PythonВ multiprocessingиҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸеҰӮдҪ•е®һзҺ°
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPython multiprocessingиҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸеҰӮдҪ•е®һзҺ°вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁPython multiprocessingиҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸеҰӮдҪ•е®һзҺ°й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқPython multiprocessingиҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸеҰӮдҪ•е®һзҺ°вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
1гҖҒдёәд»Җд№ҲиҰҒжҺҢжҸЎиҝӣзЁӢй—ҙйҖҡдҝЎ
pythonзҡ„еӨҡзәҝзЁӢд»Јз Ғж•ҲзҺҮз”ұдәҺеҸ—еҲ¶дәҺGILпјҢдёҚиғҪеҲ©з”ЁеӨҡж ёCPUжқҘеҠ йҖҹпјҢиҖҢеӨҡиҝӣзЁӢж–№ејҸеҸҜд»Ҙз»•иҝҮGIL, еҸ‘жҢҘеӨҡCPUеҠ йҖҹзҡ„дјҳеҠҝпјҢиғҪеӨҹжҳҺжҳҫжҸҗй«ҳзЁӢеәҸзҡ„жҖ§иғҪ
дҪҶиҝӣзЁӢй—ҙйҖҡдҝЎеҚҙжҳҜдёҚеҫ—дёҚиҖғиҷ‘зҡ„й—®йўҳгҖӮ иҝӣзЁӢдёҚеҗҢдәҺзәҝзЁӢпјҢиҝӣзЁӢжңүиҮӘе·ұзҡ„зӢ¬з«ӢеҶ…еӯҳз©әй—ҙпјҢдёҚиғҪдҪҝз”Ёе…ЁеұҖеҸҳйҮҸеңЁиҝӣзЁӢй—ҙдј йҖ’ж•°жҚ®гҖӮ
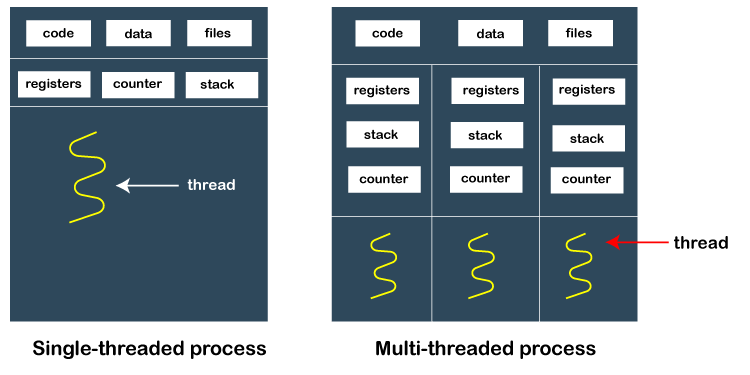
е®һйҷ…йЎ№зӣ®йңҖжұӮдёӯпјҢеёёеёёеӯҳеңЁеҜҶйӣҶи®Ўз®—гҖҒжҲ–е®һж—¶жҖ§д»»еҠЎпјҢиҝӣзЁӢд№Ӣй—ҙжңүж—¶йңҖиҰҒдј йҖ’еӨ§йҮҸж•°жҚ®пјҢеҰӮеӣҫзүҮгҖҒеӨ§еҜ№иұЎзӯүпјҢдј йҖ’ж•°жҚ®еҰӮжһңйҖҡиҝҮж–Ү件еәҸеҲ—еҢ–гҖҒжҲ–зҪ‘з»ңжҺҘеҸЈжқҘиҝӣиЎҢпјҢйҡҫд»Ҙж»Ўи¶іе®һж—¶жҖ§иҰҒжұӮпјҢйҮҮз”ЁredisпјҢжҲ–иҖ…kaffka, rabbitMQ д№Ӣ第3ж–№ж¶ҲжҒҜйҳҹеҲ—еҢ…пјҢеҸҲдҪҝзі»з»ҹеӨҚжқӮеҢ–дәҶгҖӮ
Python multiprocessing жЁЎеқ—жң¬иә«е°ұжҸҗдҫӣдәҶж¶ҲжҒҜжңәеҲ¶гҖҒеҗҢжӯҘжңәеҲ¶гҖҒе…ұдә«еҶ…еӯҳзӯүеҗ„з§Қйқһеёёй«ҳж•Ҳзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸгҖӮ
дәҶ解并жҺҢжҸЎ python иҝӣзЁӢй—ҙйҖҡдҝЎзҡ„еҗ„зұ»ж–№ејҸзҡ„дҪҝз”ЁпјҢд»ҘеҸҠе®үе…ЁжңәеҲ¶пјҢеҸҜд»Ҙеё®еҠ©еӨ§е№…жҸҗеҚҮзЁӢеәҸиҝҗиЎҢжҖ§иғҪгҖӮ
2гҖҒиҝӣзЁӢй—ҙеҗ„зұ»йҖҡдҝЎж–№ејҸз®Җд»Ӣ
иҝӣзЁӢй—ҙйҖҡдҝЎзҡ„дё»иҰҒж–№ејҸжҖ»з»“еҰӮдёӢ
е…ідәҺиҝӣзЁӢй—ҙйҖҡдҝЎзҡ„еҶ…еӯҳе®үе…Ё
еҶ…еӯҳе®үе…Ёж„Ҹе‘ізқҖпјҢеӨҡиҝӣзЁӢй—ҙеҸҜиғҪдјҡеӣ еҗҢжҠўпјҢж„ҸеӨ–й”ҖжҜҒзӯүеҺҹеӣ йҖ жҲҗе…ұдә«еҸҳйҮҸејӮеёёгҖӮ
Multiprocessing жЁЎеқ—жҸҗдҫӣзҡ„Queue, Pipe, Lock, Event еҜ№иұЎпјҢйғҪе·Іе®һзҺ°дәҶиҝӣзЁӢй—ҙйҖҡдҝЎе®үе…ЁжңәеҲ¶гҖӮ
йҮҮз”Ёе…ұдә«еҶ…еӯҳж–№ејҸйҖҡдҝЎпјҢйңҖиҰҒеңЁд»Јз ҒдёӯиҮӘе·ІжқҘи·ҹиёӘгҖҒй”ҖжҜҒиҝҷдәӣе…ұдә«еҶ…еӯҳеҸҳйҮҸпјҢеҗҰеҲҷеҸҜиғҪдјҡеҮәеҗҢжҠўгҖҒжңӘжӯЈеёёй”ҖжҜҒзӯүгҖӮйҖ жҲҗзі»з»ҹејӮеёёгҖӮ йҷӨйқһејҖеҸ‘иҖ…еҫҲжё…жҘҡе…ұдә«еҶ…еӯҳдҪҝз”Ёзү№зӮ№пјҢеҗҰеҲҷдёҚе»әи®®зӣҙжҺҘдҪҝз”ЁжӯӨе…ұдә«еҶ…еӯҳпјҢиҖҢжҳҜйҖҡиҝҮManagerз®ЎзҗҶеҷЁжқҘдҪҝз”Ёе…ұдә«еҶ…еӯҳгҖӮ
еҶ…еӯҳз®ЎзҗҶеҷЁManager
MultiprocessingжҸҗдҫӣдәҶеҶ…еӯҳз®ЎзҗҶеҷЁManagerзұ»пјҢеҸҜз»ҹдёҖи§ЈеҶіиҝӣзЁӢйҖҡдҝЎзҡ„еҶ…еӯҳе®үе…Ёй—®йўҳпјҢеҸҜд»Ҙе°Ҷеҗ„з§Қе…ұдә«ж•°жҚ®еҠ е…Ҙз®ЎзҗҶеҷЁпјҢеҢ…жӢ¬ list, dict, Queue, Lock, Event, Shared Memory зӯүпјҢз”ұе…¶з»ҹдёҖи·ҹиёӘдёҺй”ҖжҜҒгҖӮ
3гҖҒж¶ҲжҒҜжңәеҲ¶йҖҡдҝЎ
1) з®ЎйҒ“ Pipe йҖҡдҝЎж–№ејҸ
зұ»дјјдәҺ1дёҠз®ҖеҚ•зҡ„socketйҖҡйҒ“пјҢеҸҢз«ҜеқҮеҸҜ收еҸ‘ж¶ҲжҒҜгҖӮ
Pipe еҜ№иұЎзҡ„жһ„е»әж–№жі•пјҡ
parent_conn, child_conn = Pipe(duplex=True/False)
еҸӮж•°иҜҙжҳҺ
duplex=True, з®ЎйҒ“дёәеҸҢеҗ‘йҖҡдҝЎ
duplex=False, з®ЎйҒ“дёәеҚ•еҗ‘йҖҡдҝЎпјҢеҸӘжңүchild_connеҸҜд»ҘеҸ‘ж¶ҲжҒҜпјҢparent_connеҸӘиғҪжҺҘ收гҖӮ
зӨәдҫӢд»Јз Ғпјҡ
from multiprocessing import Process, Pipe
def myfunction(conn):
conn.send(['hi!! I am Python'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=myfunction, args=(child_conn,))
p.start()
print (parent_conn.recv() )
p.join()
2) ж¶ҲжҒҜйҳҹеҲ—Queue йҖҡдҝЎж–№ејҸ
Multiprocessing зҡ„Queue зұ»пјҢжҳҜеңЁpython queue 3.0зүҲжң¬дёҠдҝ®ж”№зҡ„пјҢ еҸҜд»ҘеҫҲе®№жҳ“е®һзҺ°з”ҹдә§иҖ… – ж¶ҲжҒҜиҖ…й—ҙдј йҖ’ж•°жҚ®пјҢиҖҢдё”Multiprocessingзҡ„Queue жЁЎеқ—е®һзҺ°дәҶlockе®үе…ЁжңәеҲ¶гҖӮ
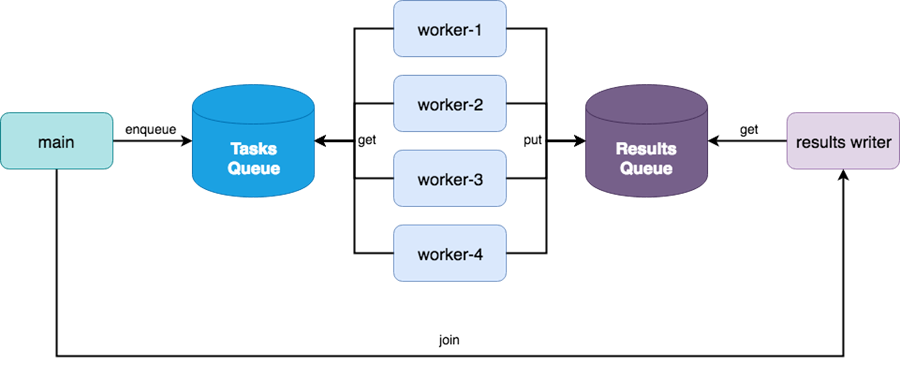
QueueжЁЎеқ—е…ұжҸҗдҫӣдәҶ3з§Қзұ»еһӢзҡ„йҳҹеҲ—гҖӮ
(1) FIFO queue , е…Ҳиҝӣе…ҲеҮәпјҢ
class queue.Queue(maxsize=0)
(2) LIFO queue, еҗҺиҝӣе…ҲеҮәпјҢ е®һйҷ…дёҠе°ұжҳҜе Ҷж Ҳ
class queue.LifoQueue(maxsize=0)
(3) еёҰдјҳе…Ҳзә§йҳҹеҲ—пјҢ дјҳе…Ҳзә§жңҖдҪҺentry value lowest е…ҲдәҶеҲ—
class queue.PriorityQueue(maxsize=0)
Multiprocessing.Queueзұ»зҡ„дё»иҰҒж–№жі•пјҡ
| method | Description |
|---|
| queue.qsize() | иҝ”еӣһйҳҹеҲ—й•ҝеәҰ |
| queue.full() | йҳҹеҲ—ж»ЎпјҢиҝ”еӣһ True, еҗҰеҲҷиҝ”еӣһFalse |
| queue.empty() | йҳҹеҲ—з©әпјҢиҝ”еӣһ True, еҗҰеҲҷиҝ”еӣһFalse |
| queue.put(item) | е°Ҷж•°жҚ®еҶҷе…ҘйҳҹеҲ— |
| queue.get() | е°Ҷж•°жҚ®жҠӣеҮәйҳҹеҲ— пјҢ |
| queue.put_nowait(item), queue.get_nowait() | ж— зӯүеҫ…еҶҷе…ҘжҲ–жҠӣеҮә |
иҜҙжҳҺпјҡ
put(), get() жҳҜйҳ»еЎһж–№жі•пјҢ иҖҢput_notwait(), get_nowait()жҳҜйқһйҳ»еЎһж–№жі•гҖӮ
Multiprocessing зҡ„Queueзұ»жІЎжңүжҸҗдҫӣTask_done, joinж–№жі•
QueueжЁЎеқ—зҡ„е…¶е®ғйҳҹеҲ—зұ»пјҡ
(1) SimpleQueue
з®ҖжҙҒзүҲзҡ„FIFOйҳҹеҲ—, йҖӮдәӢз®ҖеҚ•еңәжҷҜдҪҝз”Ё
(2) JoinableQueueеӯҗзұ»
Python 3.5 еҗҺж–°еўһзҡ„ Queueзҡ„еӯҗзұ»пјҢжӢҘжңү task_done(), join() ж–№жі•
producer – consumer еңәжҷҜпјҢдҪҝз”ЁQueueзҡ„зӨәдҫӢ
import multiprocessing
def producer(numbers, q):
for x in numbers:
if x % 2 == 0:
if q.full():
print("queue is full")
break
q.put(x)
print(f"put {x} in queue by producer")
return None
def consumer(q):
while not q.empty():
print(f"take data {q.get()} from queue by consumer")
return None
if __name__ == "__main__":
# и®ҫзҪ®1дёӘqueueеҜ№иұЎпјҢжңҖеӨ§й•ҝеәҰдёә5
qu = multiprocessing.Queue(maxsize=5,)
# еҲӣе»әproducerеӯҗиҝӣзЁӢпјҢжҠҠqueueеҒҡдёәе…¶дёӯ1дёӘеҸӮж•°дј з»ҷе®ғпјҢиҜҘиҝӣзЁӢиҙҹиҙЈеҶҷ
p5 = multiprocessing.Process(
name="producer-1",
target=producer,
args=([random.randint(1, 100) for i in range(0, 10)], qu)
)
p5.start()
p5.join()
#еҲӣе»әconsumerеӯҗиҝӣзЁӢпјҢжҠҠqueueеҒҡдёә1дёӘеҸӮж•°дј з»ҷе®ғпјҢиҜҘиҝӣзЁӢдёӯйҳҹеҲ—дёӯиҜ»
p6 = multiprocessing.Process(
name="consumer-1",
target=consumer,
args=(qu,)
)
p6.start()
p6.join()
print(qu.qsize())4гҖҒеҗҢжӯҘжңәеҲ¶йҖҡдҝЎ
(1) иҝӣзЁӢй—ҙеҗҢжӯҘй”Ғ – Lock
Multiprocessingд№ҹжҸҗдҫӣдәҶдёҺthreading зұ»дјјзҡ„еҗҢжӯҘй”ҒжңәеҲ¶пјҢзЎ®дҝқжҹҗдёӘж—¶еҲ»еҸӘжңү1дёӘеӯҗиҝӣзЁӢеҸҜд»Ҙи®ҝй—®жҹҗдёӘиө„жәҗжҲ–жү§иЎҢжҹҗйЎ№д»»еҠЎ, д»ҘйҒҝе…ҚеҗҢжҠўгҖӮ
дҫӢеҰӮпјҡеӨҡдёӘеӯҗиҝӣзЁӢеҗҢж—¶и®ҝй—®ж•°жҚ®еә“иЎЁж—¶пјҢеҰӮжһңжІЎжңүеҗҢжӯҘй”ҒпјҢз”ЁжҲ·Aдҝ®ж”№1жқЎж•°жҚ®еҗҺпјҢиҝҳжңӘжҸҗдәӨпјҢжӯӨж—¶пјҢз”ЁжҲ·Bд№ҹиҝӣиЎҢдәҶдҝ®ж”№пјҢеҸҜд»Ҙйў„и§ҒпјҢз”ЁжҲ·AжҸҗдәӨзҡ„е°ҶжҳҜBдёӘдҝ®ж”№зҡ„ж•°жҚ®гҖӮ
ж·»еҠ дәҶеҗҢжӯҘй”ҒпјҢеҸҜд»ҘзЎ®дҝқеҗҢж—¶еҸӘжңү1дёӘеӯҗиҝӣзЁӢиғҪеӨҹиҝӣиЎҢеҶҷе…Ҙж•°жҚ®еә“дёҺжҸҗдәӨж“ҚдҪңгҖӮ
еҰӮдёӢйқўзҡ„зӨәдҫӢпјҢеҗҢж—¶еҸӘжңү1дёӘиҝӣзЁӢеҸҜд»Ҙжү§иЎҢжү“еҚ°ж“ҚдҪңгҖӮ
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()(2) еӯҗиҝӣзЁӢй—ҙеҚҸи°ғжңәеҲ¶ – Event
Event жңәеҲ¶зҡ„е·ҘдҪңеҺҹзҗҶпјҡ
1дёӘevent еҜ№иұЎе®һдҫӢз®ЎзҗҶзқҖ1дёӘ flagж Үи®°, еҸҜд»Ҙз”Ёset()ж–№жі•е°Ҷе…¶зҪ®дёәtrue, з”Ёclear()ж–№жі•е°Ҷе…¶зҪ®дёәfalse, дҪҝз”Ёwait()е°Ҷйҳ»еЎһеҪ“еүҚеӯҗиҝӣзЁӢпјҢзӣҙиҮіflagиў«зҪ®дёәtrue.
иҝҷж ·з”ұ1дёӘиҝӣзЁӢйҖҡиҝҮevent flag е°ұеҸҜд»ҘжҺ§еҲ¶гҖҒеҚҸи°ғеҗ„еӯҗиҝӣзЁӢиҝҗиЎҢгҖӮ
Event objectзҡ„дҪҝз”Ёж–№жі•пјҡ
1пјүдё»еҮҪж•°пјҡ еҲӣе»ә1дёӘevent еҜ№иұЎпјҢ flag = multiprocessing.Event() , еҒҡдёәеҸӮж•°дј з»ҷеҗ„еӯҗиҝӣзЁӢ
2) еӯҗиҝӣзЁӢA: дёҚеҸ—eventеҪұе“Қ,йҖҡиҝҮevent жҺ§еҲ¶е…¶е®ғиҝӣзЁӢзҡ„иҝҗиЎҢ
o е…Ҳclear()пјҢе°Ҷevent зҪ®дёәFalse, еҚ з”ЁиҝҗиЎҢжқғ.
o е®ҢжҲҗе·ҘдҪңеҗҺпјҢз”Ёset()жҠҠflagзҪ®дёәTrueгҖӮ
3) еӯҗиҝӣзЁӢB, C: еҸ—event еҪұе“Қ
o и®ҫзҪ® wait() зҠ¶жҖҒпјҢжҡӮеҒңиҝҗиЎҢ
o зӣҙеҲ°flagйҮҚж–°еҸҳдёәTrueпјҢжҒўеӨҚиҝҗиЎҢ
дё»иҰҒж–№жі•пјҡ
set(), clear()и®ҫзҪ® True/False,
wait() дҪҝиҝӣзЁӢзӯүеҫ…пјҢзӣҙеҲ°flagиў«ж”№дёәtrue.
is_set()пјҢ Return True if and only if the internal flag is true.
йӘҢиҜҒиҝӣзЁӢй—ҙйҖҡдҝЎ – Event
import multiprocessing
import time
import random
def joo_a(q, ev):
print("subprocess joo_a start")
if not ev.is_set():
ev.wait()
q.put(random.randint(1, 100))
print("subprocess joo_a ended")
def joo_b(q, ev):
print("subprocess joo_b start")
ev.clear()
time.sleep(2)
q.put(random.randint(200, 300))
ev.set()
print("subprocess joo_b ended")
def main_event():
qu = multiprocessing.Queue()
ev = multiprocessing.Event()
sub_a = multiprocessing.Process(target=joo_a, args=(qu, ev))
sub_b = multiprocessing.Process(target=joo_b, args=(qu, ev,))
sub_a.start()
sub_b.start()
# ev.set()
sub_a.join()
sub_b.join()
while not qu.empty():
print(qu.get())
if __name__ == "__main__":
main_event()5гҖҒе…ұдә«еҶ…еӯҳж–№ејҸйҖҡдҝЎ
(1) е…ұдә«еҸҳйҮҸ
еӯҗиҝӣзЁӢд№Ӣй—ҙе…ұеӯҳеҶ…еӯҳеҸҳйҮҸпјҢиҰҒз”Ё multiprocessing.Value(), Array() жқҘе®ҡд№үеҸҳйҮҸгҖӮ е®һйҷ…дёҠжҳҜctypes зұ»еһӢпјҢз”ұmultiprocessing.sharedctypesжЁЎеқ—жҸҗдҫӣзӣёе…іеҠҹиғҪ
жіЁж„Ҹ дҪҝз”Ё share memory иҰҒиҖғиҷ‘еҗҢжҠўзӯүй—®йўҳпјҢйҮҠж”ҫзӯүй—®йўҳпјҢйңҖиҰҒжүӢе·Ҙе®һзҺ°гҖӮеӣ жӯӨеңЁдҪҝз”Ёе…ұдә«еҸҳйҮҸж—¶пјҢе»әи®®дҪҝз”ЁManagerз®ЎзЁӢжқҘз®ЎзҗҶиҝҷдәӣе…ұдә«еҸҳйҮҸгҖӮ
def func(num):
num.value=10.78 #еӯҗиҝӣзЁӢж”№еҸҳж•°еҖјзҡ„еҖјпјҢдё»иҝӣзЁӢи·ҹзқҖж”№еҸҳ
if __name__=="__main__":
num = multiprocessing.Value("d", 10.0)
# dиЎЁзӨәж•°еҖј,дё»иҝӣзЁӢдёҺеӯҗиҝӣзЁӢеҸҜе…ұдә«иҝҷдёӘеҸҳйҮҸгҖӮ
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
print(num.value)иҝӣзЁӢд№Ӣй—ҙе…ұдә«ж•°жҚ®(ж•°з»„еһӢ)пјҡ
import multiprocessing
def func(num):
num[2]=9999 #еӯҗиҝӣзЁӢж”№еҸҳж•°з»„пјҢдё»иҝӣзЁӢи·ҹзқҖж”№еҸҳ
if __name__=="__main__":
num=multiprocessing.Array("i",[1,2,3,4,5])
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
print(num[:])(2) е…ұдә«еҶ…еӯҳ Shared_memory
еҰӮжһңиҝӣзЁӢй—ҙйңҖиҰҒе…ұдә«еҜ№иұЎж•°жҚ®пјҢжҲ–е…ұдә«еҶ…е®№пјҢж•°жҚ®иҫғеӨ§пјҢmultiprocessing жҸҗдҫӣдәҶSharedMemoryзұ»жқҘе®һзҺ°иҝӣзЁӢй—ҙе®һж—¶йҖҡдҝЎпјҢдёҚйңҖиҰҒйҖҡиҝҮеҸ‘ж¶ҲжҒҜпјҢиҜ»еҶҷзЈҒзӣҳж–Ү件жқҘе®һзҺ°пјҢйҖҹеәҰжӣҙеҝ«гҖӮ
жіЁж„ҸпјҡзӣҙжҺҘдҪҝз”ЁSharedMemory еӯҳеңЁзқҖеҗҢжҠўгҖҒжі„йңІйҡҗжӮЈпјҢеә”йҖҡиҝҮSharedMemory Manager з®ЎзЁӢзұ»жқҘдҪҝз”Ё, д»ҘзЎ®дҝқеҶ…еӯҳе®үе…ЁгҖӮ
еҲӣе»әе…ұдә«еҶ…еӯҳеҢәпјҡ
multiprocessing.shared_memory.SharedMemory(name=none, create=False, size=0)
ж–№жі•пјҡ
зҲ¶иҝӣзЁӢеҲӣе»әshared_memory еҗҺпјҢеӯҗиҝӣзЁӢеҸҜд»ҘдҪҝз”Ёе®ғпјҢеҪ“дёҚеҶҚйңҖиҰҒеҗҺпјҢдҪҝз”Ёclose(), еҲ йҷӨдҪҝз”Ёunlink()ж–№жі•
зӣёе…іеұһжҖ§пјҡ
иҺ·еҸ–еҶ…еӯҳеҢәеҶ…е®№пјҡ shm.buf
иҺ·еҸ–еҶ…еӯҳеҢәеҗҚз§°пјҡ shm.name
иҺ·еҸ–еҶ…еӯҳеҢәеӯ—иҠӮж•°: shm.size
зӨәдҫӢпјҡ
>>> from multiprocessing import shared_memory
>>> shm_a = shared_memory.SharedMemory(create=True, size=10)
>>> type(shm_a.buf)
<class 'memoryview'>
>>> buffer = shm_a.buf
>>> len(buffer)
10
>>> buffer[:4] = bytearray([22, 33, 44, 55]) # Modify multiple at once
>>> buffer[4] = 100 # Modify single byte at a time
>>> # Attach to an existing shared memory block
>>> shm_b = shared_memory.SharedMemory(shm_a.name)
>>> import array
>>> array.array('b', shm_b.buf[:5]) # Copy the data into a new array.array
array('b', [22, 33, 44, 55, 100])
>>> shm_b.buf[:5] = b'howdy' # Modify via shm_b using bytes
>>> bytes(shm_a.buf[:5]) # Access via shm_a
b'howdy'
>>> shm_b.close() # Close each SharedMemory instance
>>> shm_a.close()
>>> shm_a.unlink() # Call unlink only once to release the shared memory3пјү ShareableList е…ұдә«еҲ—иЎЁ
sharedMemoryзұ»иҝҳжҸҗдҫӣдәҶ1дёӘе…ұдә«еҲ—иЎЁзұ»еһӢпјҢиҝҷж ·е°ұжӣҙж–№дҫҝдәҶпјҢиҝӣзЁӢй—ҙеҸҜд»ҘзӣҙжҺҘе…ұдә«pythonејәеӨ§зҡ„еҲ—иЎЁ
жһ„е»әж–№жі•пјҡ
multiprocessing.shared_memory.ShareableList(sequence=None, *, name=None)
from multiprocessing import shared_memory
>>> a = shared_memory.ShareableList(['howdy', b'HoWdY', -273.154, 100, None, True, 42])
>>> [ type(entry) for entry in a ]
[<class 'str'>, <class 'bytes'>, <class 'float'>, <class 'int'>, <class 'NoneType'>, <class 'bool'>, <class 'int'>]
>>> a[2]
-273.154
>>> a[2] = -78.5
>>> a[2]
-78.5
>>> a[2] = 'dry ice' # Changing data types is supported as well
>>> a[2]
'dry ice'
>>> a[2] = 'larger than previously allocated storage space'
Traceback (most recent call last):
...
ValueError: exceeds available storage for existing str
>>> a[2]
'dry ice'
>>> len(a)
7
>>> a.index(42)
6
>>> a.count(b'howdy')
0
>>> a.count(b'HoWdY')
1
>>> a.shm.close()
>>> a.shm.unlink()
>>> del a # Use of a ShareableList after call to unlink() is unsupported
b = shared_memory.ShareableList(range(5)) # In a first process
>>> c = shared_memory.ShareableList(name=b.shm.name) # In a second process
>>> c
ShareableList([0, 1, 2, 3, 4], name='...')
>>> c[-1] = -999
>>> b[-1]
-999
>>> b.shm.close()
>>> c.shm.close()
>>> c.shm.unlink()
6гҖҒе…ұдә«еҶ…еӯҳз®ЎзҗҶеҷЁManager
Multiprocessing жҸҗдҫӣдәҶ Manager еҶ…еӯҳз®ЎзҗҶеҷЁзұ»пјҢеҪ“и°ғз”Ё1дёӘManagerе®һдҫӢеҜ№иұЎзҡ„start()ж–№жі•ж—¶пјҢдјҡеҲӣе»ә1дёӘmanagerиҝӣзЁӢпјҢе…¶е”ҜдёҖзӣ®зҡ„е°ұжҳҜз®ЎзҗҶе…ұдә«еҶ…еӯҳ, йҒҝе…ҚеҮәзҺ°иҝӣзЁӢй—ҙе…ұдә«ж•°жҚ®дёҚеҗҢжӯҘпјҢеҶ…еӯҳжі„йңІзӯүзҺ°иұЎгҖӮ
е…¶еҺҹзҗҶеҰӮдёӢпјҡ
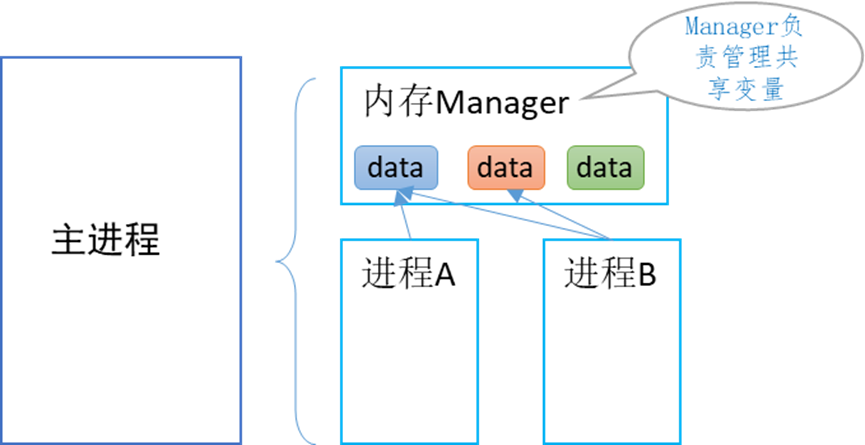
Managerз®ЎзҗҶеҷЁзӣёеҪ“дәҺжҸҗдҫӣдәҶ1дёӘе…ұдә«еҶ…еӯҳзҡ„жңҚеҠЎпјҢдёҚд»…еҸҜд»Ҙиў«дё»иҝӣзЁӢеҲӣе»әзҡ„еӨҡдёӘеӯҗиҝӣзЁӢдҪҝз”ЁпјҢиҝҳеҸҜд»Ҙиў«е…¶е®ғиҝӣзЁӢи®ҝй—®пјҢз”ҡиҮіи·ЁзҪ‘з»ңи®ҝй—®гҖӮжң¬ж–Үд»…иҒҡз„ҰдәҺз”ұеҚ•дёҖдё»иҝӣзЁӢеҲӣе»әзҡ„еҗ„иҝӣзЁӢд№Ӣй—ҙзҡ„йҖҡдҝЎгҖӮ
1пјү Managerзҡ„дё»иҰҒж•°жҚ®з»“жһ„
зӣёе…ізұ»пјҡmultiprocessing.Manager
еӯҗзұ»жңүпјҡ
ж”ҜжҢҒе…ұдә«еҸҳйҮҸзұ»еһӢпјҡ
pythonеҹәжң¬зұ»еһӢ int, str, list, tuple, list
иҝӣзЁӢйҖҡдҝЎеҜ№иұЎпјҡ Queue, Lock, Event,
Condition, Semaphore, Barrier ctypesзұ»еһӢ: Value, Array
2пјү дҪҝз”ЁжӯҘйӘӨ
1пјүеҲӣе»әз®ЎзҗҶеҷЁеҜ№иұЎ
snm = Manager()
snm = SharedMemoryManager()
2пјүеҲӣе»әе…ұдә«еҶ…еӯҳеҸҳйҮҸ
ж–°е»әlist, dict
sl = snm.list(), snm.dict()
ж–°е»ә1еқ—bytesе…ұдә«еҶ…еӯҳеҸҳйҮҸпјҢйңҖиҰҒжҢҮе®ҡеӨ§е°Ҹ
sx = snm.SharedMemory(size)
ж–°е»ә1дёӘе…ұдә«еҲ—иЎЁеҸҳйҮҸпјҢеҸҜз”ЁеҲ—иЎЁжқҘеҲқе§ӢеҢ–
sl = snm.ShareableList(sequence) еҰӮ
sl = smm.ShareableList([вҖҳhowdy', b'HoWdY', -273.154, 100, True])
ж–°е»ә1дёӘqueue, дҪҝз”Ёmultiprocessing зҡ„Queueзұ»еһӢ
snm = Manager()
q = snm.Queue()
зӨәдҫӢ пјҡ
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
е°Ҷжү“еҚ°
{0.25: None, 1: '1', '2': 2}
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
3пјү й”ҖжҜҒе…ұдә«еҶ…еӯҳеҸҳйҮҸ
ж–№жі•дёҖпјҡ
и°ғз”Ёsnm.shutdown()ж–№жі•пјҢдјҡиҮӘеҠЁи°ғз”ЁжҜҸдёӘеҶ…еӯҳеқ—зҡ„unlink()ж–№жі•йҮҠж”ҫеҶ…еӯҳгҖӮжҲ–иҖ… snm.close()
ж–№жі•дәҢпјҡ
дҪҝз”ЁwithиҜӯеҸҘпјҢз»“жқҹеҗҺдјҡиҮӘеҠЁйҮҠж”ҫжүҖжңүmanagerеҸҳйҮҸ
>>> with SharedMemoryManager() as smm:
... sl = smm.ShareableList(range(2000))
... # Divide the work among two processes, storing partial results in sl
... p1 = Process(target=do_work, args=(sl, 0, 1000))
... p2 = Process(target=do_work, args=(sl, 1000, 2000))
... p1.start()
... p2.start() # A multiprocessing.Pool might be more efficient
... p1.join()
... p2.join() # Wait for all work to complete in both processes
... total_result = sum(sl) # Consolidate the partial results now in sl
4пјү еҗ‘з®ЎзҗҶеҷЁжіЁеҶҢиҮӘе®ҡд№үзұ»еһӢ
managersзҡ„еӯҗзұ»BaseManagerжҸҗдҫӣregister()ж–№жі•пјҢж”ҜжҢҒжіЁеҶҢиҮӘе®ҡд№үж•°жҚ®зұ»еһӢгҖӮеҰӮдёӢдҫӢпјҢжіЁеҶҢ1дёӘиҮӘе®ҡд№үMathsClassзұ»пјҢ并з”ҹжҲҗе®һдҫӢгҖӮ
from multiprocessing.managers import BaseManager
class MathsClass:
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
with MyManager() as manager:
maths = manager.Maths()
print(maths.add(4, 3)) # prints 7
print(maths.mul(7, 8))еҲ°жӯӨпјҢе…ідәҺвҖңPython multiprocessingиҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸеҰӮдҪ•е®һзҺ°вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





