小编给大家分享一下Python Pandas读取Excel日期数据的异常处理怎么办,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
有时我们的Excel有一个调整过自定义格式的日期字段:
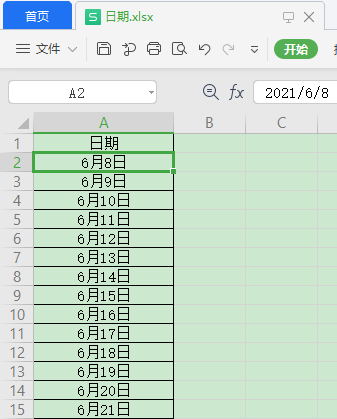
当我们用pandas读取时却是这样的效果:
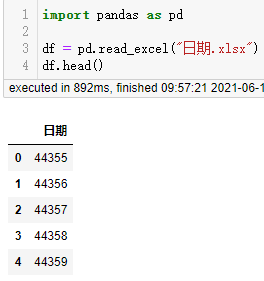
不管如何指定参数都无效。
没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值。
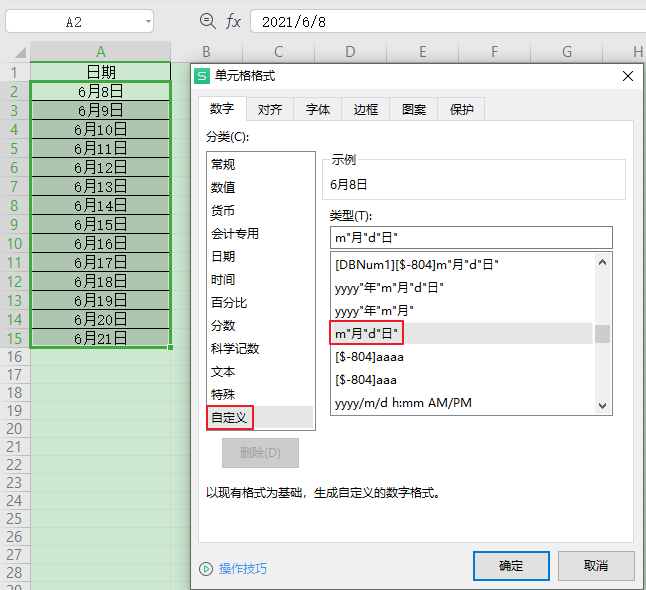
可以修改为系统内置的自定义格式:
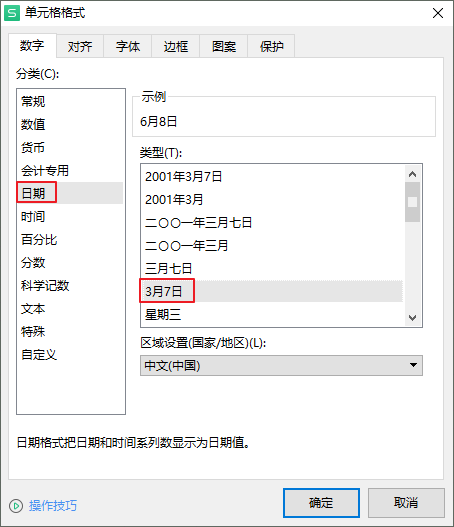
或者在自定义格式上补充负数的定义:
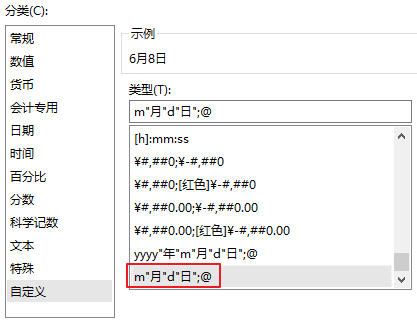
增加;@即可
有时这种Excel很多,我们需要通过pandas批量读取,挨个人工修改Excel的自定义格式费时费力,下面我演示如何使用pandas直接解析这些数值成为日期格式。
excel中常规格式和日期格式的转换规则如下:
1900/1/1为起始日期,转换的数字是1,往后的每一天增加1
1900/1/2转换为数字是 2
1900/1/3转换为数字是 3
1900/1/4转换为数字是 4
以此类推
excel中时间转换规则如下:
在时间中的规则是把1天转换为数字是 1
每1小时就是 1/24
每1分钟就是 1/(24×60)=1/1440
每1秒钟就是 1/(24×60×60)=1/86400
根据Excel的日期存储规则,我们只需要以1900/1/1为基准日期,根据数值n偏移n-1天即可得到实际日期。不过还有个问题,Excel多存储了1900年2月29日这一天,而正常的日历是没有这一天的,而我们的日期又都是大于1900年的,所以应该偏移n-2天,干脆使用1899年12月30日作为基准,这样不需要作减法操作。
解析代码如下:
import pandas as pd
from pandas.tseries.offsets import Day
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.apply(lambda x: f"{x.month}月{x.day}日")
df.head()| 日期 | |
|---|---|
| 0 | 6月8日 |
| 1 | 6月9日 |
| 2 | 6月10日 |
| 3 | 6月11日 |
| 4 | 6月12日 |
如果需要调用time的strftime方法,由于包含中文则需要设置locale:
import pandas as pd
from pandas.tseries.offsets import Day
import locale
locale.setlocale(locale.LC_CTYPE, 'chinese')
df = pd.read_excel("日期.xlsx")
basetime = pd.to_datetime("1899/12/30")
df.日期 = df.日期.apply(lambda x: basetime+Day(x))
df.日期 = df.日期.dt.strftime('%Y年%m月%d日')
df.head()| 日期 | |
|---|---|
| 0 | 2021年06月08日 |
| 1 | 2021年06月09日 |
| 2 | 2021年06月10日 |
| 3 | 2021年06月11日 |
| 4 | 2021年06月12日 |
看完了这篇文章,相信你对“Python Pandas读取Excel日期数据的异常处理怎么办”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



