дҪҝз”ЁPandasжҖҺд№ҲиҜ»еҸ–excel
дҪҝз”ЁPandasжҖҺд№ҲиҜ»еҸ–excelпјҹзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
йҰ–е…ҲеҸҜд»Ҙе…ҲеҲӣе»әдёҖдёӘexcelж–Ү件еҪ“дҪңе®һйӘҢж•°жҚ®пјҢеҗҚз§°дёәexample.xlsxпјҢеҶ…е®№еҰӮдёӢпјҡ
| name | age | gender |
|---|
| John | 30 | male |
| Mary | 22 | female |
| Smith | 32 | male |
иҝҷйҮҢжҳҜеҫҲз®ҖеҚ•зҡ„еҮ иЎҢж•°жҚ®пјҢжҲ‘们жқҘз”Ёpandasе®һйҷ…ж“ҚдҪңдёҖдёӢиҝҷдёӘexcelиЎЁгҖӮ
# coding:utf-8
import pandas as pd
data = pd.read_excel('example.xlsx', sheet_name='Sheet1')
print dataз»“жһңеҰӮдёӢпјҡ
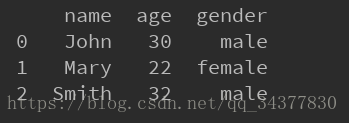
иҝҷйҮҢдҪҝз”ЁдәҶread_excel()ж–№жі•жқҘиҜ»еҸ–excelпјҢжқҘзңӢдёҖдёӘread_excel()иҝҷдёӘж–№жі•зҡ„APIпјҢиҝҷйҮҢеҸӘжҲӘйҖүдёҖйғЁеҲҶз»ҸеёёдҪҝз”Ёзҡ„еҸӮж•°пјҡ
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
иҝҷйҮҢдё»иҰҒеҸӮж•°дёәioпјҢsheet_nameпјҢheaderпјҢusecolsе’Ңnames
ioпјҡexcelж–Ү件пјҢеҰӮжһңе‘ҪеҗҚдёәдёӯж–ҮпјҢеңЁpython2.7дёӯпјҢйңҖиҰҒдҪҝз”Ёdecode()жқҘи§Јз ҒжҲҗunicodeеӯ—з¬ҰдёІпјҢдҫӢеҰӮпјҡ pd.read_excel('зӨәдҫӢ'.decode('utf-8))
sheet_nameпјҡиҝ”еӣһжҢҮе®ҡзҡ„sheetпјҢеҰӮжһңе°Ҷsheet_nameжҢҮе®ҡдёәNoneпјҢеҲҷиҝ”еӣһе…ЁиЎЁпјҢеҰӮжһңйңҖиҰҒиҝ”еӣһеӨҡдёӘиЎЁпјҢеҸҜд»Ҙе°Ҷsheet_nameжҢҮе®ҡдёәдёҖдёӘеҲ—иЎЁпјҢдҫӢеҰӮ['sheet1', 'sheet2']
headerпјҡжҢҮе®ҡж•°жҚ®иЎЁзҡ„иЎЁеӨҙпјҢй»ҳи®ӨеҖјдёә0пјҢеҚіе°Ҷ第дёҖиЎҢдҪңдёәиЎЁеӨҙгҖӮ
usecolsпјҡиҜ»еҸ–жҢҮе®ҡзҡ„еҲ—пјҢдҫӢеҰӮжғіиҰҒиҜ»еҸ–第дёҖеҲ—е’Ң第дәҢеҲ—ж•°жҚ®пјҡ
pd.read_excel("example.xlsx", sheet_name=None, usecols=[0, 1])иҝҷйҮҢе…ҲжқҘдёҖдёӘеңЁжңәеҷЁеӯҰд№ дёӯз»ҸеёёдҪҝз”Ёзҡ„пјҡе°ҶжүҖжңүgenderдёәmaleзҡ„еҖјж”№дёә0пјҢfemaleж”№дёә1гҖӮ
# coding:utf-8
import pandas as pd
from pandas import DataFrame
# иҜ»еҸ–ж–Ү件
data = pd.read_excel("example.xlsx", sheet_name="Sheet1")
# жүҫеҲ°genderиҝҷдёҖеҲ—пјҢеҶҚеңЁиҝҷдёҖеҲ—дёӯиҝӣиЎҢжҜ”иҫғ
data['gender'][data['gender'] == 'male'] = 0
data['gender'][data['gender'] == 'female'] = 1
print dataз»“жһңеҰӮдёӢпјҡ
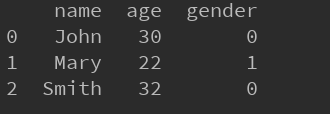
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝҷйҮҢзҡ„dataдёәexcelж•°жҚ®зҡ„дёҖд»ҪжӢ·иҙқпјҢеҜ№dataиҝӣиЎҢдҝ®ж”№е№¶дёҚдјҡзӣҙжҺҘеҪұе“ҚеҲ°жҲ‘们еҺҹжқҘзҡ„excelпјҢеҝ…йЎ»еңЁдҝ®ж”№еҗҺдҝқеӯҳжүҚиғҪеӨҹдҝ®ж”№excelгҖӮдҝқеӯҳзҡ„д»Јз ҒеҰӮдёӢпјҡ
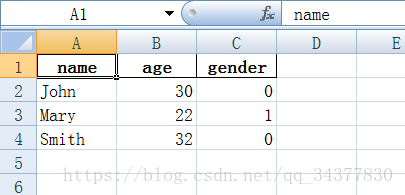
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)иҝҷж—¶еҖҷжҲ‘们еҶҚжү“ејҖexample.xlsxж–Ү件зңӢзңӢжҳҜеҗҰжӣҙж”№дәҶпјҡ
еҰӮжһңжҲ‘们жғіиҰҒж–°еўһеҠ дёҖеҲ—жҲ–иҖ…дёҖиЎҢж•°жҚ®жҖҺд№ҲеҠһе‘ўпјҹиҝҷйҮҢз»ҷеҮәеҸӮиҖғпјҡ
ж–°еўһеҲ—ж•°жҚ®пјҡ
data['еҲ—еҗҚз§°'] = None
ж–°еўһиЎҢж•°жҚ®пјҢиҝҷйҮҢиЎҢзҡ„numдёәexcelдёӯиҮӘеҠЁз»ҷиЎҢеҠ зҡ„idж•°еҖј
data.loc[иЎҢзҡ„num] = [еҖј1пјҢ еҖј2пјҢ ...]
д»ҘдёҠйқўзҡ„ж•°жҚ®дёәдҫӢпјҡ
# coding:utf-8
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# еўһеҠ иЎҢж•°жҚ®пјҢеңЁз¬¬5иЎҢж–°еўһ
data.loc[5] = ['James', 32, 'male']
# еўһеҠ еҲ—ж•°жҚ®пјҢз»ҷе®ҡй»ҳи®ӨеҖјNone
data['profession'] = None
# дҝқеӯҳж•°жҚ®
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)жү“ејҖexcelзңӢеҲ°зҡ„з»“жһңеҰӮдёӢпјҡ
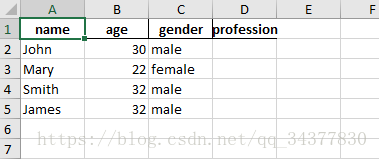
иҜҙе®ҢдәҶеўһеҠ дёҖиЎҢжҲ–дёҖеҲ—пјҢйӮЈжҖҺж ·еҲ йҷӨдёҖиЎҢжҲ–дёҖеҲ—е‘ўпјҹ
import pandas as pd
from pandas import DataFrame
data = pd.read_excel("example.xlsx", sheet_name='Sheet1')
# еҲ йҷӨgenderеҲ—пјҢйңҖиҰҒжҢҮе®ҡaxisдёә1пјҢеҪ“еҲ йҷӨиЎҢж—¶пјҢaxisдёә0
data = data.drop('gender', axis=1)
# еҲ йҷӨ第3,4иЎҢпјҢиҝҷйҮҢдёӢиЎЁд»Ҙ0ејҖе§ӢпјҢ并且ж ҮйўҳиЎҢдёҚз®—еңЁзұ»
data = data.drop([2, 3], axis=0)
# дҝқеӯҳ
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)иҝҷж—¶еҖҷжү“ејҖexcelеҸҜд»ҘзңӢи§ҒgenderеҲ—е’ҢйҷӨж ҮйўҳиЎҢзҡ„第3пјҢ4иЎҢиў«еҲ йҷӨдәҶгҖӮ

зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎдҪҝз”ЁPandasжҖҺд№ҲиҜ»еҸ–excelзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ





