MySqlдёӯsqlжҖҺд№ҲдјҳеҢ–
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶMySqlдёӯsqlжҖҺд№ҲдјҳеҢ–пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
дёҖгҖҒexplainиҝ”еӣһеҲ—з®Җд»Ӣ
1гҖҒtypeеёёз”Ёе…ій”®еӯ—
system > const > eq_ref > ref > range > index > allгҖӮ
systemпјҡиЎЁд»…жңүдёҖиЎҢпјҢеҹәжң¬з”ЁдёҚеҲ°пјӣ
constпјҡиЎЁжңҖеӨҡдёҖиЎҢж•°жҚ®й…ҚеҗҲпјҢдё»й”®жҹҘиҜўж—¶и§ҰеҸ‘иҫғеӨҡпјӣ
eq_refпјҡеҜ№дәҺжҜҸдёӘжқҘиҮӘдәҺеүҚйқўзҡ„иЎЁзҡ„иЎҢз»„еҗҲпјҢд»ҺиҜҘиЎЁдёӯиҜ»еҸ–дёҖиЎҢгҖӮиҝҷеҸҜиғҪжҳҜжңҖеҘҪзҡ„иҒ”жҺҘзұ»еһӢпјҢйҷӨдәҶconstзұ»еһӢпјӣ
refпјҡеҜ№дәҺжҜҸдёӘжқҘиҮӘдәҺеүҚйқўзҡ„иЎЁзҡ„иЎҢз»„еҗҲпјҢжүҖжңүжңүеҢ№й…Қзҙўеј•еҖјзҡ„иЎҢе°Ҷд»Һиҝҷеј иЎЁдёӯиҜ»еҸ–пјӣ
rangeпјҡеҸӘжЈҖзҙўз»ҷе®ҡиҢғеӣҙзҡ„иЎҢпјҢдҪҝз”ЁдёҖдёӘзҙўеј•жқҘйҖүжӢ©иЎҢгҖӮеҪ“дҪҝз”Ё=гҖҒ<>гҖҒ>гҖҒ>=гҖҒ<гҖҒ<=гҖҒIS NULLгҖҒ<=>гҖҒBETWEENжҲ–иҖ…INж“ҚдҪңз¬ҰпјҢз”ЁеёёйҮҸжҜ”иҫғе…ій”®еӯ—еҲ—ж—¶пјҢеҸҜд»ҘдҪҝз”Ёrangeпјӣ
indexпјҡиҜҘиҒ”жҺҘзұ»еһӢдёҺALLзӣёеҗҢпјҢйҷӨдәҶеҸӘжңүзҙўеј•ж ‘иў«жү«жҸҸгҖӮиҝҷйҖҡеёёжҜ”ALLеҝ«пјҢеӣ дёәзҙўеј•ж–Ү件йҖҡеёёжҜ”ж•°жҚ®ж–Ү件е°Ҹпјӣ
allпјҡе…ЁиЎЁжү«жҸҸпјӣ
е®һйҷ…sqlдјҳеҢ–дёӯпјҢжңҖеҗҺиҫҫеҲ°refжҲ–rangeзә§еҲ«гҖӮ
Using indexпјҡеҸӘд»Һзҙўеј•ж ‘дёӯиҺ·еҸ–дҝЎжҒҜпјҢиҖҢдёҚйңҖиҰҒеӣһиЎЁжҹҘиҜўпјӣ
Using whereпјҡWHEREеӯҗеҸҘз”ЁдәҺйҷҗеҲ¶е“ӘдёҖдёӘиЎҢеҢ№й…ҚдёӢдёҖдёӘиЎЁжҲ–еҸ‘йҖҒеҲ°е®ўжҲ·гҖӮйҷӨйқһдҪ дё“й—Ёд»ҺиЎЁдёӯзҙўеҸ–жҲ–жЈҖжҹҘжүҖжңүиЎҢпјҢеҰӮжһңExtraеҖјдёҚдёәUsing where并且表иҒ”жҺҘзұ»еһӢдёәALLжҲ–indexпјҢжҹҘиҜўеҸҜиғҪдјҡжңүдёҖдәӣй”ҷиҜҜгҖӮйңҖиҰҒеӣһиЎЁжҹҘиҜўгҖӮ
Using temporaryпјҡmysqlеёёе»әдёҖдёӘдёҙж—¶иЎЁжқҘе®№зәіз»“жһңпјҢе…ёеһӢжғ…еҶөеҰӮжҹҘиҜўеҢ…еҗ«еҸҜд»ҘжҢүдёҚеҗҢжғ…еҶөеҲ—еҮәеҲ—зҡ„GROUP BYе’ҢORDER BYеӯҗеҸҘж—¶пјӣ
зҙўеј•еҺҹзҗҶеҸҠexplainз”Ёжі•иҜ·еҸӮз…§еүҚдёҖзҜҮпјҡMySQLзҙўеј•еҺҹзҗҶпјҢexplainиҜҰи§Ј
дәҢгҖҒи§ҰеҸ‘зҙўеј•д»Јз Ғе®һдҫӢ
1гҖҒе»әиЎЁиҜӯеҸҘ + иҒ”еҗҲзҙўеј•
CREATE TABLE `student` (
`id` int(10) NOT NULL,
`name` varchar(20) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `student_union_index` (`name`,`age`,`sex`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2гҖҒдҪҝз”Ёдё»й”®жҹҘиҜў
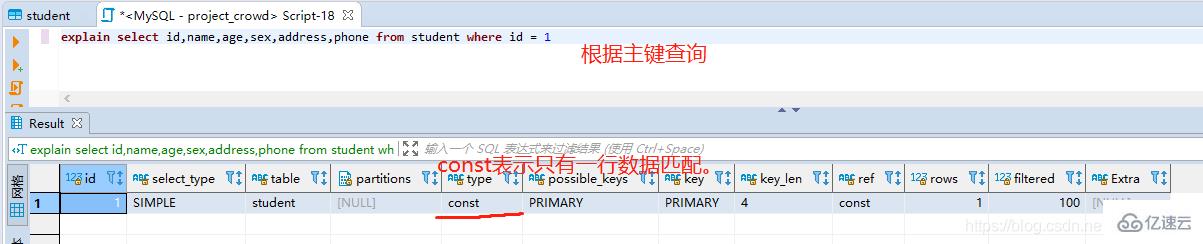
3гҖҒдҪҝз”ЁиҒ”еҗҲзҙўеј•жҹҘиҜў

4гҖҒиҒ”еҗҲзҙўеј•пјҢдҪҶдёҺзҙўеј•йЎәеәҸдёҚдёҖиҮҙ

еӨҮжіЁпјҡеӣ дёәmysqlдјҳеҢ–еҷЁзҡ„зјҳж•…пјҢдёҺзҙўеј•йЎәеәҸдёҚдёҖиҮҙпјҢд№ҹдјҡи§ҰеҸ‘зҙўеј•пјҢдҪҶе®һйҷ…йЎ№зӣ®дёӯе°ҪйҮҸйЎәеәҸдёҖиҮҙгҖӮ
5гҖҒиҒ”еҗҲзҙўеј•пјҢдҪҶе…¶дёӯдёҖдёӘжқЎд»¶жҳҜ >

6гҖҒиҒ”еҗҲзҙўеј•пјҢorder by

whereе’Ңorder byдёҖиө·дҪҝз”Ёж—¶пјҢдёҚиҰҒи·Ёзҙўеј•еҲ—дҪҝз”ЁгҖӮ
дёүгҖҒеҚ•иЎЁsqlдјҳеҢ–
1гҖҒеҲ йҷӨstudentиЎЁдёӯзҡ„иҒ”еҗҲзҙўеј•гҖӮ

2гҖҒж·»еҠ зҙўеј•
alter table student add index student_union_index(name,age,sex);

дјҳеҢ–дёҖзӮ№пјҢдҪҶж•ҲжһңдёҚжҳҜеҫҲеҘҪпјҢеӣ дёәtypeжҳҜindexзұ»еһӢпјҢextraдёӯдҫқ然еӯҳеңЁusing whereгҖӮ
3гҖҒжӣҙж”№зҙўеј•йЎәеәҸ
еӣ дёәsqlзҡ„зј–еҶҷиҝҮзЁӢ
select distinct ... from ... join ... on ... where ... group by ... having ... order by ... limit ...
и§ЈжһҗиҝҮзЁӢ
from ... on ... join ... where ... group by ... having ... select distinct ... order by ... limit ...
еӣ жӯӨжҲ‘жҖҖз–‘жҳҜиҒ”еҗҲзҙўеј•е»әзҡ„йЎәеәҸй—®йўҳпјҢеҜјиҮҙи§ҰеҸ‘зҙўеј•зҡ„ж•ҲжһңдёҚеҘҪгҖӮare you sureпјҹиҜ•дёҖдёӢе°ұзҹҘйҒ“дәҶгҖӮ
alter table student add index student_union_index2(age,sex,name);
еҲ йҷӨж—§зҡ„дёҚз”Ёзҡ„зҙўеј•пјҡ
drop index student_union_index on student
зҙўеј•ж”№еҗҚ
ALTER TABLE student RENAME INDEX student_union_index2 TO student_union_index
жӣҙж”№зҙўеј•йЎәеәҸд№ӢеҗҺпјҢеҸ‘зҺ°typeзә§еҲ«еҸ‘з”ҹдәҶеҸҳеҢ–пјҢз”ұindexеҸҳдёәдәҶrangeгҖӮ
rangeпјҡеҸӘжЈҖзҙўз»ҷе®ҡиҢғеӣҙзҡ„иЎҢпјҢдҪҝз”ЁдёҖдёӘзҙўеј•жқҘйҖүжӢ©иЎҢгҖӮ

еӨҮжіЁпјҡinдјҡеҜјиҮҙзҙўеј•еӨұж•ҲпјҢжүҖд»Ҙи§ҰеҸ‘using whereпјҢиҝӣиҖҢеҜјиҮҙеӣһиЎЁжҹҘиҜўгҖӮ
4гҖҒеҺ»жҺүin

refпјҡеҜ№дәҺжҜҸдёӘжқҘиҮӘдәҺеүҚйқўзҡ„иЎЁзҡ„иЎҢз»„еҗҲпјҢжүҖжңүжңүеҢ№й…Қзҙўеј•еҖјзҡ„иЎҢе°Ҷд»Һиҝҷеј иЎЁдёӯиҜ»еҸ–пјӣ
index жҸҗеҚҮдёәrefдәҶпјҢдјҳеҢ–еҲ°жӯӨз»“жқҹгҖӮ
5гҖҒе°Ҹз»“
дҝқжҢҒзҙўеј•зҡ„е®ҡд№үе’ҢдҪҝз”ЁйЎәеәҸдёҖиҮҙжҖ§пјӣ
зҙўеј•йңҖиҰҒйҖҗжӯҘдјҳеҢ–пјҢдёҚиҰҒжҖ»жғізқҖдёҖеҸЈеҗғжҲҗиғ–еӯҗпјӣ
е°Ҷеҗ«inзҡ„иҢғеӣҙжҹҘиҜўпјҢж”ҫеҲ°whereжқЎд»¶зҡ„жңҖеҗҺпјҢйҳІжӯўзҙўеј•еӨұж•Ҳпјӣ
еӣӣгҖҒеҸҢиЎЁsqlдјҳеҢ–
1гҖҒе»әиЎЁиҜӯеҸҘ
CREATE TABLE `student` (
`id` int(10) NOT NULL,
`name` varchar(20) NOT NULL,
`age` int(10) NOT NULL,
`sex` int(11) DEFAULT NULL,
`address` varchar(100) DEFAULT NULL,
`phone` varchar(100) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
`update_time` timestamp NULL DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teacher` (
`id` int(11) DEFAULT NULL,
`name` varchar(100) DEFAULT NULL,
`course` varchar(100) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2гҖҒе·ҰиҝһжҺҘжҹҘиҜў
explain select s.name,t.name from student s left join teacher t on s.teacher_id = t.id where t.course = 'ж•°еӯҰ'

дёҠдёҖзҜҮд»Ӣз»ҚиҝҮпјҢиҒ”еҗҲжҹҘиҜўж—¶пјҢе°ҸиЎЁй©ұеҠЁеӨ§иЎЁгҖӮе°ҸиЎЁд№ҹз§°дёәй©ұеҠЁиЎЁгҖӮе…¶е®һе°ұзӣёеҪ“дәҺеҸҢйҮҚforеҫӘзҺҜпјҢе°ҸиЎЁе°ұжҳҜеӨ–еҫӘзҺҜпјҢ第дәҢеј иЎЁпјҲеӨ§иЎЁпјүе°ұжҳҜеҶ…еҫӘзҺҜгҖӮ
иҷҪ然жңҖз»Ҳзҡ„еҫӘзҺҜз»“жһңйғҪжҳҜдёҖж ·зҡ„пјҢйғҪжҳҜеҫӘзҺҜдёҖж ·зҡ„ж¬Ўж•°пјҢдҪҶжҳҜеҜ№дәҺеҸҢйҮҚеҫӘзҺҜжқҘиҜҙпјҢдёҖиҲ¬е»әи®®е°Ҷж•°жҚ®йҮҸе°Ҹзҡ„еҫӘзҺҜж”ҫеӨ–еұӮпјҢж•°жҚ®йҮҸеӨ§зҡ„ж”ҫеҶ…еұӮпјҢиҝҷжҳҜзј–зЁӢиҜӯиЁҖзҡ„дјҳеҢ–еҺҹеҲҷгҖӮ
еҶҚж¬Ўд»Јз ҒжөӢиҜ•пјҡ
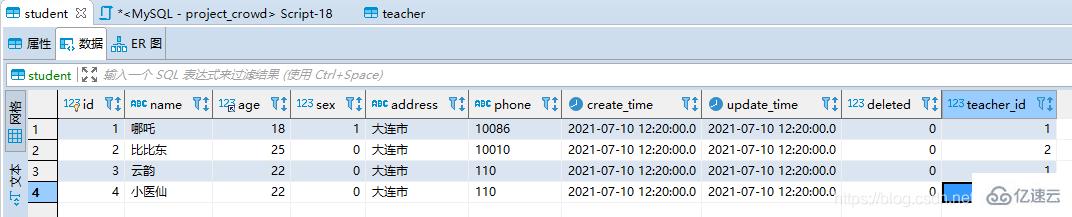
studentж•°жҚ®пјҡеӣӣжқЎ
teacherж•°жҚ®пјҡдёүжқЎ
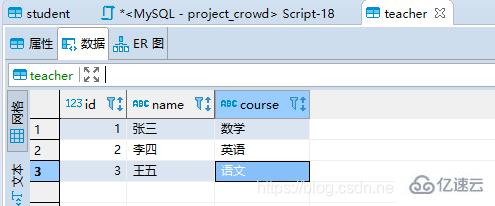
жҢүз…§зҗҶи®әеҲҶжһҗпјҢteacherеә”иҜҘдёәй©ұеҠЁиЎЁгҖӮ

sqlиҜӯеҸҘеә”иҜҘж”№дёәпјҡ
explain select teacher.name,student.name from teacher left join student on teacher.id = student.id where teacher.course = 'ж•°еӯҰ'
дјҳеҢ–дёҖиҲ¬жҳҜйңҖиҰҒзҙўеј•зҡ„пјҢйӮЈд№ҲжӯӨж—¶пјҢзҙўеј•еә”иҜҘжҖҺд№ҲеҠ е‘ўпјҹеҫҖе“ӘдёӘиЎЁдёҠеҠ зҙўеј•пјҹ
зҙўеј•зҡ„еҹәжң¬зҗҶеҝөжҳҜпјҡзҙўеј•иҰҒе»әеңЁз»ҸеёёдҪҝз”Ёзҡ„еӯ—ж®өдёҠгҖӮ
з”ұon teacher.id = student.idеҸҜзҹҘпјҢteacherиЎЁзҡ„idеӯ—ж®өдҪҝз”Ёиҫғдёәйў‘з№ҒгҖӮ
left join onпјҢдёҖиҲ¬з»ҷе·ҰиЎЁеҠ зҙўеј•пјӣеӣ дёәжҳҜй©ұеҠЁиЎЁеҳӣгҖӮ

alter table teacher add index teacher_index(id);
alter table teacher add index teacher_course(course);

еӨҮжіЁпјҡеҰӮжһңextraдёӯеҮәзҺ°using join bufferпјҢиЎЁжҳҺmysqlеә•еұӮи§үеҫ—sqlеҶҷзҡ„еӨӘе·®дәҶпјҢmysqlеҠ дәҶдёӘзј“еӯҳпјҢиҝӣиЎҢдјҳеҢ–дәҶгҖӮ
3гҖҒе°Ҹз»“
е°ҸиЎЁй©ұеҠЁеӨ§иЎЁ
зҙўеј•е»әз«ӢеңЁз»ҸеёёжҹҘиҜўзҡ„еӯ—ж®өдёҠ
sqlдјҳеҢ–пјҢжҳҜдёҖз§ҚжҰӮзҺҮеұӮйқўзҡ„дјҳеҢ–пјҢжҳҜеҗҰе®һйҷ…дҪҝз”ЁдәҶжҲ‘们зҡ„дјҳеҢ–пјҢйңҖиҰҒйҖҡиҝҮexplainжҺЁжөӢгҖӮ
дә”гҖҒйҒҝе…Қзҙўеј•еӨұж•Ҳзҡ„дёҖдәӣеҺҹеҲҷ
1гҖҒеӨҚеҗҲзҙўеј•пјҢдёҚиҰҒи·ЁеҲ—жҲ–ж— еәҸдҪҝз”ЁпјҲжңҖдҪіе·ҰеүҚзјҖпјүпјӣ
2гҖҒз¬ҰеҗҲзҙўеј•пјҢе°ҪйҮҸдҪҝз”Ёе…Ёзҙўеј•еҢ№й…Қпјӣ
3гҖҒдёҚиҰҒеңЁзҙўеј•дёҠиҝӣиЎҢд»»дҪ•ж“ҚдҪңпјҢдҫӢеҰӮеҜ№зҙўеј•иҝӣиЎҢпјҲи®Ўз®—гҖҒеҮҪж•°гҖҒзұ»еһӢиҪ¬жҚўпјүпјҢзҙўеј•еӨұж•Ҳпјӣ
4гҖҒеӨҚеҗҲзҙўеј•дёҚиғҪдҪҝз”ЁдёҚзӯүдәҺпјҲ!=жҲ–<>пјүжҲ– is nullпјҲis not nullпјүпјҢеҗҰеҲҷзҙўеј•еӨұж•Ҳпјӣ
5гҖҒе°ҪйҮҸдҪҝз”ЁиҰҶзӣ–зҙўеј•пјҲusing indexпјүпјӣ
6гҖҒlikeе°ҪйҮҸд»ҘеёёйҮҸејҖеӨҙпјҢдёҚиҰҒд»Ҙ%ејҖеӨҙпјҢеҗҰеҲҷзҙўеј•еӨұж•ҲпјӣеҰӮжһңеҝ…йЎ»дҪҝз”Ё%name%иҝӣиЎҢжҹҘиҜўпјҢеҸҜд»ҘдҪҝз”ЁиҰҶзӣ–зҙўеј•жҢҪж•‘пјҢдёҚз”ЁеӣһиЎЁжҹҘиҜўж—¶еҸҜд»Ҙи§ҰеҸ‘зҙўеј•пјӣ
7гҖҒе°ҪйҮҸдёҚиҰҒдҪҝз”Ёзұ»еһӢиҪ¬жҚўпјҢеҗҰеҲҷзҙўеј•еӨұж•Ҳпјӣ
8гҖҒе°ҪйҮҸдёҚиҰҒдҪҝз”ЁorпјҢеҗҰеҲҷзҙўеј•еӨұж•Ҳпјӣ
е…ӯгҖҒдёҖдәӣе…¶д»–зҡ„дјҳеҢ–ж–№жі•
1гҖҒexistе’Ңin
select name,age from student exist/in (еӯҗжҹҘиҜў);
еҰӮжһңдё»жҹҘиҜўзҡ„ж•°жҚ®йӣҶеӨ§пјҢеҲҷдҪҝз”Ёinпјӣ
еҰӮжһңеӯҗжҹҘиҜўзҡ„ж•°жҚ®йӣҶеӨ§пјҢеҲҷдҪҝз”Ёexistпјӣ
2гҖҒorder by дјҳеҢ–
using filesortжңүдёӨз§Қз®—жі•пјҡеҸҢи·ҜжҺ’еәҸгҖҒеҸҢи·ҜжҺ’еәҸпјҲж №жҚ®IOзҡ„ж¬Ўж•°пјү
MySQL4.1д№ӢеүҚпјҢй»ҳи®ӨдҪҝз”ЁеҸҢи·ҜжҺ’еәҸпјӣеҸҢи·Ҝпјҡжү«жҸҸдёӨж¬ЎзЈҒзӣҳпјҲв‘ д»ҺзЈҒзӣҳиҜ»еҸ–жҺ’еәҸеӯ—ж®өпјҢеҜ№жҺ’еәҸеӯ—ж®өиҝӣиЎҢжҺ’еәҸпјӣв‘ЎиҺ·еҸ–е…¶е®ғеӯ—ж®өпјүгҖӮ
MySQL4.1д№ӢеҗҺпјҢй»ҳи®ӨдҪҝз”ЁеҚ•и·ҜжҺ’еәҸпјӣеҚ•и·ҜпјҡеҸӘиҜ»еҸ–дёҖж¬ЎпјҲе…ЁйғЁеӯ—ж®өпјүпјҢеңЁbufferдёӯиҝӣиЎҢжҺ’еәҸгҖӮдҪҶеҚ•и·ҜжҺ’еәҸдјҡжңүдёҖе®ҡзҡ„йҡҗжӮЈпјҲдёҚдёҖе®ҡзңҹзҡ„жҳҜеҸӘжңүдёҖж¬ЎIOпјҢжңүеҸҜиғҪеӨҡж¬ЎIOпјүгҖӮ
жіЁж„ҸпјҡеҚ•и·ҜжҺ’еәҸдјҡжҜ”еҸҢи·ҜжҺ’еәҸеҚ з”ЁжӣҙеӨҡзҡ„bufferгҖӮ
еҚ•и·ҜжҺ’еәҸж—¶пјҢеҰӮжһңж•°жҚ®йҮҸиҫғеӨ§пјҢеҸҜд»Ҙи°ғеӨ§bufferзҡ„е®№йҮҸеӨ§е°ҸгҖӮ
set max_length_for_sort_data = 1024;еҚ•дҪҚжҳҜеӯ—иҠӮbyteгҖӮ
еҰӮжһңmax_length_for_sort_dataеҖјеӨӘдҪҺпјҢMySQLеә•еұӮдјҡиҮӘеҠЁе°ҶеҚ•и·ҜеҲҮжҚўеҲ°еҸҢи·ҜгҖӮ
еӨӘдҪҺжҢҮзҡ„жҳҜеҲ—зҡ„жҖ»еӨ§е°Ҹи¶…иҝҮдәҶmax_length_for_sort_dataе®ҡд№үзҡ„еӯ—иҠӮж•°гҖӮ
жҸҗй«ҳorder byжҹҘиҜўзҡ„зӯ–з•Ҙпјҡ
йҖүжӢ©дҪҝз”ЁеҚ•и·ҜжҲ–еҸҢи·ҜпјҢи°ғж•ҙbufferзҡ„е®№йҮҸеӨ§е°Ҹпјӣ
йҒҝе…Қselect * from student;пјҲв‘ MySQLеә•еұӮйңҖиҰҒеҜ№*иҝӣиЎҢзҝ»иҜ‘пјҢж¶ҲиҖ—жҖ§иғҪпјӣв‘Ў *ж°ёиҝңдёҚдјҡи§ҰеҸ‘зҙўеј•иҰҶзӣ– using indexпјүпјӣ
з¬ҰеҗҲзҙўеј•дёҚиҰҒи·ЁеҲ—дҪҝз”ЁпјҢйҒҝе…Қusing filesortпјӣ
дҝқиҜҒе…ЁйғЁзҡ„жҺ’еәҸеӯ—ж®өпјҢжҺ’еәҸзҡ„дёҖиҮҙжҖ§пјҲйғҪжҳҜеҚҮеәҸжҲ–йҷҚеәҸпјүпјӣ
дёғгҖҒsqlйЎәеәҸ -> ж…ўж—Ҙеҝ—жҹҘиҜў
ж…ўжҹҘиҜўж—Ҙеҝ—е°ұжҳҜMySQLжҸҗдҫӣзҡ„дёҖз§Қж—Ҙеҝ—и®°еҪ•пјҢз”ЁдәҺи®°еҪ•MySQLе“Қеә”ж—¶й—ҙи¶…иҝҮйҳҲеҖјзҡ„SQLиҜӯеҸҘпјҲlong_query_timeпјҢй»ҳи®Ө10з§’пјү пјӣ
ж…ўж—Ҙеҝ—й»ҳи®ӨжҳҜе…ій—ӯзҡ„пјҢејҖеҸ‘и°ғдјҳж—¶жү“ејҖпјҢжңҖз»ҲйғЁзҪІж—¶е…ій—ӯгҖӮ
1гҖҒж…ўжҹҘиҜўж—Ҙеҝ—
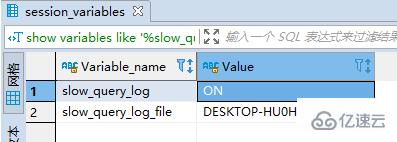
пјҲ1пјүжЈҖжҹҘжҳҜеҗҰејҖеҗҜдәҶж…ўжҹҘиҜўж—Ҙеҝ—пјҡ
show variables like '%slow_query_log%'
пјҲ2пјүдёҙж—¶ејҖеҗҜпјҡ
set global slow_query_log = 1;
пјҲ3пјүйҮҚеҗҜMySQLпјҡ
service mysql restart;
пјҲ4пјүж°ёд№…ејҖеҗҜпјҡ
/etc/my.cnfдёӯиҝҪеҠ й…ҚзҪ®пјҡ
ж”ҫеҲ°[mysqld]дёӢпјҡ
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
2гҖҒйҳҲеҖј
пјҲ1пјүжҹҘзңӢй»ҳи®ӨйҳҲеҖјпјҡ
show variables like '%long_query_time%'
пјҲ2пјүдёҙж—¶дҝ®ж”№й»ҳи®ӨйҳҲеҖјпјҡ
set global long_query_time = 5;
пјҲ3пјүж°ёд№…дҝ®ж”№й»ҳи®ӨйҳҲеҖјпјҡ
/etc/my.cnfдёӯиҝҪеҠ й…ҚзҪ®пјҡ
ж”ҫеҲ°[mysqld]дёӢпјҡ
long_query_time = 5;
пјҲ4пјүMySQLдёӯзҡ„sleepпјҡ
select sleep(5);
пјҲ5пјүжҹҘзңӢжү§иЎҢж—¶й—ҙи¶…иҝҮйҳҲеҖјзҡ„sqlпјҡ
show global status like '%slow_queries%';
е…«гҖҒж…ўжҹҘиҜўж—Ҙеҝ— --> mysqldumpslowе·Ҙе…·
1гҖҒmysqldumpslowе·Ҙе…·
ж…ўжҹҘиҜўзҡ„sqlиў«и®°еҪ•еңЁж—Ҙеҝ—дёӯпјҢеҸҜд»ҘйҖҡиҝҮж—Ҙеҝ—жҹҘзңӢе…·дҪ“зҡ„ж…ўsqlгҖӮ
cat /var/lib/mysql/localhost-slow.log
йҖҡmysqldumpslowе·Ҙе…·жҹҘзңӢж…ўsqlпјҢеҸҜд»ҘйҖҡиҝҮдёҖдәӣиҝҮж»ӨжқЎд»¶пјҢеҝ«йҖҹжҹҘеҮәйңҖиҰҒе®ҡдҪҚзҡ„ж…ўsqlгҖӮ
mysqldumpslow --help
еҸӮж•°з®ҖиҰҒд»Ӣз»Қпјҡ
sпјҡжҺ’еәҸж–№ејҸ
rпјҡйҖҶеәҸ
lпјҡй”Ғе®ҡж—¶й—ҙ
gпјҡжӯЈеҲҷеҢ№й…ҚжЁЎејҸ
2гҖҒжҹҘиҜўдёҚеҗҢжқЎд»¶дёӢзҡ„ж…ўsql
пјҲ1пјүиҝ”еӣһи®°еҪ•жңҖеӨҡзҡ„3дёӘSQL
mysqldumpslow -s r -t 3 /var/lib/mysql/localhost-slow.log
пјҲ2пјүиҺ·еҸ–и®ҝй—®ж¬Ўж•°жңҖеӨҡзҡ„3дёӘSQL
mysqldumpslow -s c -t 3 /var/lib/mysql/localhost-slow.log
пјҲ3пјүжҢүж—¶й—ҙжҺ’еәҸпјҢеүҚ10жқЎеҢ…еҗ«left joinжҹҘиҜўиҜӯеҸҘзҡ„SQL
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/localhost-slow.log
д№қгҖҒеҲҶжһҗжө·йҮҸж•°жҚ®
1гҖҒshow profiles
жү“ејҖжӯӨеҠҹиғҪпјҡset profiling = on;
show profilesдјҡи®°еҪ•жүҖжңүprofileingжү“жқҘд№ӢеҗҺпјҢе…ЁйғЁSQLжҹҘиҜўиҜӯеҸҘжүҖиҠұиҙ№зҡ„ж—¶й—ҙгҖӮ
зјәзӮ№жҳҜдёҚеӨҹзІҫзЎ®пјҢзЎ®е®ҡдёҚдәҶжҳҜжү§иЎҢе“ӘйғЁеҲҶжүҖж¶ҲиҖ—зҡ„ж—¶й—ҙпјҢжҜ”еҰӮCPUгҖҒIOгҖӮ
2гҖҒзІҫзЎ®еҲҶжһҗпјҢsqlиҜҠж–ӯ
show profile all for query дёҠдёҖжӯҘжҹҘиҜўеҲ°зҡ„query_idгҖӮ
3гҖҒе…ЁеұҖжҹҘиҜўж—Ҙеҝ—
show variables like '%general_log%'
ејҖеҗҜе…ЁеұҖж—Ҙеҝ—пјҡ
set global general_log = 1;
set global log_output = table;
еҚҒгҖҒй”ҒжңәеҲ¶иҜҰи§Ј
1гҖҒж“ҚдҪңеҲҶзұ»
иҜ»еҶҷпјҡеҜ№еҗҢдёҖдёӘж•°жҚ®пјҢеӨҡдёӘиҜ»ж“ҚдҪңеҸҜд»ҘеҗҢж—¶иҝӣиЎҢпјҢдә’дёҚе№Іжү°гҖӮ
еҶҷй”ҒпјҡеҰӮжһңеҪ“еүҚеҶҷж“ҚдҪңжІЎжңүе®ҢжҜ•пјҢеҲҷж— жі•иҝӣиЎҢе…¶е®ғзҡ„иҜ»еҶҷж“ҚдҪңгҖӮ
2гҖҒж“ҚдҪңиҢғеӣҙ
иЎЁй”ҒпјҡдёҖж¬ЎжҖ§еҜ№дёҖеј иЎЁж•ҙдҪ“еҠ й”ҒгҖӮ
еҰӮMyISAMеӯҳеӮЁеј•ж“ҺдҪҝз”ЁиЎЁй”ҒпјҢејҖй”Җе°ҸгҖҒеҠ й”Ғеҝ«гҖҒж— жӯ»й”ҒпјӣдҪҶй”Ғзҡ„иҢғеӣҙеӨ§пјҢе®№жҳ“еҸ‘з”ҹеҶІзӘҒгҖҒ并еҸ‘еәҰдҪҺгҖӮ
иЎҢй”ҒпјҡдёҖж¬ЎжҖ§еҜ№дёҖжқЎж•°жҚ®еҠ й”ҒгҖӮ
еҰӮInnoDBеӯҳеӮЁеј•ж“ҺдҪҝз”Ёзҡ„е°ұжҳҜиЎҢй”ҒпјҢејҖй”ҖеӨ§гҖҒеҠ й”Ғж…ўгҖҒе®№жҳ“еҮәзҺ°жӯ»й”Ғпјӣй”Ғзҡ„иҢғеӣҙиҫғе°ҸпјҢдёҚжҳ“еҸ‘з”ҹй”ҒеҶІзӘҒпјҢ并еҸ‘еәҰй«ҳпјҲеҫҲе°ҸжҰӮзҺҮеҸ‘з”ҹй«ҳ并еҸ‘й—®йўҳпјҡи„ҸиҜ»гҖҒе№»иҜ»гҖҒдёҚеҸҜйҮҚеӨҚиҜ»пјү
lock table иЎЁ1 read/writeпјҢиЎЁ2 read/writeпјҢ...
жҹҘзңӢеҠ й”Ғзҡ„иЎЁпјҡ
show open tables;
3гҖҒеҠ иҜ»й”ҒпјҢд»Јз Ғе®һдҫӢ
дјҡиҜқ0пјҡ
lock table student read;
select * from student; --жҹҘпјҢеҸҜд»Ҙ
delete from student where id = 1;--еўһеҲ ж”№пјҢдёҚеҸҜд»Ҙ
select * from user; --жҹҘпјҢдёҚеҸҜд»Ҙ
delete from user where id = 1;--еўһеҲ ж”№пјҢдёҚеҸҜд»Ҙ
еҰӮжһңжҹҗдёҖдёӘдјҡиҜқеҜ№AиЎЁеҠ дәҶreadй”ҒпјҢеҲҷиҜҘдјҡиҜқеҸҜд»ҘеҜ№AиЎЁиҝӣиЎҢиҜ»ж“ҚдҪңгҖҒдёҚиғҪиҝӣиЎҢеҶҷж“ҚдҪңгҖӮеҚіеҰӮжһңз»ҷAиЎЁеҠ дәҶиҜ»й”ҒпјҢеҲҷеҪ“еүҚдјҡиҜқеҸӘиғҪеҜ№AиЎЁиҝӣиЎҢиҜ»ж“ҚдҪңпјҢе…¶е®ғиЎЁйғҪдёҚиғҪж“ҚдҪң
дјҡиҜқ1пјҡ
select * from student; --жҹҘпјҢеҸҜд»Ҙ
delete from student where id = 1;--еўһеҲ ж”№пјҢдјҡвҖңзӯүеҫ…вҖқдјҡиҜқ0е°Ҷй”ҒйҮҠж”ҫ
дјҡиҜқ1пјҡ
select * from user; --жҹҘпјҢеҸҜд»Ҙ
delete from user where id = 1;--еўһеҲ ж”№пјҢеҸҜд»Ҙ
дјҡиҜқ0з»ҷAиЎЁеҠ дәҶй”ҒпјҢе…¶е®ғдјҡиҜқзҡ„ж“ҚдҪңв‘ еҸҜд»ҘеҜ№е…¶е®ғиЎЁиҝӣиЎҢиҜ»еҶҷж“ҚдҪңв‘ЎеҜ№AиЎЁпјҡиҜ»еҸҜд»ҘпјҢеҶҷйңҖиҰҒзӯүеҫ…йҮҠж”ҫй”ҒгҖӮ
4гҖҒеҠ еҶҷй”Ғ
дјҡиҜқ0пјҡ
lock table student write;
еҪ“еүҚдјҡиҜқеҸҜд»ҘеҜ№еҠ дәҶеҶҷй”Ғзҡ„иЎЁпјҢеҸҜд»ҘиҝӣиЎҢд»»дҪ•еўһеҲ ж”№жҹҘж“ҚдҪңпјӣдҪҶжҳҜдёҚиғҪж“ҚдҪңе…¶е®ғиЎЁпјӣ
е…¶е®ғдјҡиҜқпјҡ
еҜ№дјҡиҜқ0дёӯеҜ№еҠ еҶҷй”Ғзҡ„иЎЁпјҢеҸҜд»ҘиҝӣиЎҢеўһеҲ ж”№жҹҘзҡ„еүҚжҸҗжҳҜпјҡзӯүеҫ…дјҡиҜқ0йҮҠж”ҫеҶҷй”ҒгҖӮ
5гҖҒMyISAMиЎЁзә§й”Ғзҡ„й”ҒжЁЎејҸ
MyISAMеңЁжү§иЎҢжҹҘиҜўиҜӯеҸҘеүҚпјҢдјҡиҮӘеҠЁз»ҷж¶үеҸҠзҡ„жүҖжңүиЎЁеҠ иҜ»й”ҒпјҢеңЁжү§иЎҢеўһеҲ ж”№еүҚпјҢдјҡиҮӘеҠЁз»ҷж¶үеҸҠзҡ„иЎЁеҠ еҶҷй”ҒгҖӮ
жүҖд»ҘеҜ№MyISAMиЎЁиҝӣиЎҢж“ҚдҪңпјҢдјҡжңүеҰӮдёӢжғ…еҶөеҸ‘з”ҹпјҡ
пјҲ1пјүеҜ№MyISAMиЎЁзҡ„иҜ»ж“ҚдҪңпјҲеҠ иҜ»й”ҒпјүпјҢдёҚдјҡйҳ»еЎһе…¶е®ғдјҡиҜқпјҲиҝӣзЁӢпјүеҜ№еҗҢдёҖиЎЁзҡ„иҜ»иҜ·жұӮгҖӮдҪҶдјҡйҳ»еЎһеҜ№еҗҢдёҖиЎЁзҡ„еҶҷж“ҚдҪңгҖӮеҸӘжңүеҪ“иҜ»й”ҒйҮҠж”ҫеҗҺпјҢжүҚдјҡжү§иЎҢе…¶е®ғиҝӣзЁӢзҡ„еҶҷж“ҚдҪңгҖӮ
пјҲ2пјүеҜ№MyISAMиЎЁзҡ„еҶҷж“ҚдҪңпјҲеҠ еҶҷй”ҒпјүпјҢдјҡйҳ»еЎһе…¶е®ғдјҡиҜқпјҲиҝӣзЁӢпјүеҜ№еҗҢдёҖиЎЁзҡ„иҜ»е’ҢеҶҷж“ҚдҪңпјҢеҸӘжңүеҪ“еҶҷй”ҒйҮҠж”ҫеҗҺпјҢжүҚдјҡжү§иЎҢе…¶е®ғиҝӣзЁӢзҡ„иҜ»еҶҷж“ҚдҪңгҖӮ
6гҖҒMyISAMеҲҶжһҗиЎЁй”Ғе®ҡ
жҹҘзңӢе“ӘдәӣиЎЁеҠ дәҶй”Ғпјҡ
show open tables;1д»ЈиЎЁиў«еҠ дәҶй”Ғ
еҲҶжһҗиЎЁй”Ғе®ҡзҡ„дёҘйҮҚзЁӢеәҰпјҡ
show status like 'table%';

Table_locks_immediateпјҡеҸҜиғҪиҺ·еҸ–еҲ°зҡ„й”Ғж•°
Table_locks_waitedпјҡйңҖиҰҒзӯүеҫ…зҡ„иЎЁй”Ғж•°пјҲиҜҘеҖји¶ҠеӨ§пјҢиҜҙжҳҺеӯҳеңЁи¶ҠеӨ§зҡ„й”Ғз«һдәүпјү
дёҖиҲ¬е»әи®®пјҡTable_locks_immediate/Table_locks_waited > 5000пјҢе»әи®®йҮҮз”ЁInnoDBеј•ж“ҺпјҢеҗҰеҲҷйҮҮз”ЁMyISAMеј•ж“ҺгҖӮ
7гҖҒInnoDBеҲҶжһҗиЎЁй”Ғе®ҡ
дёәдәҶз ”з©¶иЎҢй”ҒпјҢжҡӮж—¶е°ҶиҮӘеҠЁcommitе…ій—ӯпјҢset autocommit = 0;
show status like '%innodb_row_lock%';
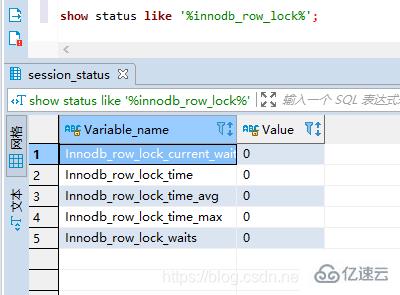
Innodb_row_lock_current_waitsпјҡеҪ“еүҚжӯЈеңЁзӯүеҫ…й”Ғзҡ„ж•°йҮҸ
Innodb_row_lock_timeпјҡзӯүеҫ…жҖ»ж—¶й•ҝгҖӮд»Һзі»з»ҹеҗҜеҠЁеҲ°зҺ°еңЁдёҖе…ұзӯүеҫ…зҡ„ж—¶й—ҙ
Innodb_row_lock_time_avgпјҡе№іеқҮзӯүеҫ…ж—¶й•ҝгҖӮд»Һзі»з»ҹеҗҜеҠЁеҲ°зҺ°еңЁдёҖе…ұзӯүеҫ…зҡ„ж—¶й—ҙ
Innodb_row_lock_time_maxпјҡжңҖеӨ§зӯүеҫ…ж—¶й•ҝгҖӮд»Һзі»з»ҹеҗҜеҠЁеҲ°зҺ°еңЁдёҖе…ұзӯүеҫ…зҡ„ж—¶й—ҙ
Innodb_row_lock_waitsпјҡзӯүеҫ…ж¬Ўж•°гҖӮд»Һзі»з»ҹеҗҜеҠЁеҲ°зҺ°еңЁдёҖе…ұзӯүеҫ…зҡ„ж—¶й—ҙ
8гҖҒеҠ иЎҢй”Ғд»Јз Ғе®һдҫӢ
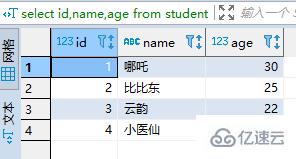
пјҲ1пјүжҹҘиҜўstudent
select id,name,age from student
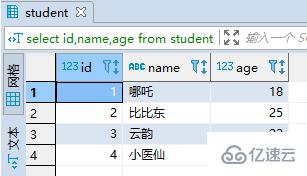
пјҲ2пјүжӣҙж–°student
update student set age = 18 where id = 1
пјҲ3пјүеҠ иЎҢй”Ғ
йҖҡиҝҮselect id,name,age from student for update;з»ҷжҹҘиҜўеҠ иЎҢй”ҒгҖӮ
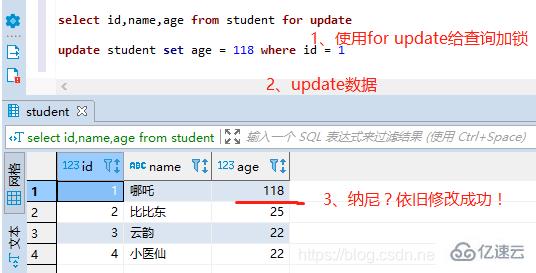
дҫқж—§дҝ®ж”№жҲҗеҠҹпјҢеҺҹеӣ жҳҜMySQLй»ҳи®ӨжҳҜиҮӘеҠЁжҸҗдәӨзҡ„пјҢеӣ жӯӨйңҖиҰҒжҡӮж—¶е°ҶиҮӘеҠЁcommitе…ій—ӯ
set autocommit = 0;
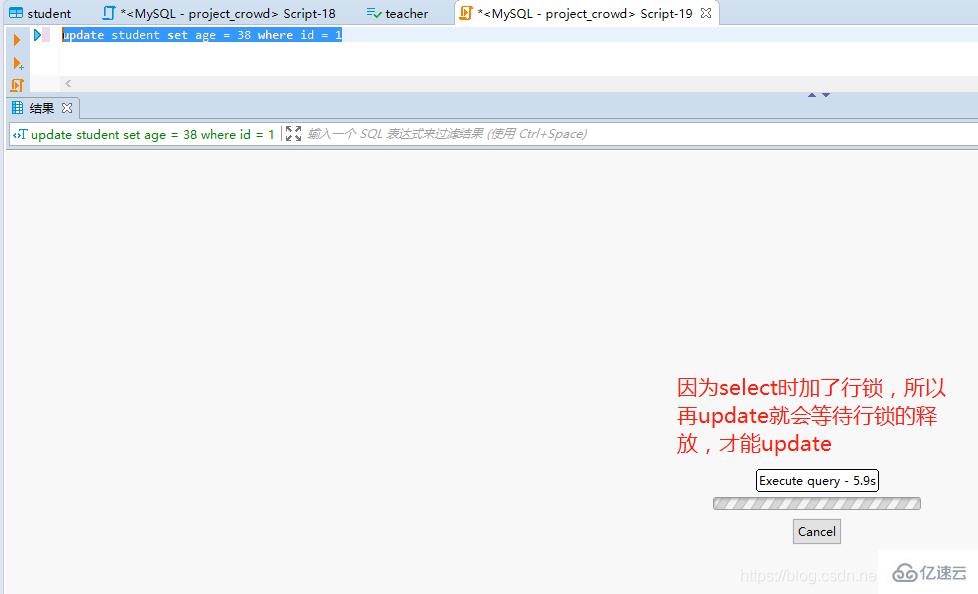
9гҖҒиЎҢй”Ғзҡ„жіЁж„ҸдәӢйЎ№
пјҲ1пјүеҰӮжһңжІЎжңүзҙўеј•пјҢиЎҢй”ҒиҮӘеҠЁиҪ¬дёәиЎЁй”ҒгҖӮ
пјҲ2пјүиЎҢй”ҒеҸӘиғҪйҖҡиҝҮдәӢеҠЎи§Јй”ҒгҖӮ
пјҲ3пјүInnoDBй»ҳи®ӨйҮҮз”ЁиЎҢй”Ғ
дјҳзӮ№пјҡ并еҸ‘иғҪеҠӣејәпјҢжҖ§иғҪй«ҳпјҢж•ҲзҺҮй«ҳ
зјәзӮ№пјҡжҜ”иЎЁй”ҒжҖ§иғҪжҚҹиҖ—еӨ§
й«ҳ并еҸ‘з”ЁInnoDbпјҢеҗҰеҲҷз”ЁMyISAMгҖӮ
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңMySqlдёӯsqlжҖҺд№ҲдјҳеҢ–вҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !





