这篇文章主要为大家展示了“python数据解析中XPath有什么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“python数据解析中XPath有什么用”这篇文章吧。
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
xpath是最常用且最便捷高效的一种解析方式,通用型强,其不仅可以用于python语言中,还可以用于其他语言中,数据解析建议首先xpath。
xpath解析原理:
实例化一个etree的对象,且需要将被解析的页面源代码数据加载到该对象中
调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
安装lxml
pip install -i https://mirrors.aliyun.com/pypi/simple/ lxml
from lxml import etree
tree = etree.parse('./tree.html') #从本地加载源码,实例化一个etree对象。必须是本地的文件,不能是字符串
tree = etree.HTML(源码) #从互联网加载源码,实例化etree对象
# / 表示从从根节点开始,一个 / 表示一个层级,//表示多个层级
r = tree.xpath('//div//a') #以列表的形式返回div下的所有的a标签对象的地址
r = tree.xpath('//div//a')[1] #返回div下的第二个a标签对象地址
r = tree.xpath('//div[@class="tang"]') #以列表的形式返回tang标签地址
r = tree.xpath('//div[@class="tang"]//a') #以列表的形式返回tang标签下所有的a标签地址
#获取标签中的文本内容
r = tree.xpath('//div[@class="tang"]//a/text()') #以列表的形式返回所有a标签中的文本
#获取标签中属性值
r = tree.xpath('//div//a/@href') ##以列表的形式返回所有a标签中href属性值tree.html
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="theme-color" content="#ffffff"></meta>
<title>xpaht测试</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>前程似锦</p>
</div>
<div class="song">
<p>前程似锦2</p>
</div>
<div class="ming"> #后面改了名字
<p>以梦为马</p>
</div>
<div class="tang">
<ul>
<li><a href='http://123.com' title='qing'>清明时节</a></li>
<li><a href='http://ws.com' title='qing'>秦时明月</a></li>
<li><a href='http://xzc.com' title='qing'>汉时关</a></li>
</ul>
</div>
<flink-root></flink-root>
<script type="text/javascript" src="runtime.0dcf16aad31edd73d8e8.js"></script>
<script type="text/javascript" src="es2015-polyfills.923637a8e6d276e6f6df.js"></script>
<script type="text/javascript" src="polyfills.bb2456cce5322b484b77.js"></script>
<script type="text/javascript" src="main.8128365baee3dc30e607.js"></script>
</body>
</html>将页面中的房源名称解析出来,即将title值解析出来就行
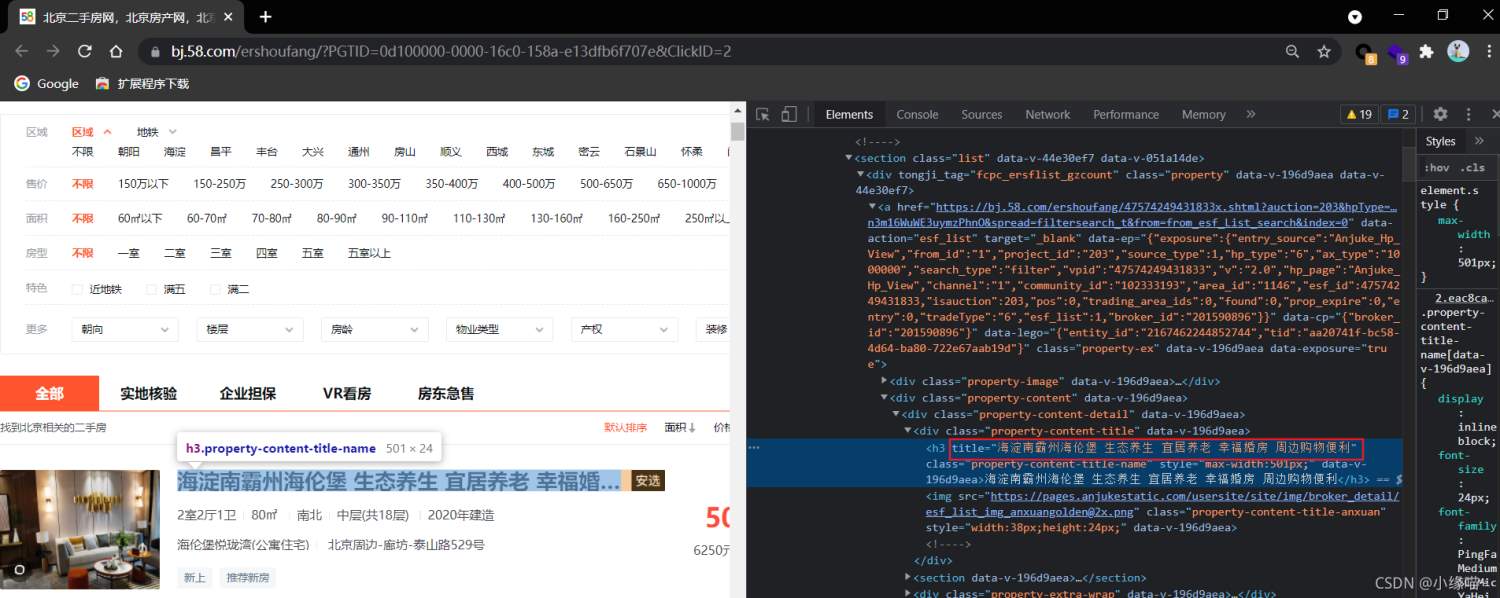
思路
获取房源名称所在的url,并获取其响应数据
数据解析,构造xpath表达式。提取目标数据
import requests
from lxml import etree
url = "https://bj.58.com/ershoufang/p1/"
headers={
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Mobile Safari/537.36'
}
pag_response = requests.get(url,headers=headers,timeout=3).text
#实例化一个etree对象
tree = etree.HTML(pag_response)
r = tree.xpath('//span[@class="content-title"]/text()') #获取所有//span标签为"content-title"的文本内容
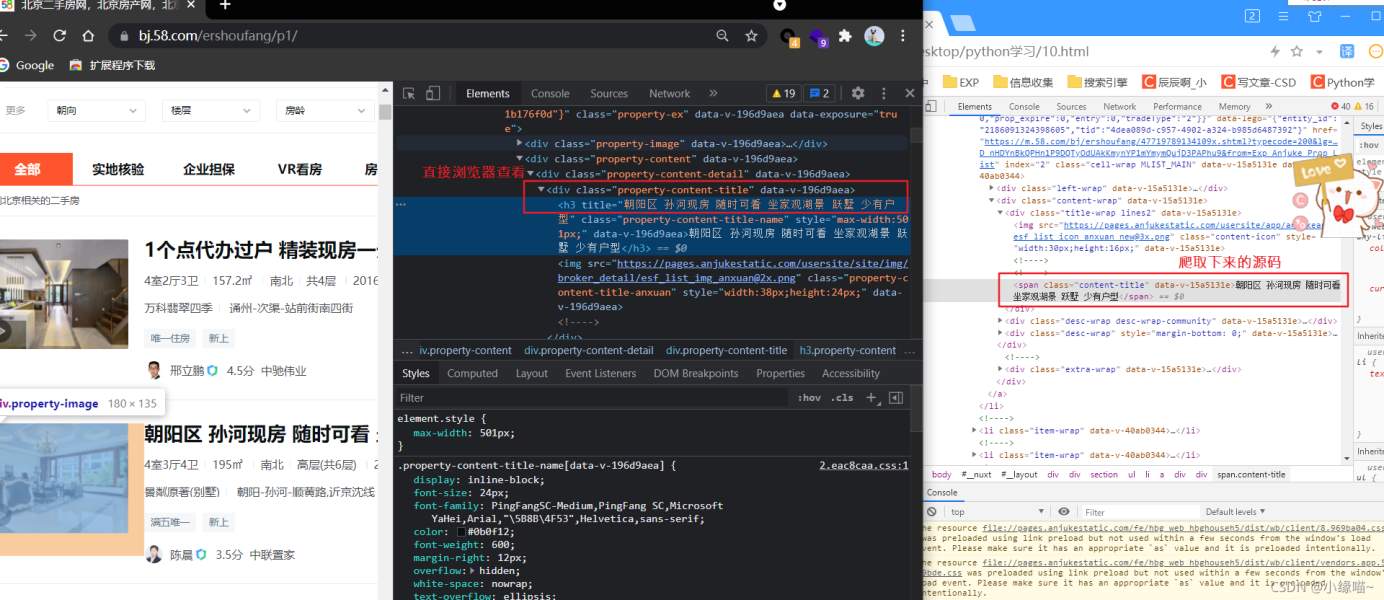
print(r)Tips:我们使用xpath进行数据解析时,不能直接看元素就进行构造xpath表达式,以为很多情况下从浏览中看的元素结构和爬取下来的源码结构不一样。所以正确方法是先将源码爬下来再观察进行构造xpath。
如下浏览器中的元素结构和爬取的元素结构就不一样。如果按照浏览器汇总的元素来构造xpath表达式,则不会解析成功!
以上是“python数据解析中XPath有什么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



