本篇内容介绍了“SpringBoot怎么使用Sharding-JDBC实现数据分片和读写分离”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
一、Sharding-JDBC简介
二、具体的实现方式
1、maven引用
2、数据库准备
3、Spring配置
4、精准分片算法和范围分片算法的Java代码
5、测试
Sharding-JDBC是Sharding-Sphere的一个产品,它有三个产品,分别是Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar,这三个产品提供了标准化的数据分片、读写分离、柔性事务和数据治理功能。我们这里用的是Sharding-JDBC,所以想了解后面两个产品的话可以去它们官网查看。
Sharding-JDBC为轻量级Java框架,使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,兼容性特别强。适用的ORM框架有JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC;第三方的数据库连接池有DBCP, C3P0, BoneCP, Druid等;支持的数据库有MySQL,Oracle,SQLServer和PostgreSQL;多样化的配置文件Java,yaml,Spring Boot ,Spring命名空间。其实这里说的都是废话,大家可以不看,下面我们动手开始正式配置。
我这里用的配置方式是Spring命名空间配置,所以只需要引用sharding-jdbc-spring-namespace就可以了,还有要注意的是我用的不是当当网的sharding,注意groupId是io.shardingsphere。如果用的是其它配置方式可以去http://maven.aliyun.com/nexus/#nexus-search;quick~io.shardingsphere网站查找相应maven引用
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.0.0.M1</version>
</dependency>我这里用的是mysql数据库,根据我们项目的具体需求,我准备了三个主库和对应的从库。模拟的主库名有master,暂时没有做对应从库,所以对应的从库还是指向master;第二个主库有master_1,对应的从库有master_1_slaver_1,master_1_slave_2;第三个主库有master_2,对应的从库有master_2_slave_1,master_2_slave_2。
数据库中的表也做了分表,下面是对应的mysql截图。
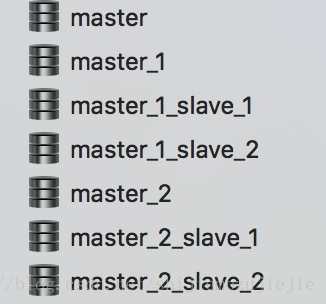
这第一幅图上的主从库都应该在不同的服务器上的,但这里只是为了模拟所以就建在了本地服务器上了。我们读写分离中的写操作只会发生在主库上,从库会自动同步主库上的数据并为读提供数据。数据库的主从复制在上篇博文中做了详细的介绍,大家可以去看看https://www.yisu.com/article/226077.htm
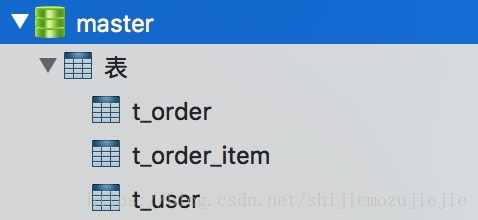
这幅图作为我们本来的主库,下面做的分库和分表都是基于这个库中的订单表分的。所以分库中的表只有订单表和订单明细表。
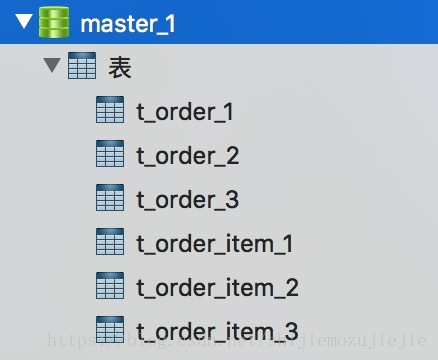
第三幅图截的是第二个主库,里面对订单和订单明细表做了分表操作,具体的分片策略和分片算法下面再做介绍。第三个主表和第二个主表是一样的,所有的从表都和对应的主表是一致的。
数据库信息配置文件db.properties配置可以配置两份,分为开发版和测试版,如下:
# master
Master.url=jdbc:mysql://localhost:3306/master?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master.username=root
Master.password=123456
Slave.url=jdbc:mysql://localhost:3306/master?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Slave.username=root
Slave.password=123456
# maste_1
Master_1.url=jdbc:mysql://localhost:3306/master_1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_1.username=root
Master_1.password=123456
Master_1_Slave_1.url=jdbc:mysql://localhost:3306/master_1_slave_1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_1_Slave_1.username=root
Master_1_Slave_1.password=123456
Master_1_Slave_2.url=jdbc:mysql://localhost:3306/master_1_slave_2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_1_Slave_2.username=root
Master_1_Slave_2.password=123456
# master_2
Master_2.url=jdbc:mysql://localhost:3306/master_2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_2.username=root
Master_2.password=123456
Master_2_Slave_1.url=jdbc:mysql://localhost:3306/master_2_slave_1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_2_Slave_1.username=root
Master_2_Slave_1.password=123456
Master_2_Slave_2.url=jdbc:mysql://localhost:3306/master_2_slave_2?useUnicode=true&characterEncoding=utf8&autoReconnect=true&rewriteBatchedStatements=true
Master_2_Slave_2.username=root
Master_2_Slave_2.password=123456Spring对应的配置:
Spring-Sphere官网中的demo里用的都是行表达式的分片策略,但是行表达式的策略不利于数据库和表的横向扩展,所以我这里用的是标准分片策略,精准分片算法和范围分片算法。因为我们项目中暂时用的分片键都是user_id单一键,所以说不存在复合分片策略,也用不到Hint分片策略,行表达式分片策略和不分片策略。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sharding="http://shardingsphere.io/schema/shardingsphere/sharding"
xmlns:master-slave="http://shardingsphere.io/schema/shardingsphere/masterslave"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://shardingsphere.io/schema/shardingsphere/sharding
http://shardingsphere.io/schema/shardingsphere/sharding/sharding.xsd
http://shardingsphere.io/schema/shardingsphere/masterslave
http://shardingsphere.io/schema/shardingsphere/masterslave/master-slave.xsd">
<context:component-scan base-package="com.jihao" />
<!-- db.properties数据库信息配置 -->
<bean id="property" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:property/db_dev.properties" />
</bean>
<!-- 主库 -->
<bean id="master" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master.url}"/>
<property name="username" value="${Master.username}"/>
<property name="password" value="${Master.password}"/>
</bean>
<!-- 主库的从库 -->
<bean id="slave" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Slave.url}"/>
<property name="username" value="${Slave.username}"/>
<property name="password" value="${Slave.password}"/>
</bean>
<!-- 主库的分库1 -->
<bean id="master_1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_1.url}"/>
<property name="username" value="${Master_1.username}"/>
<property name="password" value="${Master_1.password}"/>
</bean>
<!-- 分库1的从库1 -->
<bean id="master_1_slave_1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_1_Slave_1.url}"/>
<property name="username" value="${Master_1_Slave_1.username}"/>
<property name="password" value="${Master_1_Slave_1.password}"/>
</bean>
<!-- 分库1的从库2 -->
<bean id="master_1_slave_2" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_1_Slave_2.url}"/>
<property name="username" value="${Master_1_Slave_2.username}"/>
<property name="password" value="${Master_1_Slave_2.password}"/>
</bean>
<!-- 主库的分库2 -->
<bean id="master_2" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_2.url}"/>
<property name="username" value="${Master_2.username}"/>
<property name="password" value="${Master_2.password}"/>
</bean>
<!-- 分库2的从库1 -->
<bean id="master_2_slave_1" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_2_Slave_1.url}"/>
<property name="username" value="${Master_2_Slave_1.username}"/>
<property name="password" value="${Master_2_Slave_1.password}"/>
</bean>
<!-- 分库2的从库2 -->
<bean id="master_2_slave_2" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${Master_2_Slave_2.url}"/>
<property name="username" value="${Master_2_Slave_2.username}"/>
<property name="password" value="${Master_2_Slave_2.password}"/>
</bean>
<!-- 主从关系配置 -->
<bean id="randomStrategy" class="io.shardingsphere.core.api.algorithm.masterslave.RandomMasterSlaveLoadBalanceAlgorithm" />
<master-slave:data-source id="ms_master" master-data-source-name="master" slave-data-source-names="slave" strategy-ref="randomStrategy" />
<master-slave:data-source id="ms_master_1" master-data-source-name="master_1" slave-data-source-names="master_1_slave_1, master_1_slave_2" strategy-ref="randomStrategy" />
<master-slave:data-source id="ms_master_2" master-data-source-name="master_2" slave-data-source-names="master_2_slave_1, master_2_slave_2" strategy-ref="randomStrategy" />
<!-- 分库策略 精确分片算法 -->
<bean id="preciseDatabaseStrategy" class="com.jihao.algorithm.PreciseModuleDatabaseShardingAlgorithm" />
<!-- 分库策略 范围分片算法 -->
<bean id="rangeDatabaseStrategy" class="com.jihao.algorithm.RangeModuleDatabaseShardingAlgorithm" />
<!-- 分表策略 精确分片算法 -->
<bean id="preciseTableStrategy" class="com.jihao.algorithm.PreciseModuleTableShardingAlgorithm" />
<!-- 分表策略 范围分片算法-->
<bean id="rangeTableStrategy" class="com.jihao.algorithm.RangeModuleTableShardingAlgorithm" />
<sharding:standard-strategy id="databaseStrategy" sharding-column="user_id" precise-algorithm-ref="preciseDatabaseStrategy" range-algorithm-ref="rangeDatabaseStrategy" />
<!-- 分表策略 -->
<sharding:standard-strategy id="tableStrategy" sharding-column="user_id" precise-algorithm-ref="preciseTableStrategy" range-algorithm-ref="rangeTableStrategy" />
<!-- 行表达式算法 -->
<!-- <sharding:inline-strategy id="databaseStrategy" sharding-column="user_id" algorithm-expression="demo_ds_ms_$->{user_id % 2}" />
<sharding:inline-strategy id="orderTableStrategy" sharding-column="order_id" algorithm-expression="t_order_$->{order_id % 2}" />
<sharding:inline-strategy id="orderItemTableStrategy" sharding-column="order_item_id" algorithm-expression="t_order_item_$->{order_item_id % 2}" /> -->
<sharding:data-source id="shardingDataSource">
<sharding:sharding-rule data-source-names="ms_master,ms_master_1,ms_master_2">
<sharding:table-rules>
<sharding:table-rule logic-table="t_order" actual-data-nodes="ms_master_$->{1..2}.t_order_$->{1..3}" database-strategy-ref="databaseStrategy" table-strategy-ref="tableStrategy" generate-key-column-name="order_id"/>
<sharding:table-rule logic-table="t_order_item" actual-data-nodes="ms_master_$->{1..2}.t_order_item_$->{1..3}" database-strategy-ref="databaseStrategy" table-strategy-ref="tableStrategy" generate-key-column-name="order_item_id"/>
</sharding:table-rules>
</sharding:sharding-rule>
</sharding:data-source>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="shardingDataSource" />
</bean>
<tx:annotation-driven />
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 用于在控制台打印sql(不需要的可以注释掉这一行) -->
<property name="configLocation" value="classpath:log/mybatis-config.xml"></property>
<property name="dataSource" ref="shardingDataSource"/>
<property name="mapperLocations" value="classpath*:com/jihao/mapper/*.xml"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.jihao"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
</beans>标准分片策略,精准分片算法
package com.jihao.algorithm;
import io.shardingsphere.core.api.algorithm.sharding.PreciseShardingValue;
import io.shardingsphere.core.api.algorithm.sharding.standard.PreciseShardingAlgorithm;
import java.util.Collection;
import com.alibaba.fastjson.JSON;
/**
* 自定义标准分片策略,使用精确分片算法(=与IN)
* @author JiHao
*
*/
public class PreciseModuleDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long>{
@Override
public String doSharding(Collection<String> availableTargetNames,
PreciseShardingValue<Long> preciseShardingValue) {
System.out.println("collection:" + JSON.toJSONString(availableTargetNames) + ",preciseShardingValue:" + JSON.toJSONString(preciseShardingValue));
for (String name : availableTargetNames) {
// =与IN中分片键对应的值
String value = String.valueOf(preciseShardingValue.getValue());
// 分库的后缀
int i = 1;
// 求分库后缀名的递归算法
if (name.endsWith("_" + countDatabaseNum(Long.parseLong(value), i))) {
return name;
}
}
throw new UnsupportedOperationException();
}
/**
* 计算该量级的数据在哪个数据库
* @return
*/
private String countDatabaseNum(long columnValue, int i){
// ShardingSphereConstants每个库中定义的数据量
long left = ShardingSphereConstants.databaseAmount * (i-1);
long right = ShardingSphereConstants.databaseAmount * i;
if(left < columnValue && columnValue <= right){
return String.valueOf(i);
}else{
i++;
return countDatabaseNum(columnValue, i);
}
}
}标准分片策略,范围分片算法
package com.jihao.algorithm;
import io.shardingsphere.core.api.algorithm.sharding.RangeShardingValue;
import io.shardingsphere.core.api.algorithm.sharding.standard.RangeShardingAlgorithm;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import com.alibaba.fastjson.JSON;
import com.google.common.collect.Range;
/**
* 自定义标准分库策略,使用范围分片算法(BETWEEN AND)
* @author JiHao
*
*/
public class RangeModuleDatabaseShardingAlgorithm implements RangeShardingAlgorithm<Long>{
@Override
public Collection<String> doSharding(
Collection<String> availableTargetNames,
RangeShardingValue<Long> rangeShardingValue) {
System.out.println("Range collection:" + JSON.toJSONString(availableTargetNames) + ",rangeShardingValue:" + JSON.toJSONString(rangeShardingValue));
Collection<String> collect = new ArrayList<>();
Range<Long> valueRange = rangeShardingValue.getValueRange();
// BETWEEN AND中分片键对应的最小值
long lowerEndpoint = Long.parseLong(String.valueOf(valueRange.lowerEndpoint()));
// BETWEEN AND中分片键对应的最大值
long upperEndpoint = Long.parseLong(String.valueOf(valueRange.upperEndpoint()));
// 分表的后缀
int i = 1;
List<Integer> arrs = new ArrayList<Integer>();
// 求分表后缀名的递归算法
List<Integer> list = countDatabaseNum(i, lowerEndpoint, upperEndpoint, arrs);
for (Integer integer : list) {
for (String each : availableTargetNames) {
if (each.endsWith("_" + integer)) {
collect.add(each);
}
}
}
return collect;
}
/**
* 计算该量级的数据在哪个表
* @param columnValue
* @param i
* @param lowerEndpoint 最小区间
* @param upperEndpoint 最大区间
* @return
*/
private List<Integer> countDatabaseNum(int i, long lowerEndpoint, long upperEndpoint, List<Integer> arrs){
long left = ShardingSphereConstants.databaseAmount * (i-1);
long right = ShardingSphereConstants.databaseAmount * i;
// 区间最大值小于分库最大值
if(left < upperEndpoint && upperEndpoint <= right){
arrs.add(i);
return arrs;
}else{
if(left < lowerEndpoint && lowerEndpoint <= right){
arrs.add(i);
}
i++;
return countDatabaseNum(i, lowerEndpoint, upperEndpoint, arrs);
}
}
}分库的策略用的和分库的代码是一样的,不同之处就是分库用的是databaseAmount,分表用的是tableAmount。下面的ShardingSphereConstants的代码。
package com.jihao.algorithm;
/**
* ShardingSphere中用到的常量
* @author JiHao
*
*/
public class ShardingSphereConstants {
/**
* 订单、优惠券相关的表,按用户数量分库,64w用户数据为一个库
* (0,64w]
*/
public static int databaseAmount = 640000;
/**
* 一个订单表里存10000的用户订单
* (0,1w]
*/
public static int tableAmount = 10000;
}到这里所有的配置基本上都已经完成了,下面的测试。
下面是测试的mybatis的测试文件,都是最基础的就不讲解了。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.jihao.dao.TestShardingMapper">
<resultMap id="BaseResultMap" type="com.jihao.entity.Order">
<id column="order_id" jdbcType="INTEGER" property="orderId" />
<result column="user_id" jdbcType="INTEGER" property="userId" />
<result column="status" jdbcType="INTEGER" property="status" />
</resultMap>
<insert id="insert" parameterType="com.jihao.entity.Order" useGeneratedKeys="true" keyProperty="orderId">
INSERT INTO t_order (
user_id, status
)
VALUES (
#{userId,jdbcType=INTEGER},
#{status,jdbcType=VARCHAR}
)
</insert>
<insert id="insertItem" useGeneratedKeys="true" keyProperty="orderItemId">
INSERT INTO t_order_item (
order_id, user_id
)
VALUES (
#{orderId,jdbcType=INTEGER},
#{userId,jdbcType=INTEGER}
)
</insert>
<select id="searchOrder" resultMap="BaseResultMap">
SELECT * from t_order
</select>
<select id="queryWithEqual" resultMap="BaseResultMap">
SELECT * FROM t_order WHERE user_id=51
</select>
<select id="queryWithIn" resultMap="BaseResultMap">
SELECT * FROM t_order WHERE user_id IN (50, 51)
</select>
<select id="queryWithBetween" resultMap="BaseResultMap">
SELECT * FROM t_order WHERE user_id between 10000 and 30000
</select>
<select id="queryUser" resultType="Map">
SELECT * FROM t_user
</select>
</mapper>下面对应的mapper的Java代码
package com.jihao.dao;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.annotations.Mapper;
import com.jihao.entity.Order;
import com.jihao.entity.OrderItem;
@Mapper
public interface TestShardingMapper {
int insert(Order record);
int insertItem(OrderItem record);
List<Order> searchOrder();
List<Order> queryWithEqual();
List<Order> queryWithIn();
List<Order> queryWithBetween();
List<Map<String, Object>> queryUser();
}下面是对应的订单entity代码
package com.jihao.entity;
/**
* 订单
* @author JiHao
*/
public class Order {
private Long orderId;
private Integer userId;
private String status;
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
}下面是对应的订单明细entity代码
package com.jihao.entity;
/**
* 测试分片
* @author JiHao
*/
public class OrderItem {
private Long orderItemId;
private Long orderId;
private Integer userId;
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public Long getOrderItemId() {
return orderItemId;
}
public void setOrderItemId(Long orderItemId) {
this.orderItemId = orderItemId;
}
}下面是测试的controller,并没有写Junit测试。
package com.jihao.controller.test;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import com.jihao.dao.TestShardingMapper;
import com.jihao.entity.Order;
import com.jihao.entity.OrderItem;
import com.jihao.result.Result;
import com.jihao.result.ResultUtil;
/**
* 测试分片
* @author JiHao
*
*/
@Controller
@RequestMapping(value = "test")
public class TestShardingController {
@Autowired
private TestShardingMapper testShardingMapper;
/**
* 测试添加
* @return
*/
@ResponseBody
@GetMapping(value = "/testAdd")
public String testAdd(){
for (int i = 0; i < 10; i++) {
Order order = new Order();
// order.setUserId(50);
// order.setUserId(51);
// order.setUserId(10001);
order.setUserId(20001);
order.setStatus("INSERT_TEST");
int count = testShardingMapper.insert(order);
System.out.println(count);
long orderId = order.getOrderId();
System.out.println(order.getOrderId());
OrderItem item = new OrderItem();
item.setOrderId(orderId);
// order.setUserId(50);
// order.setUserId(51);
// order.setUserId(10001);
order.setUserId(20001);
testShardingMapper.insertItem(item);
}
return "success";
}
/**
* 测试搜索
* @return
*/
@ResponseBody
@GetMapping(value = "/testSearch")
public Result searchData(){
List<Order> list = testShardingMapper.searchOrder();
System.out.println(list.size() + " all");
List<Order> list1 = testShardingMapper.queryWithIn();
System.out.println(list1.size() + " In");
List<Order> list2 = testShardingMapper.queryWithEqual();
System.out.println(list2.size() + " Equal");
List<Order> list3 = testShardingMapper.queryWithBetween();
System.out.println(list3.size() + " Between");
List<Map<String, Object>> list4 = testShardingMapper.queryUser();
System.out.println(list4.size() + " user");
return ResultUtil.success(null);
}
}这里要重点提出来的是做搜索测试的时候,因为主从库都在我本地服务器上,并没有做主从复制,大家可以根据我上篇博文配置一下就可以顺利操作了,如果没有配置的话从库里是不会有数据的,所以在做完写操作时把主库中的数据手动传输给从库,这样才能读出数据。
“SpringBoot怎么使用Sharding-JDBC实现数据分片和读写分离”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



