这篇文章主要讲解了“Python sklearn中的K-Means聚类如何使用”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python sklearn中的K-Means聚类如何使用”吧!
k-means翻译过来就是K均值聚类算法,其目的是将样本分割为k个簇,而这个k则是KMeans中最重要的参数:n_clusters,默认为8。
下面做一个最简单的聚类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
X, y = make_blobs(1500)
fig = plt.figure()
for i in range(2):
ax = fig.add_subplot(1,2,i+1)
y = KMeans(i+2).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()其中,y是聚类结果,其数值表示对应位置X所属类号。
效果如图所示,对于下面这组数据来说,显然最好是分为两类,但如果KMeans的n_clusters设为3,那就会聚成3类。

上面调用的KMeans是一个类,sklearn中同样提供了函数形式的调用,其使用方法如下
from sklearn.cluster import k_means
cen, y, interia = k_means(X, 3)其中,cen表示聚类后,每一类的质心;y为聚类后的标签;interia表示均方误差之和。
在KMeans最重要的概念是簇,也就是被分割后的数据种类;而每个簇都有一个非常重要的点,就是质心。在设定好簇的个数之后,也就相当于确定了质心的个数,而KMeans算法的基本流程是
选择k个点作为k个簇的初始质心
计算样本到这k个质心(簇)的距离,并将其划入距离最近的簇中
计算每个簇的均值,并使用该均值更新簇的质心
重复上述2-3的操作,直到质心区域稳定或者达到最大迭代次数。
从这个流程可以看出来,KMeans算法至少有两个细节需要考虑,一个是初始化方案,另一个则是质心更新的方案。
在KMeans类或者k_means函数中,提供了两种初始化质心方案,通过参数init来控制
'random':表示随机生成k个质心
'k-means++':此为默认值,通过kMeans++方法来初始化质心。
kMeans++初始化质心的流程如下
随机选择1个点作为初始质心 x 0
计算其他点到最近质心的距离
假定现有 n n n个质心了,那么选择距离当前质心较远的点作为下一个质心 x n x_n xn
重复步骤2和3,直到质心个数达到 k k k个。
若希望直接调用kMeans++函数,则可使用kmeans_plusplus。
sklearn提供了KMeans的一个变种MiniBatchKMeans,可在每次训练迭代中随机抽样,这种小批量的训练过程大大减少了运算时间。
当样本量非常巨大时,小批KMeans的优势是非常明显的
from sklearn.cluster import MiniBatchKMeans
import time
ys, xs = np.indices([4,4])*6
cens = list(zip(xs.reshape(-1), ys.reshape(-1)))
X, y = make_blobs(100000,centers=cens)
km = KMeans(16)
mbk = MiniBatchKMeans(16)
def test(func, value):
t = time.time()
func(value)
print("耗时", time.time()-t)
test(km.fit_predict, X)
# 耗时 3.2028110027313232
test(mbk.fit_predict, X)
# 耗时 0.2590029239654541可见效果非常明显,其中fit_predict和predict相似,但并没有返回值,km.fit_predict(X)运行之后,会更改km中的labels_属性,此即分类结果
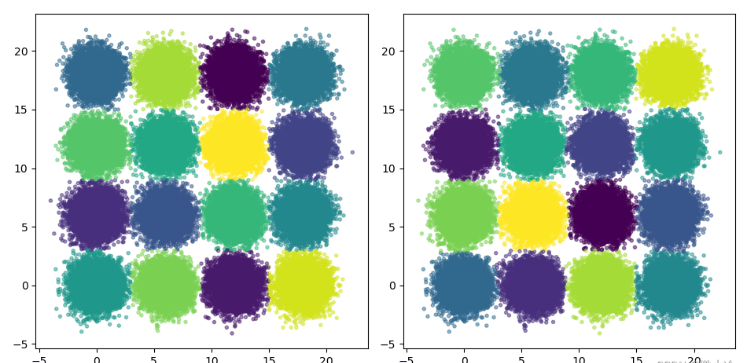
fig = plt.figure()
ax = fig.add_subplot(1,2,1)
ax.scatter(X[:,0], X[:,1], c=km.labels_,
marker='.', alpha=0.5)
ax = fig.add_subplot(1,2,2)
ax.scatter(X[:,0], X[:,1], c=mbk.labels_,
marker='.', alpha=0.5)
plt.show()效果如图所示,可见小批的KMeans算法和KMeans算法从结果上来看区别不大。
感谢各位的阅读,以上就是“Python sklearn中的K-Means聚类如何使用”的内容了,经过本文的学习后,相信大家对Python sklearn中的K-Means聚类如何使用这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



