yolov5и®ӯз»ғж—¶еҸӮж•°workersдёҺbatch-sizeзҡ„зӨәдҫӢеҲҶжһҗ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іyolov5и®ӯз»ғж—¶еҸӮж•°workersдёҺbatch-sizeзҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
yolov5и®ӯз»ғе‘Ҫд»Ө
python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100
yolov5зҡ„и®ӯз»ғеҫҲз®ҖеҚ•пјҢдёӢиҪҪеҘҪд»“еә“пјҢиЈ…еҘҪдҫқиө–еҗҺпјҢеҸӘйңҖиҮӘе®ҡд№үдёҖдёӢdataзӣ®еҪ•дёӯзҡ„yamlж–Ү件е°ұеҸҜд»ҘдәҶгҖӮиҝҷйҮҢжҲ‘дҪҝз”ЁиҮӘе®ҡд№үзҡ„my.yamlж–Ү件пјҢйҮҢйқўе°ұжҳҜе®ҡд№үж•°жҚ®йӣҶдҪҚзҪ®е’Ңи®ӯз»ғз§Қзұ»ж•°е’ҢеҗҚеӯ—гҖӮ
workersе’Ңbatch-sizeеҸӮж•°зҡ„зҗҶи§Ј
дёҖиҲ¬и®ӯз»ғдё»иҰҒйңҖиҰҒи°ғж•ҙзҡ„еҸӮж•°жҳҜиҝҷдёӨдёӘпјҡ
workers
жҢҮж•°жҚ®иЈ…иҪҪж—¶cpuжүҖдҪҝз”Ёзҡ„зәҝзЁӢж•°пјҢй»ҳи®Өдёә8гҖӮд»Јз Ғи§ЈйҮҠеҰӮдёӢ
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')дёҖиҲ¬й»ҳдҪҝз”Ё8зҡ„иҜқпјҢдјҡжҠҘй”ҷ~~гҖӮеҺҹеӣ жҳҜзҲҶзі»з»ҹеҶ…еӯҳпјҢйҷӨдәҶзү©зҗҶеҶ…еӯҳеӨ–пјҢйңҖиҰҒи°ғж•ҙзі»з»ҹзҡ„иҷҡжӢҹеҶ…еӯҳгҖӮи®ӯз»ғж—¶дё»иҰҒзңӢе·ІжҸҗдәӨе“ӘйҮҢзҡ„е®һйҷ…еҖјжҳҜеҗҰдјҡи¶…иҝҮжңҖеӨ§еҖјпјҢи¶…иҝҮдәҶдёҚжҳҜејәйҖҖзЁӢеәҸе°ұжҳҜжҠҘй”ҷгҖӮ

жүҖд»ҘйңҖиҰҒж №жҚ®е®һйҷ…жғ…еҶөеҲҶй…Қзі»з»ҹиҷҡжӢҹеҶ…еӯҳ(pythonжү§иЎҢзЁӢеәҸжүҖеңЁзҡ„зӣҳ)зҡ„жңҖеӨ§еҖј
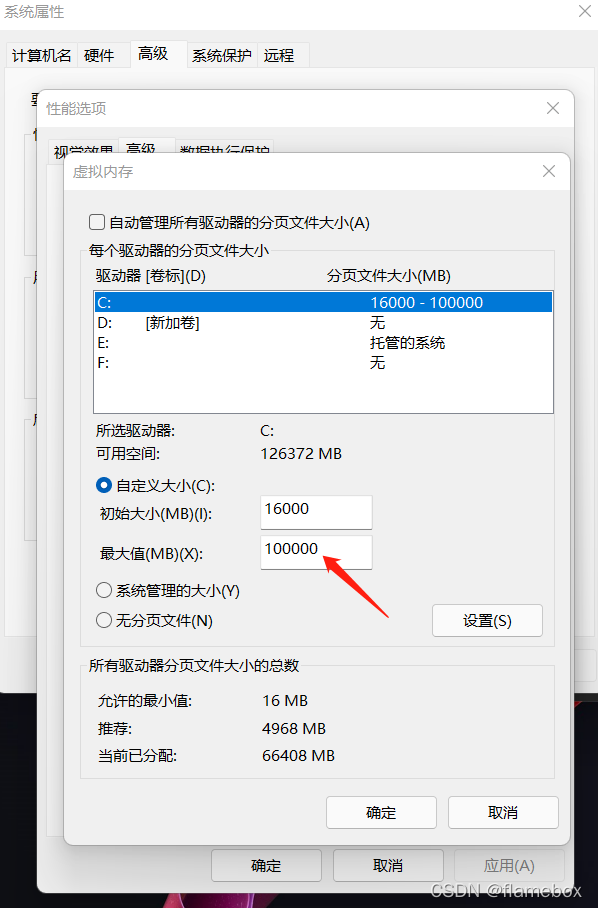
batch-size
е°ұжҳҜдёҖж¬ЎеҫҖGPUе“ӘйҮҢеЎһеӨҡе°‘еј еӣҫзүҮдәҶгҖӮеҶіе®ҡдәҶжҳҫеӯҳеҚ з”ЁеӨ§е°ҸпјҢй»ҳи®ӨжҳҜ16гҖӮ
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')и®ӯз»ғж—¶жҳҫеӯҳеҚ з”Ёи¶ҠеӨ§еҪ“然ж•Ҳжһңи¶ҠеҘҪпјҢдҪҶеҰӮжһңзҲҶжҳҫеӯҳпјҢд№ҹжҳҜдјҡж— жі•и®ӯз»ғзҡ„гҖӮжҲ‘дҪҝз”Ё–batch-size 32ж—¶пјҢжҳҫеӯҳе·®дёҚеӨҡиғҪеҲ©з”Ёе®ҢгҖӮ

дёӨдёӘеҸӮж•°зҡ„и°ғдјҳ
еҜ№дәҺworkersпјҢ并дёҚжҳҜи¶ҠеӨ§и¶ҠеҘҪпјҢеӨӘеӨ§ж—¶gpuе…¶е®һеӨ„зҗҶдёҚиҝҮжқҘпјҢи®ӯз»ғйҖҹеәҰдёҖж ·пјҢдҪҶиҷҡжӢҹеҶ…еӯҳпјҲзЈҒзӣҳз©әй—ҙпјүдјҡжҲҗеҖҚеҚ з”ЁгҖӮ
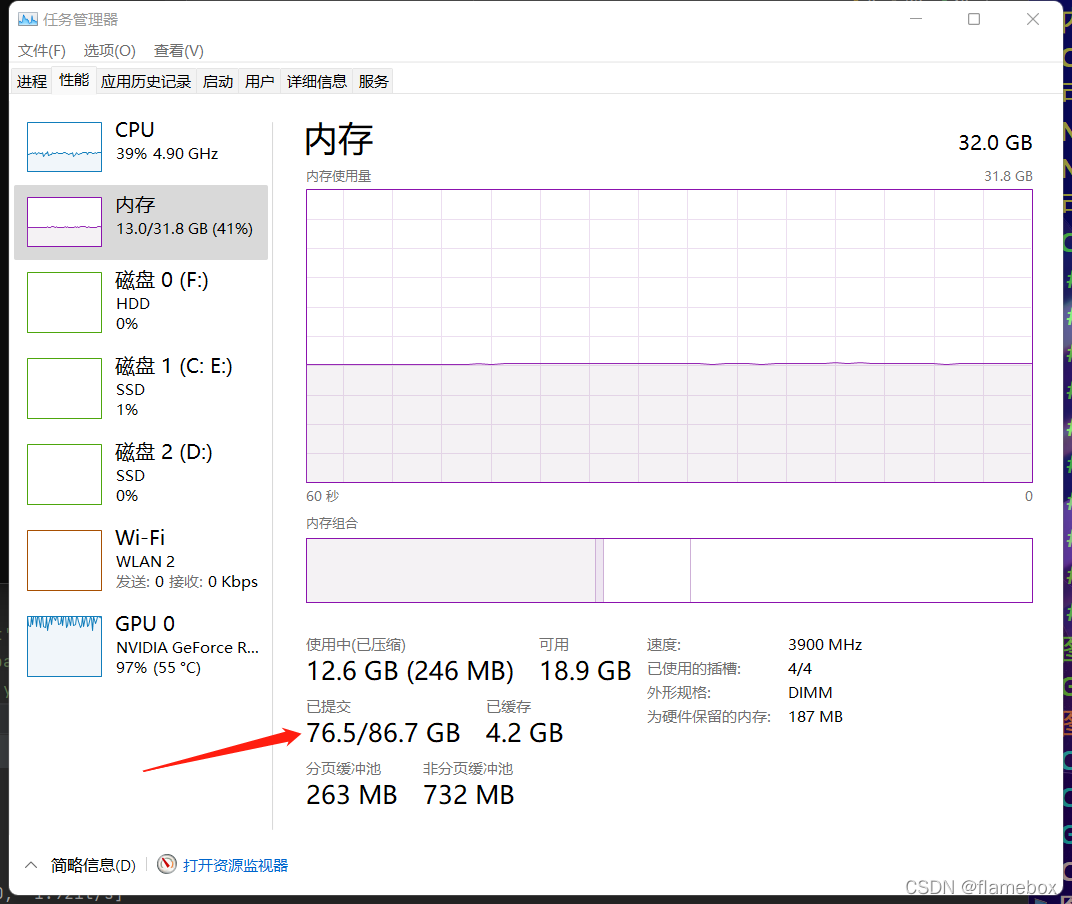
workersдёә4ж—¶зҡ„еҶ…еӯҳеҚ з”Ё
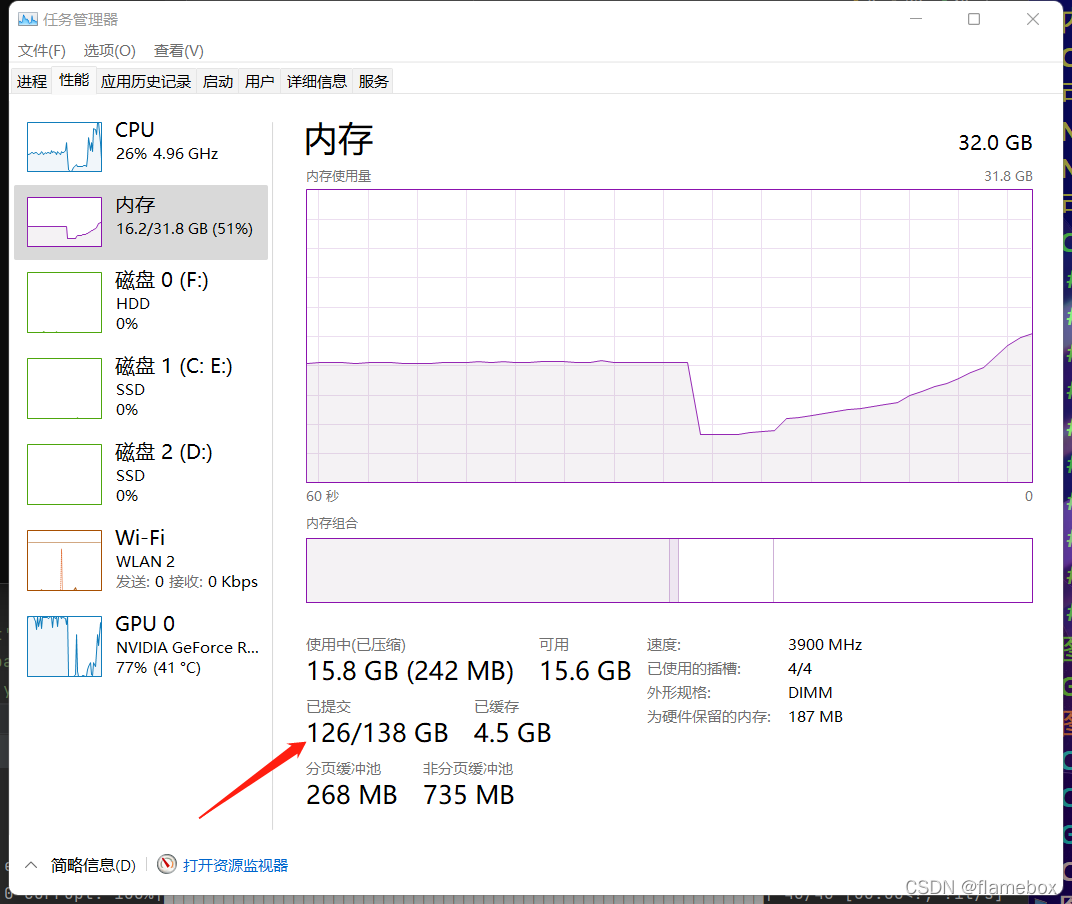
workersдёә8ж—¶зҡ„еҶ…еӯҳеҚ з”Ё
жҲ‘зҡ„жҳҫеҚЎжҳҜrtx3050пјҢе®һйҷ…дҪҝз”ЁдёӯдёҠеҲ°4д»ҘдёҠе°ұе·®еҲ«дёҚеӨ§дәҶпјҢgpuе®Ңе…Ёеҗғж»ЎдәҶгҖӮдҪҶжҳҜеҰӮжһңи®ҫзҪ®еҫ—еӨӘе°ҸпјҢgpuдјҡи·‘дёҚж»ЎгҖӮжҜ”еҰӮеҪ“workers=1ж—¶пјҢжҳҫеҚЎеҠҹиҖ—еҸӘеҫ—72WпјҢйҖҹеәҰж…ўдәҶдёҖеҚҠпјӣworkers=4ж—¶пјҢжҳҫеҚЎеҠҹиҖ—иғҪдёҠеҲ°120+wпјҢе®Ңе…ЁжҰЁе№ІдәҶжҳҫеҚЎзҡ„з®—еҠӣгҖӮжүҖд»ҘйңҖиҰҒж №жҚ®дҪ е®һйҷ…зҡ„з®—еҠӣи°ғж•ҙиҝҷдёӘеҸӮж•°гҖӮ

2. еҜ№дәҺbatch-sizeпјҢжңүзӮ№зҺ„еӯҰгҖӮзҗҶи®әжҳҜиғҪе°ҪйҮҸи·‘ж»ЎжҳҫеӯҳдёәдҪіпјҢдҪҶе®һйҷ…жөӢиҜ•дёӢжқҘпјҢеҸ‘зҺ°еҪ“дёә8зҡ„еҖҚж•°ж—¶ж•ҲзҺҮжӣҙй«ҳдёҖзӮ№гҖӮе°ұжҳҜ32ж—¶зҡ„и®ӯз»ғж•ҲзҺҮдјҡжҜ”34зҡ„й«ҳдёҖзӮ№пјҢиҝҷйҮҢе°ұдёҚеӨӘжё…жҘҡеҺҹзҗҶжҳҜд»Җд№ҲдәҶпјҢе®һйҷ…ж“ҚдҪңдёӢжқҘжҳҜиҝҷж ·гҖӮ
е…ідәҺвҖңyolov5и®ӯз»ғж—¶еҸӮж•°workersдёҺbatch-sizeзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





