这篇“Redis数据结构类型实例代码分析”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“Redis数据结构类型实例代码分析”文章吧。
当set集合存储的是整数时,encoding为intset类型(小整数集合)
typedef struct intset {
int32 encoding;
int32 length;
int contents[];
}| 字段 | 描述 | 说明 |
|---|---|---|
| encoding | 决定整数位宽是16位、32位还是64位 | 枚举表示 |
| length | 元素个数 | |
| contents | 整数数组,存储元素值 |
intset按照从小到大的顺序保存元素。存储元素时,根据整数大小决定是否要将encoding升级,找到要插入元素的位置,如果不是最后一位,会将所在位置之后的元素后移一位,最后插入元素。如果插入的元素不为整数,存储形式将变成hash结构。
当hash与zset满足如下条件条件时,编码类型为ziplist(压缩列表),具体可在配置文件中查看。
hash-max-ziplist-entries 512 # 当hash元素个数小于512时
hash-max-ziplist-value 64 # 当hash键或值长度小于64时
zset-max-ziplist-entries 128 # 当zset元素个数小于128时
zset-max-ziplist-value 64 # 当zset值小于64时typedef struct ziplist {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
typedef struct entry {
int<var> prevlen;
int<var> encoding;
byte[] content;
}| 字段 | 描述 | 说明 |
|---|---|---|
| zlbytes | ziplist所占字节数 | |
| zltail_offset | 最后一个元素距离压缩列表起始位置的偏移量 | 用于快速定位到最后一个节点,然后倒序遍历 |
| zllength | 元素个数 | |
| entries | 压缩元素 | |
| zlend | 标志压缩列表的结束 | 恒为FF |
| 字段 | 描述 | 说明 |
|---|---|---|
| prevlen | 前一个entry的字节长度 | 第一个entry恒为0,字节长度动态变化,当字符串长度小于254时,用一个字节,否则用五个字节 |
| encoding | 编码类型 | 编码类型根据元素内容动态变化,极为复杂,本篇不作详细描述,具体可搜索ziplist编码类型 |
| content | 元素内容,可选 |
下图是一个ziplist的demo

第1-4字节,zlbytes为25,说明该压缩列表共占用25个字节
第5-8字节,zltail_offset为22,说明最后一个元素从22开始
第9-10字节,zllength为3,说明共有3个元素
第11-16字节,第一个entry: 其中prevlen=0,因为它前面没有数据项;encoding=4,表示后面4byte按照字符串存储,数据的值为name
第17-21字节,第二个entry: 其中prevlen=6,表示前一个entry共占用6byte;encoding=3,表示后面3byte按照字符串存储,数据的值为why
第22-24字节,第三个entry: 其中prevlen=5,表示前一个entry共占用5byte;encoding=0xFE,表示后面1byte存储整数,数据的值为14
第25字节,zlend为FF,标志压缩列表的结束
当用ziplist存储hash结构时,将key与value分别当作一个entry存储。
可见压缩列表存储非常的紧凑,当某一个entry长度变为254时,下一个entry的prevlen将从1个字节扩展到5个字节,这就是级联更新
quicklist(快速列表)用于存储list集合,它是ziplist与linkedlist的混合体,linkedlist与双向列表结构类似。
quicklist内部默认单个ziplist长度为8K,超过这个长度,就会另起一个node,可在配置文件中配置。
# -2表示8k,枚举类型可在配置文件中查看
list-max-ziplist-size -2quicklist默认的压缩深度为0,也就是不压缩。如果压缩深度为1,那么就是首尾不压缩,如果压缩深度为2,那么就是首2个、尾2个不压缩,可在配置文件中配置。
list-compress-depth 0
zset使用dict存储value与score的映射,另一方面还需要按照score提供排序功能,于是就有了skiplist(跳跃列表)
先看skiplist的一个demo
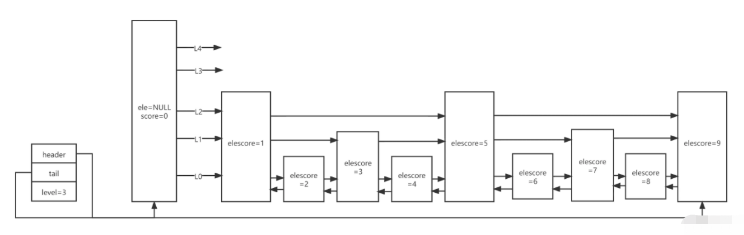
typedef struct zsl {
zslnode* header;
zslnode* tail;
int maxLevel;
}typedef struct zslnode {
sds value;
double score;
zslforward*[] forwards;
zslnode* backward;
}typedef struct zslforward {
zslnode* item;
int span;
}| 字段 | 描述 | 说明 |
|---|---|---|
| header | 指向跳跃列表的头指针 | value固定为NULL,score固定为0,backward为null |
| tail | 指向跳跃列表的尾指针 | |
| maxLevel | 当前跳跃表最大层数 | 最大为64 |
| value | 用于存储字符串类型的数据 | |
| score | 用于存储分值 | |
| backward | 回退节点 | 图中的←箭头 |
| forwards | 前进节点 | 图中的→箭头,每一层对应一个 |
| span | 跨度,存储一个节点跳到下一个节点中间跳过了多少节点 | 如score1指向score5,则span值为4,这是排名的实现原理 |
最小分值的backward固定null,对于每一个新插入的节点,会调用一个随机算法,来给它分配一个合理的层数
level1的概率为1-0.25=0.75,实际为100%,因为跳跃列表的最小层数为1
level2的概率为0.75*0.25=0.1875level3的概率为0.1875*0.25=0.0468 ......
leveln的概率为(1-0.25)*Math.pow(0.25,n-1)
Redis作为单线程内存服务,在响应、数据结构上作出了很多的优化,值得我们学习
| 对象类型 | 编码类型 |
|---|---|
| string | int、raw、embstr |
| list | quicklist |
| hash | dict、ziplist |
| set | intset、dict |
| zset | ziplist、skiplist+dict |
HyperLogLog的原理为伯努利试验,即丢硬币,根据连续出现反面的次数X,推算出一共丢了2的X次方次硬币,当X很大时,推算出来的总数与实际总数误差就很接近了。具体可查询其他文章。
element经过hash算法之后是一个64位的固定值
低14位为桶
查找高50位第一个为1的位数,如果大于当前桶的位数,就将其设置为当前桶的位数
假设hash值是 :{此处省略45位}01100 00000000000101
低14位的二进制转为10进制,值为5(regnum),即我们把数据放在第5个桶
高50位第一个1的位置是3,即count值为3
registers[5]取出历史值oldcount
如果count > oldcount,则更新 registers[5] = count
如果count <= oldcount,则不做任何处理
HyperLogLog用了16384个桶,每个桶占用6bit,因此说一个HyperLogLog所占用内存是12K。
调和平均数:
假设我的工资为10_000,马云的工资为1_000_000,那我和马云的平均工资为505_000,我肯定是不认同的。。。
如果使用调和平均数,则为2/(1/10_000+1/1_000_000)=19_801
同理,桶位数的平均数为:n/(1/桶1位数+1/桶2位数+...+1/桶n位数)
桶的平均个数为:Math.pow(2,桶位数的平均数)
总数量:const*桶总数n*桶的平均个数,其中constant为不定值,与桶个数有关,假设m为桶个数,取对数
p=log2m
switch (p) {
case 4:
constant = 0.673 * m * m;
case 5:
constant = 0.697 * m * m;
case 6:
constant = 0.709 * m * m;
default:
constant = (0.7213 / (1 + 1.079 / m)) * m * m;
}以上就是关于“Redis数据结构类型实例代码分析”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



