下面讲讲关于图数据库Neo4j应用在在GIS系统的优势,文字的奥妙在于贴近主题相关。所以,闲话就不谈了,我们直接看下文吧,相信看完图数据库Neo4j应用在在GIS系统的优势这篇文章你一定会有所受益。
图数据库(Graph Database)是基于图论实现的一种新型的NoSQL数据库。他的数据存储结构和数据的查询方式都是以图论为基础的,图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。
在图数据库中,数据与数据之间的关系通过节点和关系构成一个图结构并且在此结构上实现数据库的所有特性,如对图数据对象进行创建、读取、更新、删除(Create、Read、Update、Delete,简称CRUD)等操作的能力,还有处理事务的能力和高可用性等。
从系统科学的视角来看,世界是由各种系统构成的,而系统由由系统的各个组成部分机器之间的联系组成。从这个层面,便能直接的将系统及其之间的联系映射为数学图论中的结点与关系上来,从而运用图论对世界进行直观建模,图数据库技术以图论为根,也可以说是表达多姿多彩世界的基础性、通用性“语言”。这种“语言”描述出来的仿真系统与原系统相比具有“高保真”得特性,与人们通常对系统的认知是一致的,并且非常直观、自然、直接和高效,不需要中间过程的转化和处理--这种中间过程的转换和处理往往把问题复杂化或者漏掉很多有价值的信息。正是由于图数据库技术可以直接描述各种复杂的现实世界系统,才使其具有广泛的适用性和更高的应用价值。
事实上,Neo4j已经成功“俘获”大量客户,并且客户数量和应用领域还在不断增长之中。这些客户包括思科、惠普、沃尔曼、领英、阿迪达斯、和FT金融时报等国际知名企业或机构。Neo4j客户的行业分类目前主要集中在社交网络、人力资源与招聘、金融、保险、零售、广告、电子商务、物流、交通、IT、电信、制造业、打印、文化传媒和医疗等领域。上述大量的Neo4j客户在未采用图数据库产品之前反复抱怨原有产品的不足,有待新产品去解决和实现,通称为:痛点,下表中列出客户和主要的痛点:
序号 | 企业名称 | 痛点分析或挑战 |
1 | MigRaven | 授权和访问控制 |
2 | Adidas | 提供个性化体验所需的数据分布在各种信息孤岛上 |
3 | BILLES | 增加在线客户:必须能够处理大量的小打印订单、大量的收购导致了IT系统的拼凑 |
4 | Cerved | 提高计算效率和快速识别,直接或间及控制公司的人员:获取大数据网络分析的顶尖技术 |
5 | Die Bayerische | 过时的管理系统和不同的数据格式:创建标准化数据框架 |
6 | ICIJ | 帮助记者打破复杂的瑞士楼栋数据,以获得更好的调查性新闻 |
7 | IRCC | 关系数据库没有为多虚的多个功能提供足够的灵活性 |
8 | LinkedIn China | 尽可能快的启动社交网络平台,同时为重要的用户和功能增长留出空间 |
9 | Musimap | 要映射所有音乐标题,每个具有55个加权描述标准,以允许深入处理和实时推荐 |
10 | Qualia | 原始产品仅被优化以跟踪一个设备上的用户行为 |
11 | SchleichGmbH | 在产品数据网络中需要更大的可扩展性和灵活性 |
12 | TRANSPARENCY-ONE | 管理和所搜大量数据,没有性能问题 |
13 | Wanderu | 帮助消费者在美国的旅行找到和预定城市间公共汽车和火车 |
14 | WineDataSystem | 没有现有的参考资源,大量的信息和问题,关于访问的方便性和用户的灵活性 |
15 | Wobi | 快速分析大量的整个客户信息 |
16 | eBay | 支持大规模的复杂路由查询,具有快速和一致的性能 |
17 | Global500 Logisitics | 时时刻刻都产生地理位置路由信息,业务需要这些具有复杂关联关系的位置信息来支持,这导致差传统关系型数据库面临严重挑战 |
18 | Glowbl | 讲多有可能的设计啊网络汇集到一起,以图的形式表现所有的联系人,并实时管理这些联系人及其互动关系 |
19 | InfoJobs | 建立新的门户,模拟求职者的潜在职业道路 |
20 | Megree | 提供这些链接的关系和强度的整体视图 |
21 | Pitney bowes | 通过构建下一代工具,获得360度的客户洞察力,获得竞争优势 |
22 | Walmart | 为客户提供最佳的网络购物体验 |
23 | Telenor | 在线自助服务管理门户的背后,您可以找到负责管理客户组织结构的协议 |
Neo4j最初的设计动机是为了更好的描述实体之间的联系。在现实生活中,每个实体都与周围的其他实体有着千丝万缕的关系,这些关系里存在着大量的潜在信息。但是传统的关系型数据库更加注重刻画实体内部的属性,实体与实体之间的关系主要通过外键来实现。因此在查询一个实体的关系时需要join操作,特别是深层次的关系查询需要大量的join操作,而join操作通常又非常耗时。随着现实世界中关系数据的急剧增加,导致关系型数据库已经逐渐的难以承载查询海量数据深层次关系需要大量数据库表操作带来的运算复杂性,Neo4j在这样的情况下应运而生。
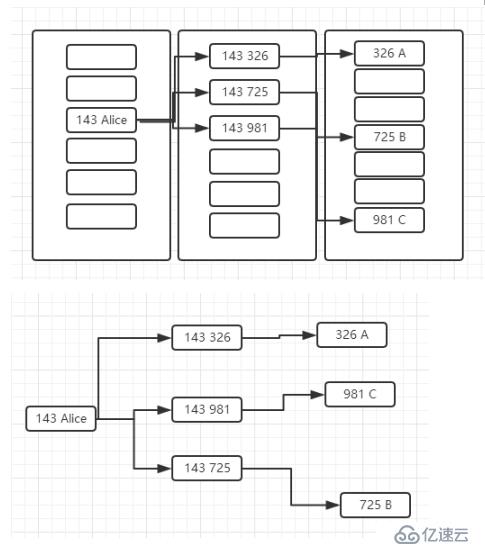
Neo4j有一个重要的特点,就是用来保证关系查询的速度,即免索引邻接属性,数据库中的每个节点都会维护与它相邻节点的引用。因此每个节点都相当于与他相邻节点的微索引,这比使用全局索引的代价要小得多。这意味着查询时间和图的整体规模无关,只与他附近节点的数量成正比。在关系型数据库中使用全局索引连接每个节点,这些索引对每个遍历都会增加一个中间层,因此会导致非常大的计算成本。而免索引连接为图数据库提供了快速高效的图遍历能力。下图展示了关系型数据库和Neo4j在查找关系时的区别:
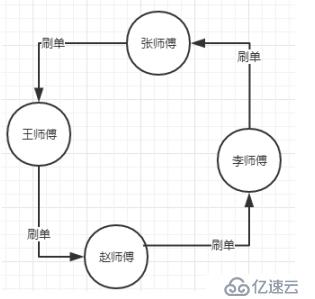
1、一组两个或两个以上的人组成一个刷单环路
2、监控一个打车订单的整个生命周期
当前我们一个订单的数据涉及到多个表,随着业务发展,订单数据量越来越多的时候,数据库面临的连接操作越来越多:
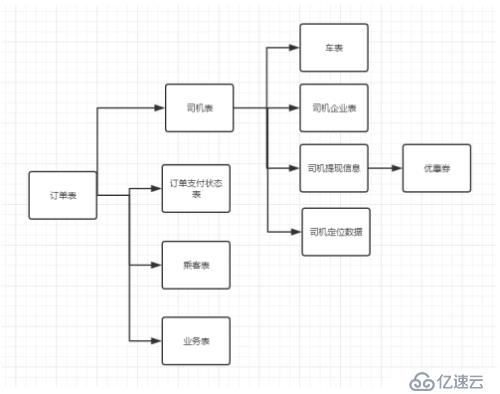
在数据决策系统中最长的SQL达到400行,连接了七个表,使用Neo4j的赛博语言可以大大减少查询的复杂度。
1、路网系统搭建
可以将获取的点和路径经纬度数据导入到Neo4j,通过其内置的最短路径函数查询最短的导航路径。可以给现在的轨迹数据进行纠偏。
2、Neo4j Spatial库
Neo4j Spatial是一个让Neo4j能够进行完整的空间操作的库,支持ESRI Shapfile文件和OSM数据的导入,支持大多数的几何形状如点、线、多边形等,能够对时空数据进行拓扑操作如包含、覆盖、相交等。此外,Neo4j Spatial除了本身的基于空间结构的R-Tree索引外,可以灵活的支持其他索引,只要能够将数据映射为几何形状都可以使用Neo4j Spatial处理。这些特征使得Neo4j对时空数据的分析和处理效率更高、使用范围更广。
(武汉路网)目录如下:
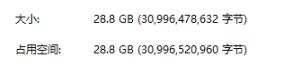
文件总大小截图
经过清洗汇总去重导入到图数据库中显示节点数据总共:

当前数据库节点数:
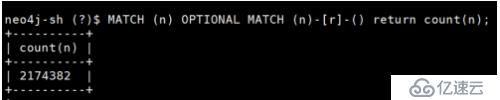
总共武汉有经纬度点约200万,点与点的关系约400万,全部保存进去数据文件约占磁盘空间4.5G,加上后续要添加点与点的距离和角度等属性数据,武汉路网数据总共约占磁盘10G。
根据城市规模计算,与武汉同等规模城市(一线城市、新一线城市)有:
北京市、上海市、广州市、深圳市、成都市、杭州市、武汉市、重庆市、南京市、天津市、苏州市、西安市、长沙市、沈阳市、青岛市、郑州市、大连市、东莞市、宁波市。保守估计占据磁盘空间200G。二线城市路网数据保守估计100G。城市之间数据约100G(数据量通过POI比例所占估计),所以申请机器磁盘500G。
用py2neo访问图数据库,模拟二十个线程不断计算最短路径,机器配置和CPU情况如下:

程序截图

机器配置截图
CPU状态截图

内存状态截图

图中采用8核心处理器、8G内存,CPU和内存基本用完,访问频率约在20次1秒,根据日百万订单规划也就是每秒11.57次,高峰时期,每秒在10这个数量级。保留一定的空余给操作系统使用,所以申请16G内存。
只读副本的主要职责是扩展图操作的工作负载(比如:Cypher查询、过程处理等)。只读副本就像是核心云服务器中受保护数据的高速缓存,但他们不是简单的的键值高速缓存。事实上,只读副本是能够完成任意(只读)图查询和过程处理的全功能的Neo4j数据库。
只读副本通过事务日志以异步的方式从核心云服务器复制数据。只读副本会周期性的(通常在毫秒范围内)轮询核心云服务器,以查找自上次轮询后处理的任何新事务,然后核心云服务器将这些新事务发送到只读副本。大量的只读副本可以从相对较少的核心云服务器复制数据,从而确保大量的图查询工作负载得以分摊。
因为我们的查询具有较高的独立性,例如一个在武汉的网约车的路径完全在武汉数据范围内完成查询。所以当后续负载压力提高时,可以将不同城市的数据分别部署到不同的机器上,城市间城际拼车需要的数据可以另外部署。也可根据不同的经纬度范围放置数据来分摊查询压力。
对于以上图数据库Neo4j应用在在GIS系统的优势相关内容,大家还有什么不明白的地方吗?或者想要了解更多相关,可以继续关注我们的行业资讯板块。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





