方便大家理解各个函数的作用,首先会创建解析的上下文,之后根据上下文获取游标信息,由于还未进行解析,所以游标中的 column、line、offset 属性对应的都是 template 的起始位置。之后就是创建根节点并返回根节点,至此ast 树生成,解析完成。
export function createRoot(
children: TemplateChildNode[],
loc = locStub
): RootNode {
return {
type: NodeTypes.ROOT,
children,
helpers: [],
components: [],
directives: [],
hoists: [],
imports: [],
cached: 0,
temps: 0,
codegenNode: undefined,
loc
}
}看 createRoot 函数的代码,我们能发现该函数就是返回了一个 RootNode 类型的根节点对象,其中我们传入的 children 参数会被作为根节点的 children 参数。这里非常好理解,按树型数据结构来想象就可以。所以生成 ast 的关键点就会聚焦到 parseChildren 这个函数上来。parseChildren 函数如果不去看它的源码,见文之意也可以大致了解这是一个解析子节点的函数。接下来我们就来一起来看一下 AST 解析中最关键的 parseChildren 函数,还是老规矩,为了帮助大家理解,我会精简函数体内的逻辑。
function parseChildren(
context: ParserContext,
mode: TextModes,
ancestors: ElementNode[]
): TemplateChildNode[] {
const parent = last(ancestors) // 获取当前节点的父节点
const ns = parent ? parent.ns : Namespaces.HTML
const nodes: TemplateChildNode[] = [] // 存储解析后的节点
// 当标签未闭合时,解析对应节点
while (!isEnd(context, mode, ancestors)) {/* 忽略逻辑 */}
// 处理空白字符,提高输出效率
let removedWhitespace = false
if (mode !== TextModes.RAWTEXT && mode !== TextModes.RCDATA) {/* 忽略逻辑 */}
// 移除空白字符,返回解析后的节点数组
return removedWhitespace ? nodes.filter(Boolean) : nodes
}从上文代码中,可以知道 parseChildren 函数接收三个参数,context:解析器上下文,mode:文本数据类型,ancestors:祖先节点数组。而函数的执行中会首先从祖先节点中获取当前节点的父节点,确定命名空间,以及创建一个空数组,用来储存解析后的节点。之后会有一个 while 循环,判断是否到达了标签的关闭位置,如果不是需要关闭的标签,则在循环体内对源模板字符串进行分类解析。之后会有一段处理空白字符的逻辑,处理完成后返回解析好的 nodes 数组。在大家对于 parseChildren 的执行流程有一个初步理解之后,我们一起来看一下函数的核心,while 循环内的逻辑。
在 while 中解析器会判断文本数据的类型,只有当 TextModes 为 DATA 或 RCDATA 时会继续往下解析。
第一种情况就是判断是否需要解析 Vue 模板语法中的 “Mustache”语法 (双大括号) ,如果当前上下文中没有 v-pre 指令来跳过表达式,并且源模板字符串是以我们指定的分隔符开头的(此时 context.options.delimiters 中是双大括号),就会进行双大括号的解析。这里就可以发现,如果当你有特殊需求,不希望使用双大括号作为表达式插值,那么你只需要在编译前改变选项中的 delimiters 属性即可。
接下来会判断,如果第一个字符是 “<” 并且第二个字符是 '!'的话,会尝试解析注释标签,<!DOCTYPE 和 <!CDATA 这三种情况,对于 DOCTYPE 会进行忽略,解析成注释。
之后会判断当第二个字符是 “/” 的情况,“</” 已经满足了一个闭合标签的条件了,所以会尝试去匹配闭合标签。当第三个字符是 “>”,缺少了标签名字,会报错,并让解析器的进度前进三个字符,跳过 “</>”。
如果“</”开头,并且第三个字符是小写英文字符,解析器会解析结束标签。
如果源模板字符串的第一个字符是 “<”,第二个字符是小写英文字符开头,会调用 parseElement 函数来解析对应的标签。
当这个判断字符串字符的分支条件结束,并且没有解析出任何 node 节点,那么会将 node 作为文本类型,调用 parseText 进行解析。
最后将生成的节点添加进 nodes 数组,在函数结束时返回。
这就是 while 循环体内的逻辑,且是 parseChildren 中最重要的部分。在这个判断过程中,我们看到了双大括号语法的解析,看到了注释节点的怎样被解析的,也看到了开始标签和闭合标签的解析,以及文本内容的解析。精简后的代码在下方框中,大家可以对照上述的讲解,来理解一下源码。当然,源码中的注释也是非常详细了哟。
while (!isEnd(context, mode, ancestors)) {
const s = context.source
let node: TemplateChildNode | TemplateChildNode[] | undefined = undefined
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
if (!context.inVPre && startsWith(s, context.options.delimiters[0])) {
/* 如果标签没有 v-pre 指令,源模板字符串以双大括号 `{{` 开头,按双大括号语法解析 */
node = parseInterpolation(context, mode)
} else if (mode === TextModes.DATA && s[0] === '<') {
// 如果源模板字符串的第以个字符位置是 `!`
if (s[1] === '!') {
// 如果以 '<!--' 开头,按注释解析
if (startsWith(s, '<!--')) {
node = parseComment(context)
} else if (startsWith(s, '<!DOCTYPE')) {
// 如果以 '<!DOCTYPE' 开头,忽略 DOCTYPE,当做伪注释解析
node = parseBogusComment(context)
} else if (startsWith(s, '<![CDATA[')) {
// 如果以 '<![CDATA[' 开头,又在 HTML 环境中,解析 CDATA
if (ns !== Namespaces.HTML) {
node = parseCDATA(context, ancestors)
}
}
// 如果源模板字符串的第二个字符位置是 '/'
} else if (s[1] === '/') {
// 如果源模板字符串的第三个字符位置是 '>',那么就是自闭合标签,前进三个字符的扫描位置
if (s[2] === '>') {
emitError(context, ErrorCodes.MISSING_END_TAG_NAME, 2)
advanceBy(context, 3)
continue
// 如果第三个字符位置是英文字符,解析结束标签
} else if (/[a-z]/i.test(s[2])) {
parseTag(context, TagType.End, parent)
continue
} else {
// 如果不是上述情况,则当做伪注释解析
node = parseBogusComment(context)
}
// 如果标签的第二个字符是小写英文字符,则当做元素标签解析
} else if (/[a-z]/i.test(s[1])) {
node = parseElement(context, ancestors)
// 如果第二个字符是 '?',当做伪注释解析
} else if (s[1] === '?') {
node = parseBogusComment(context)
} else {
// 都不是这些情况,则报出第一个字符不是合法标签字符的错误。
emitError(context, ErrorCodes.INVALID_FIRST_CHARACTER_OF_TAG_NAME, 1)
}
}
}
// 如果上述的情况解析完毕后,没有创建对应的节点,则当做文本来解析
if (!node) {
node = parseText(context, mode)
}
// 如果节点是数组,则遍历添加进 nodes 数组中,否则直接添加
if (isArray(node)) {
for (let i = 0; i < node.length; i++) {
pushNode(nodes, node[i])
}
} else {
pushNode(nodes, node)
}
}在 while 的循环内,各个分支判断分支内,我们能看到 node 会接收各种节点类型的解析函数的返回值。而这里我会详细的说一下 parseElement 这个解析元素的函数,因为这是我们在模板中用的最频繁的场景。
我先把 parseElement 的源码精简一下贴上来,然后来唠一唠里面的逻辑。
function parseElement(
context: ParserContext,
ancestors: ElementNode[]
): ElementNode | undefined {
// 解析起始标签
const parent = last(ancestors)
const element = parseTag(context, TagType.Start, parent)
// 如果是自闭合的标签或者是空标签,则直接返回。voidTag例如: `<img>`, `<br>`, `<hr>`
if (element.isSelfClosing || context.options.isVoidTag(element.tag)) {
return element
}
// 递归的解析子节点
ancestors.push(element)
const mode = context.options.getTextMode(element, parent)
const children = parseChildren(context, mode, ancestors)
ancestors.pop()
element.children = children
// 解析结束标签
if (startsWithEndTagOpen(context.source, element.tag)) {
parseTag(context, TagType.End, parent)
} else {
emitError(context, ErrorCodes.X_MISSING_END_TAG, 0, element.loc.start)
if (context.source.length === 0 && element.tag.toLowerCase() === 'script') {
const first = children[0]
if (first && startsWith(first.loc.source, '<!--')) {
emitError(context, ErrorCodes.EOF_IN_SCRIPT_HTML_COMMENT_LIKE_TEXT)
}
}
}
// 获取标签位置对象
element.loc = getSelection(context, element.loc.start)
return element
}首先我们会获取当前节点的父节点,然后调用 parseTag 函数解析。
parseTag 函数会按的执行大体是以下流程:
首先匹配标签名。
解析元素中的 attribute 属性,存储至 props 属性
检测是否存在 v-pre 指令,若是存在的话,则修改 context 上下文中的 inVPre 属性为 true
检测自闭合标签,如果是自闭合,则将 isSelfClosing 属性置为 true
判断 tagType,是 ELEMENT 元素还是 COMPONENT 组件,或者 SLOT 插槽
返回生成的 element 对象
在获取到 element 对象后,会判断 element 是否是自闭合标签,或者是空标签,例如 <img>, <br>, <hr> ,如果是这种情况,则直接返回 element 对象。
然后我们会尝试解析 element 的子节点,将 element 压入栈中中,然后递归的调用 parseChildren 来解析子节点。
const parent = last(ancestors)
再回头看看 parseChildren 以及 parseElement 中的这行代码,就可以发现在将 element 入栈后,我们拿到的父节点就是当前节点。在解析完毕后,调用 ancestors.pop() ,使当前解析完子节点的 element 对象出栈,将解析后的 children 对象赋值给 element 的 children 属性,完成 element 的子节点解析,这里是个很巧妙的设计。
最后匹配结束标签,设置 element 的 loc 位置信息,返回解析完毕的 element 对象。
请看下方我们要解析的模板,图片中是解析过程中,保存解析后节点的栈的存储情况,
<div> <p>Hello World</p> </div>
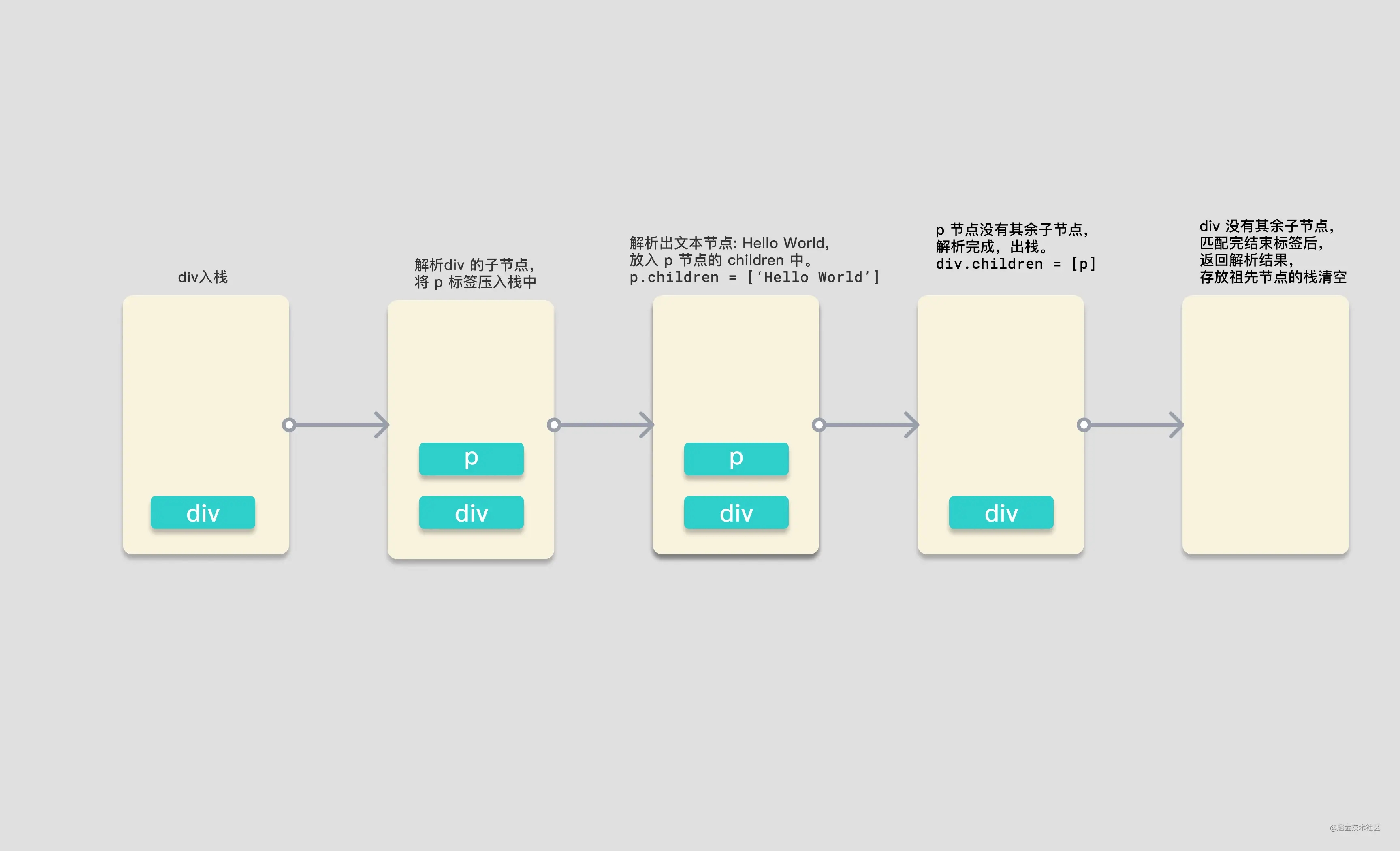
图中的黄色矩形是一个栈,当开始解析时,parseChildren 首先会遇到 div 标签,开始调用的 parseElement 函数。通过 parseTag 函数解析出了 div 元素,并将它压入栈中,递归解析子节点。第二次调用 parseChildren 函数,遇见 p 元素,调用 parseElement 函数,将 p 标签压入栈中,此时栈中有 div 和 p 两个标签。再次解析 p 中的子节点,第三次调用 parseChildren 标签,这次不会匹配到任何标签,不会生成对应的 node,所以会通过 parseText 函数去生成文本,解析出 node 为 HelloWorld,并返回 node。
将这个文本类型的 node 添加进 p 标签的 children 属性后,此时 p 标签的子节点解析完毕,弹出祖先栈,完成结束标签的解析后,返回 p 标签对应的 element 对象。
p 标签对应的 node 节点生成,并在 parseChildren 函数中返回对应 node。
div 标签在接收到 p 标签的 node 后,添加进自身的 children 属性中,出栈。此时祖先栈中就空空如也了。而 div 的标签完成闭合解析的逻辑后,返回 element 元素。
最终 parseChildren 的第一次调用返回结果,生成了 div 对应的 node 对象,也返回了结果,将这个结果作为 createRoot 函数的 children 参数传入,生成根节点对象,完成 ast 解析。
以上是“Vue3中AST解析器的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





