本文小编为大家详细介绍“python热力图怎么实现”,内容详细,步骤清晰,细节处理妥当,希望这篇“python热力图怎么实现”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
该方法是对原始数据进行线性变换,将其映射到[0,1]之间,该方法也被称为离差标准化。
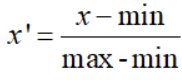
上式中,min是样本的最小值,max是样本的最大值。由于最大值与最小值可能是动态变化的,同时也非常容易受噪声(异常点、离群点)影响,因此一般适合小数据的场景。此外,该方法还有两点好处:
1) 如果某属性/特征的方差很小,如身高:np.array([[1.70],[1.71],[1.72],[1.70],[1.73]]),实际5条数据在身高这个特征上是有差异的,但是却很微弱,这样不利于模型的学习,进行min-max归一化后为:array([[ 0. ], [ 0.33333333], [ 0.66666667], [ 0. ], [ 1. ]]),相当于放大了差异;
2) 维持稀疏矩阵中为0的条目。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_wine
wine = load_wine()
data = wine.data # 数据
lables = wine.target # 标签
feaures = wine.feature_names
df = pd.DataFrame(data, columns=feaures) # 原始数据
# 第一步:无量纲化
def standareData(df):
"""
df : 原始数据
return : data 标准化的数据
"""
data = pd.DataFrame(index=df.index) # 列名,一个新的dataframe
columns = df.columns.tolist() # 将列名提取出来
for col in columns:
d = df[col]
max = d.max()
min = d.min()
mean = d.mean()
data[col] = ((d - mean) / (max - min)).tolist()
return data
# 某一列当做参照序列,其他为对比序列
def graOne(Data, m=0):
"""
return:
"""
columns = Data.columns.tolist() # 将列名提取出来
# 第一步:无量纲化
data = standareData(Data)
referenceSeq = data.iloc[:, m] # 参考序列
data.drop(columns[m], axis=1, inplace=True) # 删除参考列
compareSeq = data.iloc[:, 0:] # 对比序列
row, col = compareSeq.shape
# 第二步:参考序列 - 对比序列
data_sub = np.zeros([row, col])
for i in range(col):
for j in range(row):
data_sub[j, i] = abs(referenceSeq[j] - compareSeq.iloc[j, i])
# 找出最大值和最小值
maxVal = np.max(data_sub)
minVal = np.min(data_sub)
cisi = np.zeros([row, col])
for i in range(row):
for j in range(col):
cisi[i, j] = (minVal + 0.5 * maxVal) / (data_sub[i, j] + 0.5 * maxVal)
# 第三步:计算关联度
result = [np.mean(cisi[:, i]) for i in range(col)]
result.insert(m, 1) # 参照列为1
return pd.DataFrame(result)
def GRA(Data):
df = Data.copy()
columns = [str(s) for s in df.columns if s not in [None]] # [1 2 ,,,12]
# print(columns)
df_local = pd.DataFrame(columns=columns)
df.columns = columns
for i in range(len(df.columns)): # 每一列都做参照序列,求关联系数
df_local.iloc[:, i] = graOne(df, m=i)[0]
df_local.index = columns
return df_local
# 热力图展示
def ShowGRAHeatMap(DataFrame):
colormap = plt.cm.hsv
ylabels = DataFrame.columns.values.tolist()
f, ax = plt.subplots(figsize=(15, 15))
ax.set_title('Wine GRA')
# 设置展示一半,如果不需要注释掉mask即可
mask = np.zeros_like(DataFrame)
mask[np.triu_indices_from(mask)] = True # np.triu_indices 上三角矩阵
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
mask=mask,
)
plt.show()
data_wine_gra = GRA(df)
ShowGRAHeatMap(data_wine_gra)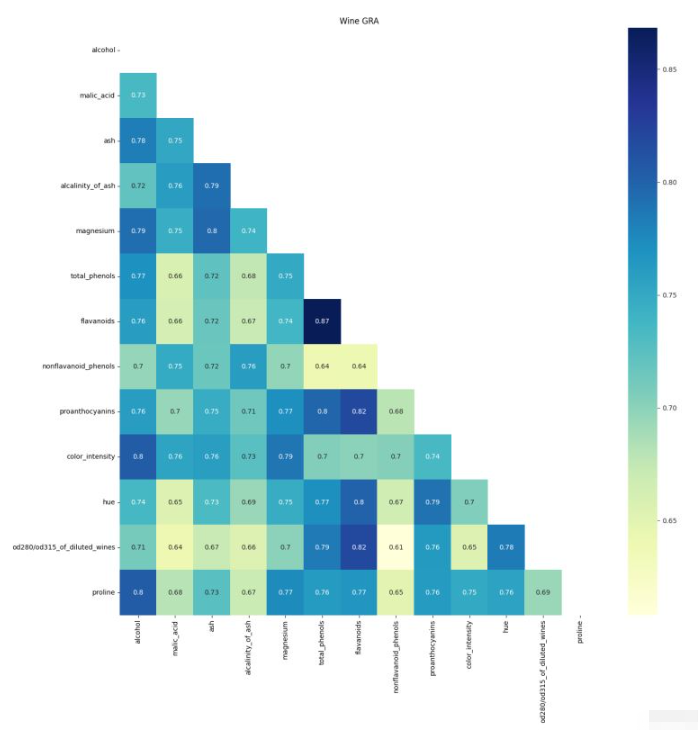
利用热力图可以看数据表里多个特征两两的相似度。
相似度由皮尔逊相关系数度量。
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
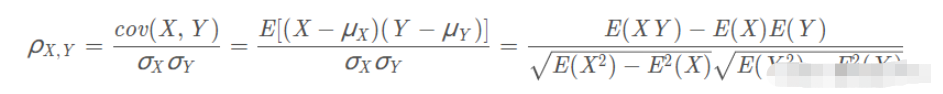
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# ====热力图
from matplotlib.ticker import FormatStrFormatter
encoding="utf-8"
data = pd.read_csv("tu.csv", encoding="utf-8") #读取数据
data.drop_duplicates()
data.columns = [i for i in range(data.shape[1])]
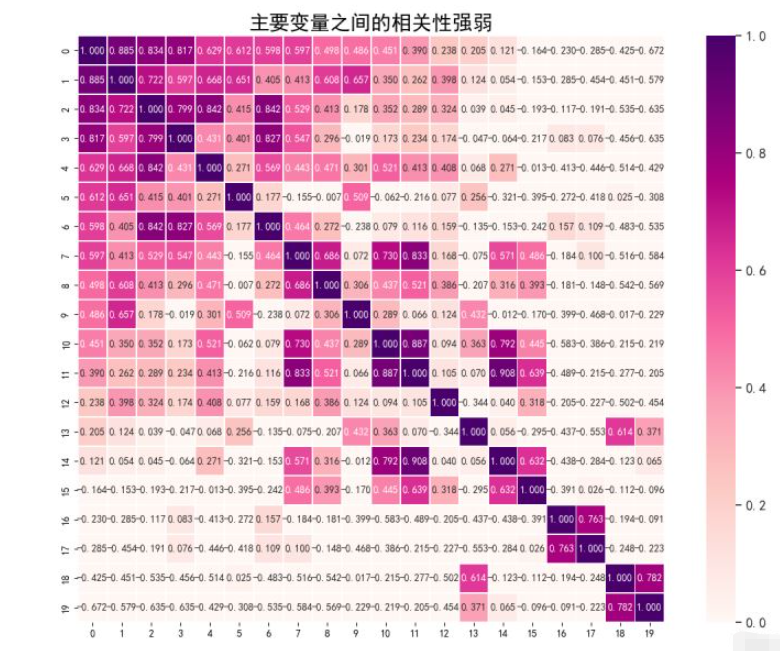
# 计算两两属性之间的皮尔森相关系数
corrmat = data.corr()
f, ax = plt.subplots(figsize=(12, 9))
# 返回按“列”降序排列的前n行
k = 30
cols = corrmat.nlargest(k, data.columns[0]).index
# 返回皮尔逊积矩相关系数
cm = np.corrcoef(data[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm,
cbar=True,
annot=True,
square=True,
fmt=".3f",
vmin=0, #刻度阈值
vmax=1,
linewidths=.5,
cmap="RdPu", #刻度颜色
annot_kws={"size": 10},
xticklabels=True,
yticklabels=True) #seaborn.heatmap相关属性
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt.ylabel(fontsize=15,)
# plt.xlabel(fontsize=15)
plt.title("主要变量之间的相关性强弱", fontsize=20)
plt.show()1)Seaborn是基于matplotlib的Python可视化库
seaborn.heatmap()热力图,用于展示一组变量的相关系数矩阵,列联表的数据分布,通过热力图我们可以直观地看到所给数值大小的差异状况。
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
2)参数输出(均为默认值)
sns.heatmap( data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor=‘white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels=‘auto', yticklabels=‘auto', mask=None, ax=None, )
3)具体介绍
(1)热力图输入数据参数data:矩阵数据集,可以是numpy的数组(array),也可以是pandas的DataFrame。如果是DataFrame,则df的index/column信息会分别对应到heatmap的columns和rows,即df.index是热力图的行标,df.columns是热力图的列标
(2)热力图矩阵块颜色参数vmax,vmin:分别是热力图的颜色取值最大和最小范围,默认是根据data数据表里的取值确定
(3)热力图矩阵块注释参数
cmap:从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;改参数默认值:根据center参数设定
center:数据表取值有差异时,设置热力图的色彩中心对齐值;通过设置center值,可以调整生成的图像颜色的整体深浅;设置center数据时,如果有数据溢出,则手动设置的vmax、vmin会自动改变
robust:默认取值False;如果是False,且没设定vmin和vmax的值,热力图的颜色映射范围根据具有鲁棒性的分位数设定,而不是用极值设定annot(annotate的缩写):默认取值False;如果是True,在热力图每个方格写入数据;如果是矩阵,在热力图每个方格写入该矩阵对应位置数据
(4)热力图矩阵块之间间隔及间隔线参数
fmt:字符串格式代码,矩阵上标识数字的数据格式,比如保留小数点后几位数字
annot_kws:默认取值False;如果是True,设置热力图矩阵上数字的大小颜色字体,matplotlib包text类下的字体设置;linewidths:定义热力图里“表示两两特征关系的矩阵小块”之间的间隔大小
(5)热力图颜色刻度条参数
linecolor:切分热力图上每个矩阵小块的线的颜色,默认值是’white’cbar:是否在热力图侧边绘制颜色刻度条,默认值是True
(6)square:设置热力图矩阵小块形状,默认值是False
cbar_kws:热力图侧边绘制颜色刻度条时,相关字体设置,默认值是None
cbar_ax:热力图侧边绘制颜色刻度条时,刻度条位置设置,默认值是Nonexticklabels, yticklabels:xticklabels控制每列标签名的输出;yticklabels控制每行标签名的输出。默认值是auto。如果是True,则以DataFrame的列名作为标签名。如果是False,则不添加行标签名。如果是列表,则标签名改为列表中给的内容。如果是整数K,则在图上每隔K个标签进行一次标注。 如果是auto,则自动选择标签的标注间距,将标签名不重叠的部分(或全部)输出
mask:控制某个矩阵块是否显示出来。默认值是None。如果是布尔型的DataFrame,则将DataFrame里True的位置用白色覆盖掉
ax:设置作图的坐标轴,一般画多个子图时需要修改不同的子图的该值
**kwargs:所有其他关键字参数都传递给 ax.pcolormesh。
读到这里,这篇“python热力图怎么实现”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





