еҰӮдҪ•зҗҶи§ЈPythonВ LeNetзҪ‘з»ңеҸҠpytorchе®һзҺ°
еҰӮдҪ•зҗҶи§ЈPython LeNetзҪ‘з»ңеҸҠpytorchе®һзҺ°пјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
1.LeNetд»Ӣз»Қ
LeNetзҘһз»ҸзҪ‘з»ңз”ұж·ұеәҰеӯҰд№ дёүе·ЁеӨҙд№ӢдёҖзҡ„Yan LeCunжҸҗеҮәпјҢд»–еҗҢж—¶д№ҹжҳҜеҚ·з§ҜзҘһз»ҸзҪ‘з»ң (CNNпјҢConvolutional Neural Networks)д№ӢзҲ¶гҖӮLeNetдё»иҰҒз”ЁжқҘиҝӣиЎҢжүӢеҶҷеӯ—з¬Ұзҡ„иҜҶеҲ«дёҺеҲҶзұ»пјҢ并еңЁзҫҺеӣҪзҡ„银иЎҢдёӯжҠ•е…ҘдәҶдҪҝз”ЁгҖӮLeNetзҡ„е®һзҺ°зЎ®з«ӢдәҶCNNзҡ„з»“жһ„пјҢзҺ°еңЁзҘһз»ҸзҪ‘з»ңдёӯзҡ„и®ёеӨҡеҶ…е®№еңЁLeNetзҡ„зҪ‘з»ңз»“жһ„дёӯйғҪиғҪзңӢеҲ°пјҢдҫӢеҰӮеҚ·з§ҜеұӮпјҢPoolingеұӮпјҢReLUеұӮгҖӮиҷҪ然LeNetж—©еңЁ20дё–зәӘ90е№ҙд»Је°ұе·Із»ҸжҸҗеҮәдәҶпјҢдҪҶз”ұдәҺеҪ“ж—¶зјәд№ҸеӨ§и§„жЁЎзҡ„и®ӯз»ғж•°жҚ®пјҢи®Ўз®—жңә硬件зҡ„жҖ§иғҪд№ҹиҫғдҪҺпјҢеӣ жӯӨLeNetзҘһз»ҸзҪ‘з»ңеңЁеӨ„зҗҶеӨҚжқӮй—®йўҳж—¶ж•Ҳжһң并дёҚзҗҶжғігҖӮиҷҪ然LeNetзҪ‘з»ңз»“жһ„жҜ”иҫғз®ҖеҚ•пјҢдҪҶжҳҜеҲҡеҘҪйҖӮеҗҲзҘһз»ҸзҪ‘з»ңзҡ„е…Ҙй—ЁеӯҰд№ гҖӮ
2.LetNetзҪ‘з»ңжЁЎеһӢ
LeNetзҪ‘з»ңжЁЎеһӢдёҖиҲ¬жҢҮLeNet-5пјҢзӣёдҝЎеӨ§е®¶еӯҰд№ иҝҷдёӘжЁЎеһӢзҡ„ж—¶еҖҷдёҖе®ҡйғҪи§ҒиҝҮиҝҷеј еӣҫзүҮеҗ§

иҝҷеј еӣҫд№ҹжҳҜеҺҹи®әж–Үдёӯзҡ„дёҖеј жЁЎеһӢеӣҫпјҢиҝҷж ·еӯҗзңӢеҸҜиғҪдјҡи§үеҫ—жңүзӮ№дёҚд№ жғҜпјҢдёӢйқўиҝҷеј еӣҫжҳҜжң¬дәәеңЁdrawioиҪҜ件дёҠеҲ¶дҪңзҡ„зҪ‘з»ңжЁЎеһӢеӣҫпјҢеҰӮдёӢ:
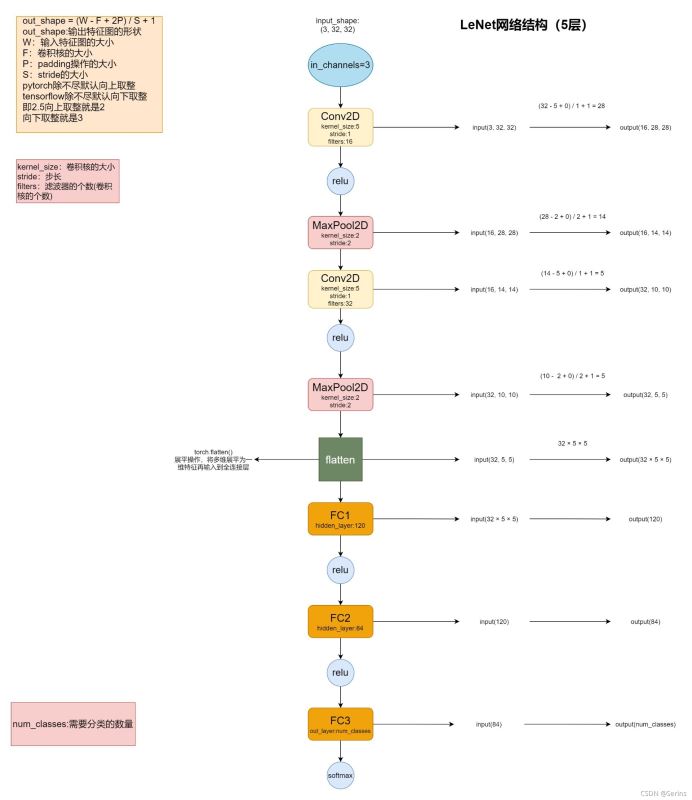
зә жӯЈдёҖдёӢпјҢдёҠеӣҫдёӯ第дәҢдёӘConv2dеұӮеҗҺйқўзҡ„и®Ўз®—з»“жһңеә”иҜҘдёә10,еҶҷжҲҗдәҶ5
зӣёдҝЎеӯҰд№ дәҶеҚ·з§ҜзҘһз»ҸзҪ‘з»ңеҹәзЎҖзҡ„жңӢеҸӢ们еә”иҜҘиғҪеҫҲжё…жҷ°зҡ„зңӢжҮӮиҝҷеј еӣҫеҗ§пјҢеҜ№дәҺеҸіиҫ№зҡ„и®Ўз®—еңЁеӣҫзҡ„е·ҰдёҠи§’д№ҹз»ҷеҮәдәҶе…¬ејҸпјҢдёҠеӣҫдёӯжҜҸдёҖеұӮзҡ„иҫ“е…ҘеҪўзҠ¶д»ҘеҸҠиҫ“еҮәеҪўзҠ¶жҲ‘йғҪиҜҰз»Ҷзҡ„дёәеӨ§е®¶еҶҷеҮәжқҘдәҶпјҢеҜ№дәҺи®Ўз®—е…¬ејҸе’ҢжЁЎеһӢеӨ§иҮҙзҡ„з»“жһ„пјҢзңӢдёӢйқўиҝҷеј еӣҫд№ҹеҸҜд»Ҙ(е»әи®®еҜ№еә”дёҠдёӢеӣҫдёҖиө·зңӢжӣҙе®№жҳ“зҗҶи§Ј)

LeNet-5зҪ‘з»ңжЁЎеһӢз®ҖеҚ•зҡ„е°ұеҢ…еҗ«дәҶеҚ·з§ҜеұӮпјҢжңҖеӨ§жұ еҢ–еұӮпјҢе…ЁиҝһжҺҘеұӮд»ҘеҸҠreluпјҢsoftmaxжҝҖжҙ»еҮҪж•°пјҢжЁЎеһӢдёӯзҡ„иҫ“е…ҘеӣҫзүҮеӨ§е°Ҹд»ҘеҸҠжҜҸдёҖеұӮзҡ„еҚ·з§Ҝж ёдёӘж•°пјҢжӯҘй•ҝйғҪжҳҜжЁЎеһӢеҲ¶е®ҡеҘҪзҡ„пјҢдёҖиҲ¬дёҚиҰҒйҡҸж„Ҹдҝ®ж”№пјҢиғҪж”№зҡ„жҳҜжңҖеҗҺзҡ„иҫ“еҮәз»“жһңпјҢеҚіеҲҶзұ»ж•°йҮҸ(num_classes)гҖӮflattenж“ҚдҪңд№ҹеҸ«жүҒе№іеҢ–ж“ҚдҪңпјҢжҲ‘们йғҪзҹҘйҒ“иҫ“е…ҘеҲ°е…ЁиҝһжҺҘеұӮдёӯзҡ„жҳҜдёҖдёӘдёӘзҡ„зү№еҫҒпјҢеҸҠдёҖз»ҙеҗ‘йҮҸпјҢдҪҶжҳҜеҚ·з§ҜзҪ‘з»ңзү№еҫҒжҸҗеҸ–еҮәжқҘзҡ„зү№еҫҒзҹ©йҳө并йқһдёҖз»ҙпјҢиҰҒйҖҒе…Ҙе…ЁиҝһжҺҘеұӮпјҢжүҖд»ҘйңҖиҰҒflattenж“ҚдҪңе°Ҷе®ғеұ•е№іжҲҗдёҖз»ҙгҖӮ
3.pytorchе®һзҺ°LeNet
pythonд»Јз ҒеҰӮдёӢ
from torch import nn
import torch
import torch.nn.functional as F
'''
иҜҙжҳҺ:
1.LeNetжҳҜ5еұӮзҪ‘з»ң
2.nn.ReLU(inplace=True) еҸӮж•°дёәTrueжҳҜдёәдәҶд»ҺдёҠеұӮзҪ‘з»ңConv2dдёӯдј йҖ’дёӢжқҘзҡ„tensorзӣҙжҺҘиҝӣиЎҢдҝ®ж”№пјҢиҝҷж ·иғҪеӨҹиҠӮзңҒиҝҗз®—еҶ…еӯҳпјҢдёҚз”ЁеӨҡеӯҳеӮЁе…¶д»–еҸҳйҮҸ
3.жң¬жЁЎеһӢзҡ„з»ҙеәҰжіЁйҮҠеқҮзңҒз•ҘдәҶN(batch_size)зҡ„еӨ§е°Ҹ,еҚіinput(3, 32, 32)-->input(N, 3, 32, 32)
4.nn.init.xavier_uniform_(m.weight)
з”ЁдёҖдёӘеқҮеҢҖеҲҶеёғз”ҹжҲҗеҖј,еЎ«е……иҫ“е…Ҙзҡ„еј йҮҸжҲ–еҸҳйҮҸ,з»“жһңеј йҮҸдёӯзҡ„еҖјйҮҮж ·иҮӘU(-a, a)пјҢ
е…¶дёӯa = gain * sqrt( 2/(fan_in + fan_out))* sqrt(3),
gainжҳҜеҸҜйҖүзҡ„зј©ж”ҫеӣ еӯҗ,й»ҳи®Өдёә1
'fan_in'дҝқз•ҷеүҚеҗ‘дј ж’ӯж—¶жқғеҖјж–№е·®зҡ„йҮҸзә§,'fan_out'дҝқз•ҷеҸҚеҗ‘дј ж’ӯж—¶зҡ„йҮҸзә§
5.nn.init.constant_(m.bias, 0)
дёәжүҖжңүз»ҙеәҰtensorеЎ«е……дёҖдёӘеёёйҮҸ0
'''
class LeNet(nn.Module):
def __init__(self, num_classes=10, init_weights=False):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1)
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.relu = nn.ReLU(True)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(32 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.conv1(x) # input(3, 32, 32) output(16, 28, 28)
x = self.relu(x) # жҝҖжҙ»еҮҪж•°
x = self.maxpool1(x) # output(16, 14, 14)
x = self.conv2(x) # output(32, 10, 10)
x = self.relu(x) # жҝҖжҙ»еҮҪж•°
x = self.maxpool2(x) # output(32, 5, 5)
x = torch.flatten(x, start_dim=1) # output(32*5*5) Nд»ЈиЎЁbatch_size
x = self.fc1(x) # output(120)
x = self.relu(x) # жҝҖжҙ»еҮҪж•°
x = self.fc2(x) # output(84)
x = self.relu(x) # жҝҖжҙ»еҮҪж•°
x = self.fc3(x) # output(num_classes)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
жҲ–иҖ…
дёӢйқўиҝҷдёҖз§ҚжІЎжңүиҮӘе·ұеҲқе§ӢеҢ–жқғйҮҚе’ҢеҒҸзҪ®пјҢе°ұдјҡдҪҝз”Ёй»ҳи®Өзҡ„еҲқе§ӢеҢ–ж–№ејҸ
import torch.nn as nn
import torch.nn.functional as F
import torch
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(x.size(0), -1) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
nn.Linearе°ұжҳҜе…ЁиҝһжҺҘеұӮпјҢйҷӨдәҶжңҖеҗҺдёҖдёӘе…ЁиҝһжҺҘеұӮпјҢе…¶е®ғеқҮйңҖиҰҒreluжҝҖжҙ»пјҢй»ҳи®Өж— paddingж“ҚдҪң
nn.Conv2dеҜ№еә”зҡ„еҸӮж•°йЎәеәҸдёҖе®ҡиҰҒи®°дҪҸ:
1.in_channels:иҫ“е…Ҙзҡ„йҖҡйҒ“ж•°жҲ–иҖ…ж·ұеәҰ
2.out_channels:иҫ“еҮәзҡ„йҖҡйҒ“ж•°жҲ–иҖ…ж·ұеәҰ
3.kernel_size:еҚ·з§Ҝж ёзҡ„еӨ§е°Ҹ
4.stride:жӯҘй•ҝеӨ§е°Ҹ,й»ҳи®Ө1
5.padding:paddingзҡ„еӨ§е°Ҹ,й»ҳи®Ө0
6.dilation:иҶЁиғҖеӨ§е°Ҹ,й»ҳи®Ө1пјҢжҡӮж—¶з”ЁдёҚеҲ°
7.group:еҲҶз»„з»„ж•°пјҢй»ҳи®Ө1
8.bias:й»ҳи®ӨTrueпјҢеёғе°”еҖјпјҢжҳҜеҗҰз”ЁеҒҸзҪ®еҖј
9.padding_mode:й»ҳи®Өз”Ё0еЎ«е……
и®°дёҚдҪҸеҸӮж•°йЎәеәҸд№ҹжІЎе…ізі»пјҢдҪҶйңҖиҰҒи®°дҪҸеҸӮж•°еҗҚз§°
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҰӮдҪ•зҗҶи§ЈPython LeNetзҪ‘з»ңеҸҠpytorchе®һзҺ°зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





