еҰӮдҪ•еҲҶжһҗPythonе…Ёж Ҳдёӯзҡ„йҳҹеҲ—
еҰӮдҪ•еҲҶжһҗPythonе…Ёж Ҳдёӯзҡ„йҳҹеҲ—пјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
1. lockдә’ж–Ҙй”Ғ
зҹҘиҜҶзӮ№пјҡ
lock.acquire()# дёҠй”Ғ
lock.release()# и§Јй”Ғ
#еҗҢдёҖж—¶й—ҙе…Ғи®ёдёҖдёӘиҝӣзЁӢдёҠдёҖжҠҠй”Ғ е°ұжҳҜLock
еҠ й”ҒеҸҜд»ҘдҝқиҜҒеӨҡдёӘиҝӣзЁӢдҝ®ж”№еҗҢдёҖеқ—ж•°жҚ®ж—¶пјҢеҗҢдёҖж—¶й—ҙеҸӘиғҪжңүдёҖдёӘд»»еҠЎеҸҜд»ҘиҝӣиЎҢдҝ®ж”№пјҢеҚідёІиЎҢзҡ„дҝ®ж”№пјҢжІЎй”ҷпјҢйҖҹеәҰжҳҜж…ўдәҶпјҢдҪҶзүәзүІйҖҹеәҰеҚҙдҝқиҜҒдәҶж•°жҚ®е®үе…ЁгҖӮ
#еҗҢдёҖж—¶й—ҙе…Ғи®ёеӨҡдёӘиҝӣзЁӢдёҠеӨҡжҠҠй”Ғ е°ұжҳҜ[дҝЎеҸ·йҮҸSemaphore]
дҝЎеҸ·йҮҸжҳҜй”Ғзҡ„еҸҳеҪў: е®һйҷ…е®һзҺ°жҳҜ и®Ўж•°еҷЁ + й”Ғ,еҗҢж—¶е…Ғи®ёеӨҡдёӘиҝӣзЁӢдёҠй”Ғ
# дә’ж–Ҙй”ҒLock : дә’ж–Ҙй”Ғе°ұжҳҜиҝӣзЁӢзҡ„дә’зӣёжҺ’ж–Ҙ,и°Ғе…ҲжҠўеҲ°иө„жәҗ,и°Ғе°ұдёҠй”Ғж”№иө„жәҗеҶ…е®№,дёәдәҶдҝқиҜҒж•°жҚ®зҡ„еҗҢжӯҘжҖ§
# жіЁж„Ҹ:еӨҡдёӘй”ҒдёҖиө·дёҠ,дёҚејҖй”Ғ,дјҡйҖ жҲҗжӯ»й”Ғ.дёҠй”Ғе’Ңи§Јй”ҒжҳҜдёҖеҜ№.
зЁӢеәҸе®һзҺ°пјҡ
# ### й”Ғ lock дә’ж–Ҙй”Ғ
from multiprocessing import Process,Lock
""" дёҠй”Ғе’Ңи§Јй”ҒжҳҜдёҖеҜ№, иҝһз»ӯдёҠй”ҒдёҚи§Јй”ҒжҳҜжӯ»й”Ғ ,еҸӘжңүеңЁи§Јй”Ғзҡ„зҠ¶жҖҒдёӢ,е…¶д»–иҝӣзЁӢжүҚжңүжңәдјҡдёҠй”Ғ """
"""
# еҲӣе»әдёҖжҠҠй”Ғ
lock = Lock()
# дёҠй”Ғ
lock.acquire()
# lock.acquire() # иҝһз»ӯдёҠй”Ғ,йҖ жҲҗдәҶжӯ»й”ҒзҺ°иұЎ;
print("жҲ‘еңЁиў…иў…зӮҠзғҹ .. дҪ еңЁз„ҰжҖҘзӯүеҫ… ... еҺ•жүҖиҝӣиЎҢж—¶ ... ")
# и§Јй”Ғ
lock.release()
"""
# ### 12306 жҠўзҘЁиҪҜ件
import json,time,random
# 1.иҜ»еҶҷж•°жҚ®еә“еҪ“дёӯзҡ„зҘЁж•°
def wr_info(sign , dic=None):
if sign == "r":
with open("ticket",mode="r",encoding="utf-8") as fp:
dic = json.load(fp)
return dic
elif sign == "w":
with open("ticket",mode="w",encoding="utf-8") as fp:
json.dump(dic,fp)
# dic = wr_info("w",dic={"count":0})
# print(dic , type(dic) )
# 2.жү§иЎҢжҠўзҘЁзҡ„ж–№жі•
def get_ticket(person):
# е…ҲиҺ·еҸ–ж•°жҚ®еә“дёӯе®һйҷ…зҘЁж•°
dic = wr_info("r")
# жЁЎжӢҹдёҖдёӢзҪ‘з»ң延иҝҹ
time.sleep(random.uniform(0.1,0.7))
# еҲӨж–ӯзҘЁж•°
if dic["count"] > 0:
print("{}жҠўеҲ°зҘЁдәҶ".format(person))
# жҠўеҲ°зҘЁеҗҺ,и®©еҪ“еүҚзҘЁж•°еҮҸ1
dic["count"] -= 1
# жӣҙж–°ж•°жҚ®еә“дёӯзҡ„зҘЁж•°
wr_info("w",dic)
else:
print("{}жІЎжңүжҠўеҲ°зҘЁе“Ұ".format(person))
# 3.еҜ№жҠўзҘЁе’ҢиҜ»еҶҷзҘЁж•°еҒҡдёҖдёӘз»ҹдёҖзҡ„и°ғз”Ё
def main(person,lock):
# жҹҘзңӢеү©дҪҷзҘЁж•°
dic = wr_info("r")
print("{}жҹҘзңӢзҘЁж•°еү©дҪҷ: {}".format(person,dic["count"]))
# дёҠй”Ғ
lock.acquire()
# ејҖе§ӢжҠўзҘЁ
get_ticket(person)
# и§Јй”Ғ
lock.release()
if __name__ == "__main__":
lock = Lock()
lst = ["жўҒж–°е®Ү","еә·иЈ•еә·","еј дҝқеј ","дәҺжңқеҝ—","и–ӣе®ҮеҒҘ","йҹ©з‘һз‘һ","еҒҮж‘”е…Ҳ","еҲҳеӯҗж¶ӣ","й»ҺжҳҺиҫү","иөөеҮӨеӢҮ"]
for i in lst:
p = Process( target=main,args=( i , lock ) )
p.start()
"""
еҲӣе»әиҝӣзЁӢ,ејҖе§ӢжҠўзҘЁжҳҜејӮжӯҘ并еҸ‘зЁӢеәҸ
зӣҙеҲ°ејҖе§ӢжҠўзҘЁзҡ„ж—¶еҖҷ,еҸҳжҲҗеҗҢжӯҘзЁӢеәҸ,
е…ҲжҠўеҲ°й”Ғиө„жәҗзҡ„е…Ҳжү§иЎҢ,еҗҺжҠўеҲ°й”Ғиө„жәҗзҡ„еҗҺжү§иЎҢ;
жҢүз…§йЎәеәҸдҫқж¬Ўжү§иЎҢ;жҳҜеҗҢжӯҘзЁӢеәҸ;
жҠўзҘЁзҡ„ж—¶еҖҷпјҢеҸҳжҲҗеҗҢжӯҘзЁӢеәҸпјҢеҘҪеӨ„жҳҜеҸҜд»ҘзӯүеҲ°ж•°жҚ®дҝ®ж”№е®ҢжҲҗд№ӢеҗҺпјҢеңЁи®©дёӢдёҖдёӘдәәжҠўпјҢдҝқиҜҒж•°жҚ®дёҚд№ұгҖӮ
еҰӮжһңдёҚдёҠй”Ғзҡ„иҜқпјҢеҸӘеү©дёҖеј зҘЁзҡ„ж—¶еҖҷпјҢйӮЈд№ҲжүҖжңүзҡ„дәәйғҪиғҪжҠўеҲ°зҘЁпјҢеӣ дёәзЁӢеәҸжү§иЎҢзҡ„йҖҹеәҰеӨӘеҝ«пјҢжүҖд»ҘжҺҘиҝ‘еҗҢжӯҘиҝӣзЁӢпјҢеҜјиҮҙж•°жҚ®д№ҹдёҚеҜ№гҖӮ
""" ticketж–Ү件
{"count": 0}
2. дәӢ件_зәўз»ҝзҒҜж•Ҳжһң
2.1 дҝЎеҸ·йҮҸ_semaphore
# ### дҝЎеҸ·йҮҸ Semaphore жң¬иҙЁдёҠе°ұжҳҜй”Ғ,еҸӘдёҚиҝҮжҳҜеӨҡдёӘиҝӣзЁӢдёҠеӨҡжҠҠй”Ғ,еҸҜд»ҘжҺ§еҲ¶дёҠй”Ғзҡ„ж•°йҮҸ
"""Semaphore = lock + ж•°йҮҸ """
from multiprocessing import Semaphore , Process
import time , random
"""
# еҗҢдёҖж—¶й—ҙе…Ғи®ёеӨҡдёӘиҝӣзЁӢдёҠ5жҠҠй”Ғ
sem = Semaphore(5)
#дёҠй”Ғ
sem.acquire()
print("жү§иЎҢж“ҚдҪң ... ")
#и§Јй”Ғ
sem.release()
"""
def singsong_ktv(person,sem):
# дёҠй”Ғ
sem.acquire()
print("{}иҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~".format(person))
# е”ұдёҖж®өж—¶й—ҙ
time.sleep( random.randrange(4,8) ) # 4 5 6 7
print("{}зҰ»ејҖдәҶе”ұеҗ§ktv , е”ұе®ҢдәҶ ... ".format(person))
# и§Јй”Ғ
sem.release()
if __name__ == "__main__":
sem = Semaphore(5)
lst = ["иөөеҮӨеӢҮ" , "жІҲжҖқйӣЁ", "иөөдёҮйҮҢ" , "еј е®Ү" , "еҒҮзҺҮе…Ҳ" , "еӯҷжқ°йҫҷ" , "йҷҲз’җ" , "зҺӢйӣЁж¶ө" , "жқЁе…ғж¶ӣ" , "еҲҳдёҖеҮӨ" ]
for i in lst:
p = Process(target=singsong_ktv , args = (i , sem) )
p.start()
"""
# жҖ»з»“: Semaphore еҸҜд»Ҙи®ҫзҪ®дёҠй”Ғзҡ„ж•°йҮҸ , еҗҢдёҖж—¶й—ҙдёҠеӨҡжҠҠй”Ғ
еҲӣе»әиҝӣзЁӢж—¶,жҳҜејӮжӯҘ并еҸ‘,жү§иЎҢд»»еҠЎж—¶,жҳҜеҗҢжӯҘзЁӢеәҸ;
"""
# иөөдёҮйҮҢиҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~
# иөөеҮӨеӢҮиҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~
# еј е®Үиҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~
# жІҲжҖқйӣЁиҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~
# еӯҷжқ°йҫҷиҝӣе…ҘдәҶе”ұеҗ§ktv , жӯЈеңЁе”ұжӯҢ ~2.2 дәӢ件_зәўз»ҝзҒҜж•Ҳжһң
# ### дәӢ件 (Event)
"""
# йҳ»еЎһдәӢ件 пјҡ
e = Event()з”ҹжҲҗдәӢ件еҜ№иұЎe
e.wait()еҠЁжҖҒз»ҷзЁӢеәҸеҠ йҳ»еЎһ , зЁӢеәҸеҪ“дёӯжҳҜеҗҰеҠ йҳ»еЎһе®Ңе…ЁеҸ–еҶідәҺиҜҘеҜ№иұЎдёӯзҡ„is_set() [й»ҳи®Өиҝ”еӣһеҖјжҳҜFalse]
# еҰӮжһңжҳҜTrue дёҚеҠ йҳ»еЎһ
# еҰӮжһңжҳҜFalse еҠ йҳ»еЎһ
# жҺ§еҲ¶иҝҷдёӘеұһжҖ§зҡ„еҖј
# set()ж–№жі• е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗTrue
# clear()ж–№жі• е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗFalse
# is_set()ж–№жі• еҲӨж–ӯеҪ“еүҚзҡ„еұһжҖ§жҳҜеҗҰдёәTrue (й»ҳи®ӨдёҠжқҘжҳҜFalse)
"""
from multiprocessing import Process,Event
import time , random
# 1
'''
e = Event()
# й»ҳи®ӨеұһжҖ§еҖјжҳҜFalse.
print(e.is_set())
# еҲӨж–ӯеҶ…йғЁжҲҗе‘ҳеұһжҖ§жҳҜеҗҰжҳҜFalse
e.wait()
# еҰӮжһңжҳҜFalse , д»Јз ҒзЁӢеәҸйҳ»еЎһ
print(" д»Јз Ғжү§иЎҢдёӯ ... ")
'''
# 2
'''
e = Event()
# е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗTrue
e.set()
# еҲӨж–ӯеҶ…йғЁжҲҗе‘ҳеұһжҖ§жҳҜеҗҰжҳҜTrue
e.wait()
# еҰӮжһңжҳҜTrue , д»Јз ҒзЁӢеәҸдёҚйҳ»еЎһ
print(" д»Јз Ғжү§иЎҢдёӯ ... ")
# е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗFalse
e.clear()
e.wait()
print(" д»Јз Ғжү§иЎҢдёӯ .... 2")
'''
# 3
"""
e = Event()
# wait(3) д»ЈиЎЁжңҖеӨҡзӯүеҫ…3з§’;
e.wait(3)
print(" д»Јз Ғжү§иЎҢдёӯ .... 3")
"""
# ### жЁЎжӢҹз»Ҹе…ёзәўз»ҝзҒҜж•Ҳжһң
# зәўз»ҝзҒҜеҲҮжҚў
def traffic_light(e):
print("зәўзҒҜдә®")
while True:
if e.is_set():
# з»ҝзҒҜзҠ¶жҖҒ -> еҲҮзәўзҒҜ
time.sleep(1)
print("зәўзҒҜдә®")
# True => False
e.clear()
else:
# зәўзҒҜзҠ¶жҖҒ -> еҲҮз»ҝзҒҜ
time.sleep(1)
print("з»ҝзҒҜдә®")
# False => True
e.set()
# e = Event()
# traffic_light(e)
# иҪҰзҡ„зҠ¶жҖҒ
def car(e,i):
# еҲӨж–ӯжҳҜеҗҰжҳҜзәўзҒҜ,еҰӮжһңжҳҜеҠ дёҠwaitйҳ»еЎһ
if not e.is_set():
print("car{} еңЁзӯүеҫ… ... ".format(i))
e.wait()
# еҗҰеҲҷдёҚжҳҜ,д»ЈиЎЁз»ҝзҒҜйҖҡиЎҢ;
print("car{} йҖҡиЎҢдәҶ ... ".format(i))
"""
# 1.е…ЁеӣҪзәўз»ҝзҒҜ
if __name__ == "__main__":
e = Event()
# еҲӣе»әдәӨйҖҡзҒҜ
p1 = Process(target=traffic_light , args=(e,))
p1.start()
# еҲӣе»әе°ҸиҪҰиҝӣзЁӢ
for i in range(1,21):
time.sleep(random.randrange(2))
p2 = Process(target=car , args=(e,i))
p2.start()
"""
# 2.еҢ…еӨҙзәўз»ҝзҒҜ,жІЎжңүиҪҰзҡ„ж—¶еҖҷ,жҠҠзәўз»ҝзҒҜе…ідәҶ,зңҒз”ө;
if __name__ == "__main__":
lst = []
e = Event()
# еҲӣе»әдәӨйҖҡзҒҜ
p1 = Process(target=traffic_light , args=(e,))
# и®ҫзҪ®зәўз»ҝзҒҜдёәе®ҲжҠӨиҝӣзЁӢ
p1.daemon = True
p1.start()
# еҲӣе»әе°ҸиҪҰиҝӣзЁӢ
for i in range(1,21):
time.sleep(random.randrange(2))
p2 = Process(target=car , args=(e,i))
lst.append(p2)
p2.start()
# и®©жүҖжңүзҡ„е°ҸиҪҰе…ЁйғЁи·‘е®Ң,жҠҠзәўз»ҝзҒҜзӮёйЈһ
print(lst)
for i in lst:
i.join()
print("е…ій—ӯжҲҗеҠҹ .... ")дәӢ件зҹҘиҜҶзӮ№пјҡ
# йҳ»еЎһдәӢ件 пјҡ
e = Event()з”ҹжҲҗдәӢ件еҜ№иұЎe
e.wait()еҠЁжҖҒз»ҷзЁӢеәҸеҠ йҳ»еЎһ , зЁӢеәҸеҪ“дёӯжҳҜеҗҰеҠ йҳ»еЎһе®Ңе…ЁеҸ–еҶідәҺиҜҘеҜ№иұЎдёӯзҡ„is_set() [й»ҳи®Өиҝ”еӣһеҖјжҳҜFalse]
# еҰӮжһңжҳҜTrue дёҚеҠ йҳ»еЎһ
# еҰӮжһңжҳҜFalse еҠ йҳ»еЎһ
# жҺ§еҲ¶иҝҷдёӘеұһжҖ§зҡ„еҖј
# set()ж–№жі• е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗTrue
# clear()ж–№жі• е°ҶиҝҷдёӘеұһжҖ§зҡ„еҖјж”№жҲҗFalse
# is_set()ж–№жі• еҲӨж–ӯеҪ“еүҚзҡ„еұһжҖ§жҳҜеҗҰдёәTrue (й»ҳи®ӨдёҠжқҘжҳҜFalse)
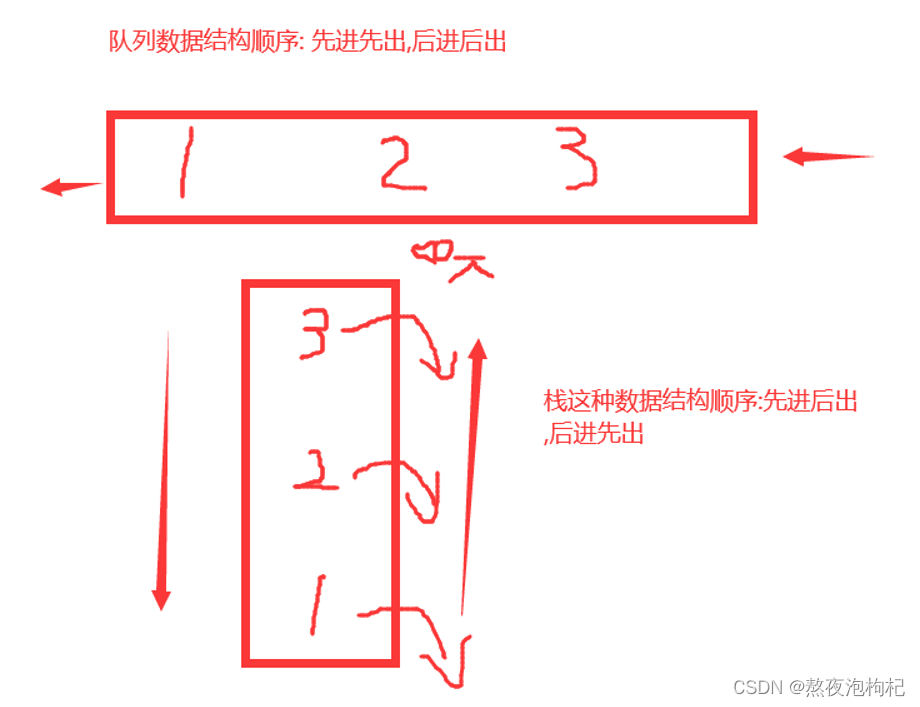
3. queueиҝӣзЁӢйҳҹеҲ—
# ### иҝӣзЁӢйҳҹеҲ—пјҲиҝӣзЁӢдёҺеӯҗиҝӣзЁӢжҳҜзӣёдә’йҡ”зҰ»зҡ„пјҢеҰӮжһңдёӨиҖ…жғіиҰҒиҝӣиЎҢйҖҡдҝЎпјҢеҸҜд»ҘеҲ©з”ЁйҳҹеҲ—е®һзҺ°пјү
from multiprocessing import Process,Queue
# еј•е…ҘзәҝзЁӢжЁЎеқ—; дёәдәҶжҚ•жҚүqueue.EmptyејӮеёё;
import queue
# 1.еҹәжң¬иҜӯжі•
"""йЎәеәҸ: е…Ҳиҝӣе…ҲеҮә,еҗҺиҝӣеҗҺеҮә"""
# еҲӣе»әиҝӣзЁӢйҳҹеҲ—
q = Queue()
# put() еӯҳж”ҫ
q.put(1)
q.put(2)
q.put(3)
# get() иҺ·еҸ–
"""еңЁиҺ·еҸ–дёҚеҲ°д»»дҪ•ж•°жҚ®ж—¶,дјҡеҮәзҺ°йҳ»еЎһ"""
# print( q.get() )
# print( q.get() )
# print( q.get() )
# print( q.get() )
# get_nowait() жӢҝдёҚеҲ°ж•°жҚ®жҠҘејӮеёё
"""[windows]ж•ҲжһңжӯЈеёё [linux]дёҚе…је®№"""
try:
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
except : #queue.Empty
pass
# put_nowait() йқһйҳ»еЎһзүҲжң¬зҡ„put
# и®ҫзҪ®еҪ“еүҚйҳҹеҲ—жңҖеӨ§й•ҝеәҰдёә3 ( е…ғзҙ дёӘж•°жңҖеӨҡжҳҜ3дёӘ )
"""еңЁжҢҮе®ҡйҳҹеҲ—й•ҝеәҰзҡ„жғ…еҶөдёӢ,еҰӮжһңеЎһе…ҘиҝҮеӨҡзҡ„ж•°жҚ®,дјҡеҜјиҮҙйҳ»еЎһ"""
# q2 = Queue(3)
# q2.put(111)
# q2.put(222)
# q2.put(333)
# q2.put(444)
"""дҪҝз”Ёput_nowait еңЁйҳҹеҲ—е·Іж»Ўзҡ„жғ…еҶөдёӢ,еЎһе…Ҙж•°жҚ®дјҡзӣҙжҺҘжҠҘй”ҷ"""
q2 = Queue(3)
try:
q2.put_nowait(111)
q2.put_nowait(222)
q2.put_nowait(333)
q2.put_nowait(444)
except:
pass
# 2.иҝӣзЁӢй—ҙзҡ„йҖҡдҝЎIPC
def func(q):
# 2.еӯҗиҝӣзЁӢиҺ·еҸ–дё»иҝӣзЁӢеӯҳж”ҫзҡ„ж•°жҚ®
res = q.get()
print(res,"<22>")
# 3.еӯҗиҝӣзЁӢдёӯеӯҳж”ҫж•°жҚ®
q.put("еҲҳдёҖзјқ")
if __name__ == "__main__":
q3 = Queue()
p = Process(target=func,args=(q3,))
p.start()
# 1.дё»иҝӣзЁӢеӯҳе…Ҙж•°жҚ®
q3.put("иөөеҮӨеӢҮ")
# дёәдәҶзӯүеҫ…еӯҗиҝӣзЁӢжҠҠж•°жҚ®еӯҳж”ҫйҳҹеҲ—еҗҺ,дё»иҝӣзЁӢеңЁиҺ·еҸ–ж•°жҚ®;
p.join()
# 4.дё»иҝӣзЁӢиҺ·еҸ–еӯҗиҝӣзЁӢеӯҳж”ҫзҡ„ж•°жҚ®
print(q3.get() , "<33>")е°ҸжҸҗзӨәпјҡ дёҖиҲ¬дё»иҝӣзЁӢжҜ”еӯҗиҝӣзЁӢжү§иЎҢзҡ„еҝ«дёҖдәӣ
йҳҹеҲ—зҹҘиҜҶзӮ№пјҡ
# иҝӣзЁӢй—ҙйҖҡдҝЎ IPC
# IPC Inter-Process Communication
# е®һзҺ°иҝӣзЁӢд№Ӣй—ҙйҖҡдҝЎзҡ„дёӨз§ҚжңәеҲ¶:
# з®ЎйҒ“ Pipe
# йҳҹеҲ— Queue
# put() еӯҳж”ҫ
# get() иҺ·еҸ–
# get_nowait() жӢҝдёҚеҲ°жҠҘејӮеёё
# put_nowait() йқһйҳ»еЎһзүҲжң¬зҡ„put
q.empty() жЈҖжөӢжҳҜеҗҰдёәз©ә (дәҶи§Ј)
q.full() жЈҖжөӢжҳҜеҗҰе·Із»Ҹеӯҳж»Ў (дәҶи§Ј)
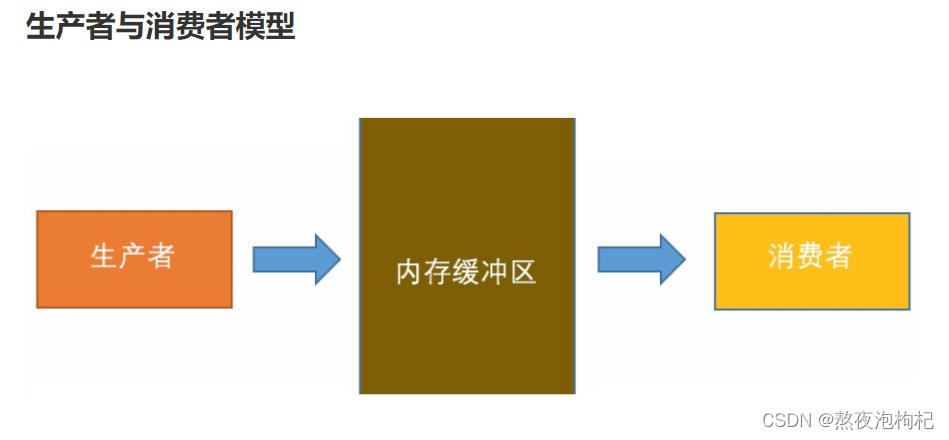
4. з”ҹдә§иҖ…ж¶Ҳиҙ№иҖ…жЁЎеһӢ
# ### з”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…жЁЎеһӢ
"""
# зҲ¬иҷ«жЎҲдҫӢ
1еҸ·иҝӣзЁӢиҙҹиҙЈжҠ“еҸ–е…¶д»–еӨҡдёӘзҪ‘з«ҷдёӯзӣёе…ізҡ„е…ій”®еӯ—дҝЎжҒҜ,жӯЈеҲҷеҢ№й…ҚеҲ°йҳҹеҲ—дёӯеӯҳеӮЁ(mysql)
2еҸ·иҝӣзЁӢиҙҹиҙЈжҠҠйҳҹеҲ—дёӯзҡ„еҶ…е®№жӢҝеҸ–еҮәжқҘ,е°Ҷз»ҸиҝҮдҝ®йҘ°еҗҺзҡ„еҶ…е®№еёғеұҖеҲ°иҮӘдёӘзҡ„зҪ‘з«ҷдёӯ
1еҸ·иҝӣзЁӢеҸҜд»ҘзҗҶи§ЈжҲҗз”ҹдә§иҖ…
2еҸ·иҝӣзЁӢеҸҜд»ҘзҗҶи§ЈжҲҗж¶Ҳиҙ№иҖ…
д»ҺзЁӢеәҸдёҠжқҘзңӢ
з”ҹдә§иҖ…иҙҹиҙЈеӯҳеӮЁж•°жҚ® (put)
ж¶Ҳиҙ№иҖ…иҙҹиҙЈиҺ·еҸ–ж•°жҚ® (get)
з”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…жҜ”иҫғзҗҶжғізҡ„жЁЎеһӢ:
з”ҹдә§еӨҡе°‘,ж¶Ҳиҙ№еӨҡе°‘ . з”ҹдә§ж•°жҚ®зҡ„йҖҹеәҰ е’Ң ж¶Ҳиҙ№ж•°жҚ®зҡ„йҖҹеәҰ зӣёеҜ№дёҖиҮҙ
"""
# 1.еҹәзЎҖзүҲз”ҹдә§зқҖж¶Ҳиҙ№иҖ…жЁЎеһӢ
"""й—®йўҳ : еҪ“еүҚжЁЎеһӢ,зЁӢеәҸдёҚиғҪжӯЈеёёз»Ҳжӯў """
"""
from multiprocessing import Process,Queue
import time,random
# ж¶Ҳиҙ№иҖ…жЁЎеһӢ
def consumer(q,name):
while True:
# иҺ·еҸ–йҳҹеҲ—дёӯзҡ„ж•°жҚ®
food = q.get()
time.sleep(random.uniform(0.1,1))
print("{}еҗғдәҶ{}".format(name,food))
# з”ҹдә§иҖ…жЁЎеһӢ
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# еұ•зӨәз”ҹдә§зҡ„ж•°жҚ®
print( "{}з”ҹдә§дәҶ{}".format( name , food+str(i) ) )
# еӯҳеӮЁз”ҹдә§зҡ„ж•°жҚ®еңЁйҳҹеҲ—дёӯ
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "иөөдёҮйҮҢ") )
p2 = Process( target=producer,args=(q , "иөөжІҲйҳі" , "йҰҷи•ү" ) )
p1.start()
p2.start()
p2.join()
"""
# 2.дјҳеҢ–жЁЎеһӢ
"""зү№зӮ№ : жүӢеҠЁеңЁйҳҹеҲ—зҡ„жңҖеҗҺ,еҠ е…Ҙж ҮиҜҶNone, з»Ҳжӯўж¶Ҳиҙ№иҖ…жЁЎеһӢ"""
"""
from multiprocessing import Process,Queue
import time,random
# ж¶Ҳиҙ№иҖ…жЁЎеһӢ
def consumer(q,name):
while True:
# иҺ·еҸ–йҳҹеҲ—дёӯзҡ„ж•°жҚ®
food = q.get()
# еҰӮжһңжңҖеҗҺдёҖж¬ЎиҺ·еҸ–зҡ„ж•°жҚ®жҳҜNone , д»ЈиЎЁйҳҹеҲ—е·Із»ҸжІЎжңүжӣҙеӨҡж•°жҚ®еҸҜд»ҘиҺ·еҸ–дәҶ,з»ҲжӯўеҫӘзҺҜ;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}еҗғдәҶ{}".format(name,food))
# з”ҹдә§иҖ…жЁЎеһӢ
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# еұ•зӨәз”ҹдә§зҡ„ж•°жҚ®
print( "{}з”ҹдә§дәҶ{}".format( name , food+str(i) ) )
# еӯҳеӮЁз”ҹдә§зҡ„ж•°жҚ®еңЁйҳҹеҲ—дёӯ
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "иөөдёҮйҮҢ") )
p2 = Process( target=producer,args=(q , "иөөжІҲйҳі" , "йҰҷи•ү" ) )
p1.start()
p2.start()
p2.join()
q.put(None) # йҰҷи•ү0 йҰҷи•ү1 йҰҷи•ү2 йҰҷи•ү3 йҰҷи•ү4 None
"""
# 3.еӨҡдёӘз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…
""" й—®йўҳ : иҷҪ然еҸҜд»Ҙи§ЈеҶій—®йўҳ , дҪҶжҳҜйңҖиҰҒеҠ е…ҘеӨҡдёӘNone , д»Јз ҒеҶ—дҪҷ"""
from multiprocessing import Process,Queue
import time,random
# ж¶Ҳиҙ№иҖ…жЁЎеһӢ
def consumer(q,name):
while True:
# иҺ·еҸ–йҳҹеҲ—дёӯзҡ„ж•°жҚ®
food = q.get()
# еҰӮжһңжңҖеҗҺдёҖж¬ЎиҺ·еҸ–зҡ„ж•°жҚ®жҳҜNone , д»ЈиЎЁйҳҹеҲ—е·Із»ҸжІЎжңүжӣҙеӨҡж•°жҚ®еҸҜд»ҘиҺ·еҸ–дәҶ,з»ҲжӯўеҫӘзҺҜ;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}еҗғдәҶ{}".format(name,food))
# з”ҹдә§иҖ…жЁЎеһӢ
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# еұ•зӨәз”ҹдә§зҡ„ж•°жҚ®
print( "{}з”ҹдә§дәҶ{}".format( name , food+str(i) ) )
# еӯҳеӮЁз”ҹдә§зҡ„ж•°жҚ®еңЁйҳҹеҲ—дёӯ
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "иөөдёҮйҮҢ") )
p1_1 = Process( target=consumer,args=(q , "иөөдё–и¶…") )
p2 = Process( target=producer,args=(q , "иөөжІҲйҳі" , "йҰҷи•ү" ) )
p2_2 = Process( target=producer,args=(q , "иөөеҮӨеӢҮ" , "еӨ§и’ң" ) )
p1.start()
p1_1.start()
p2.start()
p2_2.start()
# зӯүеҫ…жүҖжңүж•°жҚ®еЎ«е……е®ҢжҜ•
p2.join()
p2_2.join()
# жҠҠNone е…ій”®еӯ—ж”ҫеңЁж•ҙдёӘйҳҹеҲ—зҡ„жңҖеҗҺ,дҪңдёәи·іеҮәж¶Ҳиҙ№иҖ…еҫӘзҺҜзҡ„ж ҮиҜҶз¬Ұ;
q.put(None) # з»ҷ第дёҖдёӘж¶Ҳиҙ№иҖ…еҠ дёҖдёӘNone , з”ЁжқҘз»Ҳжӯў
q.put(None) # з»ҷ第дәҢдёӘж¶Ҳиҙ№иҖ…еҠ дёҖдёӘNone , з”ЁжқҘз»Ҳжӯў
# ...
5. joinablequeueйҳҹеҲ—дҪҝз”Ё
# ### JoinableQueue йҳҹеҲ—
"""
put еӯҳж”ҫ
get иҺ·еҸ–
task_done и®Ўз®—еҷЁеұһжҖ§еҖј-1
join й…ҚеҗҲtask_doneжқҘдҪҝз”Ё , йҳ»еЎһ
put дёҖж¬Ўж•°жҚ®, йҳҹеҲ—зҡ„еҶ…зҪ®и®Ўж•°еҷЁеұһжҖ§еҖј+1
get дёҖж¬Ўж•°жҚ®, йҖҡиҝҮtask_doneи®©йҳҹеҲ—зҡ„еҶ…зҪ®и®Ўж•°еҷЁеұһжҖ§еҖј-1
join: дјҡж №жҚ®йҳҹеҲ—и®Ўж•°еҷЁзҡ„еұһжҖ§еҖјжқҘеҲӨж–ӯжҳҜеҗҰйҳ»еЎһжҲ–иҖ…ж”ҫиЎҢ
йҳҹеҲ—и®Ўж•°еҷЁеұһжҖ§жҳҜ зӯүдәҺ 0 , д»Јз ҒдёҚйҳ»еЎһж”ҫиЎҢ
йҳҹеҲ—и®Ўж•°еҷЁеұһжҖ§жҳҜ дёҚзӯү 0 , ж„Ҹе‘ізқҖд»Јз Ғйҳ»еЎһ
"""
from multiprocessing import JoinableQueue
jq = JoinableQueue()
jq.put("зҺӢеҗҢеҹ№") # +1
jq.put("зҺӢдјҹ") # +2
print(jq.get())
print(jq.get())
# print(jq.get()) йҳ»еЎһ
jq.task_done() # -1
jq.task_done() # -1
jq.join()
print(" д»Јз Ғжү§иЎҢз»“жқҹ .... ")
# ### 2.дҪҝз”ЁJoinableQueue ж”№йҖ з”ҹдә§зқҖж¶Ҳиҙ№иҖ…жЁЎеһӢ
from multiprocessing import Process,Queue
import time,random
# ж¶Ҳиҙ№иҖ…жЁЎеһӢ
def consumer(q,name):
while True:
# иҺ·еҸ–йҳҹеҲ—дёӯзҡ„ж•°жҚ®
food = q.get()
time.sleep(random.uniform(0.1,1))
print("{}еҗғдәҶ{}".format(name,food))
# и®©йҳҹеҲ—зҡ„еҶ…зҪ®и®Ўж•°еҷЁеұһжҖ§-1
q.task_done()
# з”ҹдә§иҖ…жЁЎеһӢ
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# еұ•зӨәз”ҹдә§зҡ„ж•°жҚ®
print( "{}з”ҹдә§дәҶ{}".format( name , food+str(i) ) )
# еӯҳеӮЁз”ҹдә§зҡ„ж•°жҚ®еңЁйҳҹеҲ—дёӯ
q.put(food+str(i))
if __name__ == "__main__":
q = JoinableQueue()
p1 = Process( target=consumer,args=(q , "иөөдёҮйҮҢ") )
p2 = Process( target=producer,args=(q , "иөөжІҲйҳі" , "йҰҷи•ү" ) )
p1.daemon = True
p1.start()
p2.start()
p2.join()
# еҝ…йЎ»зӯүеҫ…йҳҹеҲ—дёӯзҡ„жүҖжңүж•°жҚ®е…ЁйғЁж¶Ҳиҙ№е®ҢжҜ•,еҶҚж”ҫиЎҢ
q.join()
print("зЁӢеәҸз»“жқҹ ... ")6. жҖ»з»“
ipcеҸҜд»Ҙи®©иҝӣзЁӢд№Ӣй—ҙиҝӣиЎҢйҖҡдҝЎ
lockе…¶е®һд№ҹи®©иҝӣзЁӢд№Ӣй—ҙиҝӣиЎҢйҖҡдҝЎдәҶпјҢеӨҡдёӘиҝӣзЁӢеҺ»жҠўдёҖжҠҠй”ҒпјҢдёҖдёӘиҝӣзЁӢжҠўеҲ°
иҝҷ жҠҠй”ҒдәҶпјҢе…¶д»–зҡ„иҝӣзЁӢе°ұжҠўдёҚеҲ°иҝҷжҠҠй”ҒдәҶпјҢиҝӣзЁӢйҖҡиҝҮsocketеә•еұӮдә’зӣёеҸ‘
ж¶ҲжҒҜпјҢе‘ҠиҜүе…¶д»–иҝӣзЁӢеҪ“еүҚзҠ¶жҖҒе·Із»Ҹиў«й”Ғе®ҡдәҶпјҢдёҚиғҪеҶҚејәдәҶгҖӮ
иҝӣзЁӢд№Ӣй—ҙй»ҳи®ӨжҳҜйҡ”зҰ»зҡ„пјҢдёҚиғҪйҖҡдҝЎзҡ„пјҢеҰӮжһңжғіиҰҒйҖҡдҝЎпјҢеҝ…йЎ»йҖҡиҝҮipcзҡ„
ж–№ејҸпјҲlockгҖҒjoinablequeueгҖҒManagerпјү
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎеҰӮдҪ•еҲҶжһҗPythonе…Ёж Ҳдёӯзҡ„йҳҹеҲ—зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





