PythonдёӯhttptoolsжЁЎеқ—еҰӮдҪ•дҪҝз”Ё
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңPythonдёӯhttptoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁPythonдёӯhttptoolsжЁЎеқ—еҰӮдҪ•дҪҝз”Ёй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқPythonдёӯhttptoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
еҰӮжһңдҪ з”ЁиҝҮ FastAPI зҡ„иҜқпјҢйӮЈд№ҲдҪ дёҖе®ҡзҹҘйҒ“ uvicornпјҢе®ғжҳҜдёҖдёӘеҹәдәҺ uvloop е’Ң httptools е®һзҺ°зҡ„й«ҳжҖ§иғҪ ASGI жңҚеҠЎеҷЁгҖӮ
е…¶дёӯ uvloop йҮҮз”Ё Cython зј–еҶҷпјҢз”ЁдәҺжӣҝжҚў asyncio дёӯзҡ„дәӢ件еҫӘзҺҜпјҢеҸҜд»Ҙи®© asyncio йҖҹеәҰеўһеҠ 2 еҲ° 4 еҖҚгҖӮиҖҢ httptools жҳҜеҹәдәҺ C иҜӯиЁҖе®һзҺ°зҡ„ HTTP и§ЈжһҗеҷЁпјҢз”ЁжқҘи§Јжһҗ HTTP иҜ·жұӮзҡ„гҖӮ
httptools жҳҜдёҖдёӘ HTTP и§ЈжһҗеҷЁпјҢе®ғйҰ–е…ҲжҸҗдҫӣдәҶдёҖдёӘ parse_url еҮҪж•°пјҢз”ЁжқҘи§Јжһҗ URLгҖӮ
import httptools
# 第дёҖдёӘеҸӮж•°еҝ…йЎ»жҳҜ bytes еҜ№иұЎ
url = httptools.parse_url(
b"http://www.baidu.com"
)
# иҝ”еӣһдёҖдёӘ URL еҜ№иұЎ
print(url.__class__)
"""
<class 'httptools.parser.parser.URL'>
"""
йӮЈд№ҲиҝҷдёӘ URL еҜ№иұЎжңүе“ӘдәӣеұһжҖ§е‘ўпјҹ

йҖҡиҝҮжәҗз ҒеҸҜзҹҘпјҢжҖ»е…ұжңүдёғдёӘеұһжҖ§пјҢжҲ‘们жқҘжөӢиҜ•дёҖдёӢгҖӮ
import httptools
# 第дёҖдёӘеҸӮж•°жҳҜ bytes еҜ№иұЎ
url = b"http://satori:123456@www.baidu.com:80/s?wd=koishi#flag"
url_obj = httptools.parse_url(url)
print("еҚҸи®®:", url_obj.schema)
print("IP:", url_obj.host)
print("з«ҜеҸЈ:", url_obj.port)
print("и·Ҝеҫ„:", url_obj.path)
print("жҹҘиҜўеҸӮж•°:", url_obj.query)
print("й”ҡзӮ№:", url_obj.fragment)
print("з”ЁжҲ·дҝЎжҒҜ:", url_obj.userinfo)
"""
еҚҸи®®: b'http'
IP: b'www.baidu.com'
з«ҜеҸЈ: 80
и·Ҝеҫ„: b'/s'
жҹҘиҜўеҸӮж•°: b'wd=koishi'
й”ҡзӮ№: b'flag'
з”ЁжҲ·дҝЎжҒҜ: b'satori:123456'
"""жҜ”иҫғз®ҖеҚ•пјҢеҰӮжһңеҸӮж•°дёҚз¬ҰеҗҲ URL зҡ„ж ҮеҮҶж јејҸпјҢйӮЈд№ҲдјҡжҠӣеҮә HttpParserInvalidURLError й”ҷиҜҜгҖӮ
然еҗҺжҳҜ HTTP иҜ·жұӮжҠҘж–Үе’Ңе“Қеә”жҠҘж–Үзҡ„и§ЈжһҗпјҢеӣ дёәжҠҘж–ҮеҸӘжҳҜдёҖеқЁеӯ—иҠӮжөҒпјҢйңҖиҰҒе°Ҷе®ғи§ЈжһҗжҲҗжҹҗдёӘ Request еҜ№иұЎжҲ– Response еҜ№иұЎпјҢиҖҢ httptools е°ұжҳҜе№Іиҝҷ件дәӢжғ…зҡ„гҖӮ
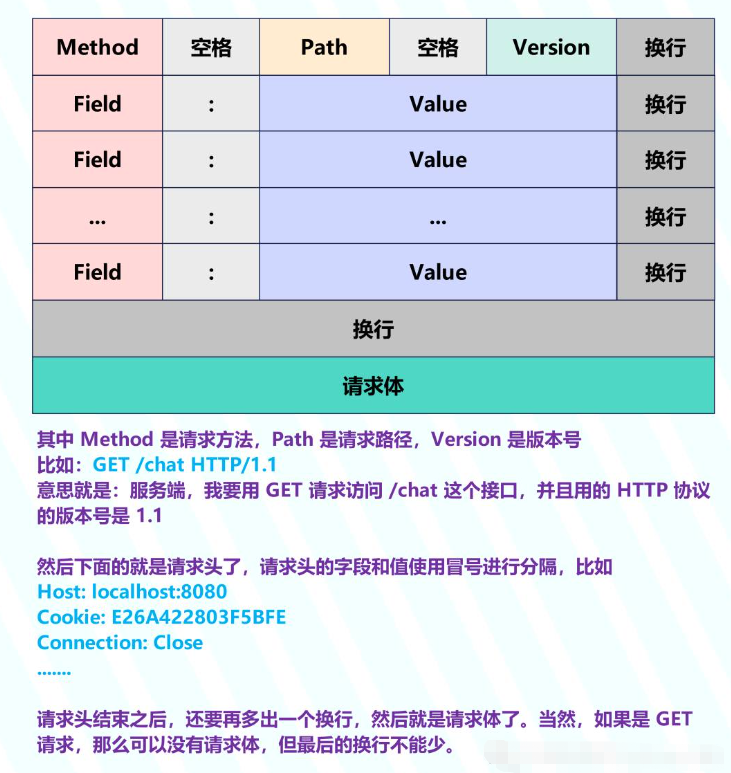
йҰ–е…ҲжқҘзңӢдёҖдёӢжҠҘж–Үж јејҸпјҢиҜ·жұӮжҠҘж–ҮеҰӮдёӢпјҡ
жҺҘдёӢжқҘжҳҜе“Қеә”жҠҘж–Үпјҡ
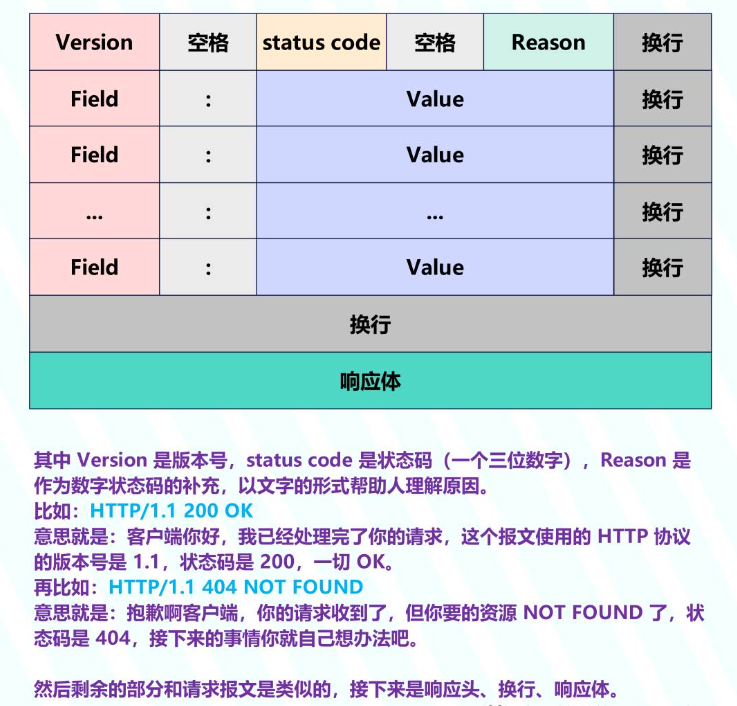
жүҖд»Ҙж— и®әжҳҜиҜ·жұӮжҠҘж–ҮиҝҳжҳҜе“Қеә”жҠҘж–ҮпјҢйғҪз”ұ иө·е§ӢиЎҢ + иҜ·жұӮеӨҙ/е“Қеә”еӨҙ + иҜ·жұӮдҪ“/е“Қеә”дҪ“ з»„жҲҗгҖӮиҖҢжҲ‘们еңЁжӢҝеҲ°еҺҹе§Ӣзҡ„жҠҘж–Үд№ӢеҗҺпјҢд№ҹеҸҜд»ҘеҫҲж–№дҫҝең°иҝӣиЎҢи§ЈжһҗпјҢд»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәжңҖеҗҺдёҖдёӘ Header еӯ—ж®өе’Ңе“Қеә”дҪ“д№Ӣй—ҙжңүдёӨдёӘжҚўиЎҢпјҢиҖҢжҚўиЎҢз”Ё \r\n иЎЁзӨәгҖӮеӣ жӯӨжҲ‘们еҸӘиҰҒжҢүз…§ "\r\n\r\n" иҝӣиЎҢ split еҚіеҸҜпјҢдјҡеҫ—еҲ°дёҖдёӘж•°з»„пјҢж•°з»„зҡ„第дәҢдёӘе…ғзҙ е°ұжҳҜиҜ·жұӮдҪ“/е“Қеә”дҪ“пјҢ第дёҖдёӘе…ғзҙ е°ұжҳҜиө·е§ӢиЎҢ + иҜ·жұӮеӨҙ/е“Қеә”еӨҙгҖӮ
然еҗҺеҜ№ж•°з»„зҡ„第дёҖдёӘе…ғзҙ жҢүз…§ "\r\n" еҶҚиҝӣиЎҢ splitпјҢеҸҲеҸҜд»Ҙеҫ—еҲ°дёҖдёӘж•°з»„пјҢиҜҘж•°з»„зҡ„第дёҖдёӘе…ғзҙ е°ұжҳҜиө·е§ӢиЎҢпјҢеү©дҪҷзҡ„е…ғзҙ е°ұжҳҜиҜ·жұӮеӨҙ/е“Қеә”еӨҙгҖӮ
жүҖд»ҘжҲ‘们еңЁжӢҝеҲ°жҠҘж–Үд№ӢеҗҺпјҢе®Ңе…ЁеҸҜд»ҘиҮӘе·ұжүӢеҠЁи§ЈжһҗпјҢдҪҶ httptools жҳҜз”Ё C е®һзҺ°зҡ„пјҢжүҖд»ҘйҖҹеәҰдјҡеҝ«дёҖдәӣпјҢдҪҶе№Ізҡ„дәӢжғ…жҳҜдёҖж ·зҡ„гҖӮдёӢйқўжқҘзңӢзңӢ httptools еҰӮдҪ•и§ЈжһҗиҜ·жұӮжҠҘж–Үпјҡ
from pprint import pprint
import httptools
# иҜ·жұӮжҠҘж–Ү
request_payload = b"""POST /index?a=1 HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Content-Length: 26
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Accept: text/html
Accept-Encoding: gzip, deflate, sdch
Cookie: _octo=GH1.1.1989111283.1493917476; logged_in=yes
{"name":"satori","age":17}"""
class Request:
"""
е°ҶиҜ·жұӮжҠҘж–Үзҡ„и§Јжһҗз»“жһңе°ҒиЈ…жҲҗ Request еҜ№иұЎ
"""
def __init__(self):
self.headers = {}
self.body = b""
self.path = None
def on_url(self, path: bytes):
self.path = path
def on_header(self, name: bytes, value: bytes):
self.headers[name] = value
def on_body(self, body: bytes):
self.body = body
# е®һдҫӢеҢ– Request еҜ№иұЎ
request = Request()
# е°Ҷ request дҪңдёәеҸӮж•°дј еҲ° HttpRequestParser дёӯ
parser = httptools.HttpRequestParser(request)
# дј е…ҘиҜ·жұӮжҠҘж–ҮпјҢиҝӣиЎҢи§Јжһҗ
parser.feed_data(request_payload)
# иҺ·еҸ– HTTP зүҲжң¬
print(parser.get_http_version())
"""
1.1
"""
# жҳҜеҗҰжҳҜй•ҝй“ҫжҺҘпјҲConnection жҢҮе®ҡдёә keep-aliveпјү
print(parser.should_keep_alive())
"""
True
"""
# иҺ·еҸ–иҜ·жұӮж–№жі•
print(parser.get_method())
"""
b'POST'
"""
# д»ҘдёҠеҮ дёӘйғҪжҳҜ HttpRequestParser еҜ№иұЎзҡ„ж–№жі•
# иҺ·еҸ–и·Ҝеҫ„
print(request.path)
"""
b'/index?a=1'
"""
# иҺ·еҸ–иҜ·жұӮеӨҙ
pprint(request.headers)
"""
{b'Accept': b'text/html',
b'Accept-Encoding': b'gzip, deflate, sdch',
b'Cache-Control': b'max-age=0',
b'Connection': b'keep-alive',
b'Content-Length': b'26',
b'Cookie': b'_octo=GH1.1.1989111283.1493917476; logged_in=yes',
b'Host': b'localhost:8080',
b'Upgrade-Insecure-Requests': b'1'}
"""
# Cookie д№ҹжҳҜиҜ·жұӮеӨҙзҡ„дёҖйғЁеҲҶпјҢдҪҶеңЁи§Јжһҗзҡ„ж—¶еҖҷдјҡеҚ•зӢ¬жӢҝеҮәжқҘ
# еҶҚи§ЈжһҗжҲҗдёҖдёӘеӯ—е…ёпјҢ然еҗҺйҖҡиҝҮ request.cookies иҺ·еҸ–
# иҺ·еҸ–иҜ·жұӮдҪ“
print(request.body)
"""
b'{"name":"satori","age":17}'
"""д»ҘдёҠе°ұжҳҜиҜ·жұӮжҠҘж–Үзҡ„и§ЈжһҗпјҢеҶҚжқҘзңӢзңӢе“Қеә”жҠҘж–ҮгҖӮ
from pprint import pprint
import httptools
# е“Қеә”жҠҘж–Ү
response_payload = b"""HTTP/1.1 200 OK
Server: TornadoServer/6.1
Content-Type: text/html; charset=UTF-8
Date: Sun, 22 May 2022 17:54:11 GMT
Content-Length: 21
name: satori, age: 17"""
class Response:
"""
е°Ҷе“Қеә”жҠҘж–Үзҡ„и§Јжһҗз»“жһңе°ҒиЈ…жҲҗ Response еҜ№иұЎ
"""
def __init__(self):
self.headers = {}
self.body = b""
self.status = b""
def on_header(self, name: bytes, value: bytes):
self.headers[name] = value
def on_body(self, body: bytes):
self.body = body
def on_status(self, status: bytes):
self.status = status
# е®һдҫӢеҢ– Response еҜ№иұЎ
response = Response()
# е°Ҷ response дҪңдёәеҸӮж•°дј еҲ° HttpResponseParser дёӯ
parser = httptools.HttpResponseParser(response)
# дј е…Ҙе“Қеә”жҠҘж–ҮпјҢиҝӣиЎҢи§Јжһҗ
parser.feed_data(response_payload)
# иҺ·еҸ– HTTP зүҲжң¬
print(parser.get_http_version())
"""
1.1
"""
# жҳҜеҗҰжҳҜй•ҝй“ҫжҺҘпјҲдёҚжҢҮе®ҡ ConnectionпјҢй»ҳи®Өдёәй•ҝиҝһжҺҘпјү
print(parser.should_keep_alive())
"""
True
"""
# иҺ·еҸ–зҠ¶жҖҒз Ғ
print(parser.get_status_code())
"""
b'OK'
"""
# иҺ·еҸ–зҠ¶жҖҒз ҒеҜ№еә”зҡ„жҸҸиҝ°
print(response.status)
"""
b'OK'
"""
# иҺ·еҸ–е“Қеә”еӨҙ
pprint(response.headers)
"""
{b'Content-Length': b'21',
b'Content-Type': b'text/html; charset=UTF-8',
b'Date': b'Sun, 22 May 2022 17:54:11 GMT',
b'Server': b'TornadoServer/6.1'}
"""
# иҺ·еҸ–е“Қеә”дҪ“
print(response.body)
"""
b'name: satori, age: 17'
"""д»ҘдёҠе°ұжҳҜиҜ·жұӮжҠҘж–Үе’Ңе“Қеә”жҠҘж–Үзҡ„и§ЈжһҗпјҢдҪҶеҰӮжһңдҪ дёҚжҳҜжүӢеҠЁеҸ‘йҖҒ TCP иҜ·жұӮзҡ„иҜқпјҢйӮЈд№ҲиҜҘжЁЎеқ—еҹәжң¬з”ЁдёҚеҲ°гҖӮеӣ дёәеҜ№дәҺд»»дҪ•дёҖдёӘжҲҗзҶҹзҡ„жЁЎеқ—иҖҢиЁҖпјҢйғҪе…·еӨҮдәҶжҠҘж–Үи§ЈжһҗеҠҹиғҪгҖӮеғҸ requests, httpx, aiohttp зӯүзӯүпјҢд»ҘеҸҠдёҖдәӣ web жЎҶжһ¶пјҢе®ғ们еңЁжӢҝеҲ°жҠҘж–Үд№ӢеҗҺдјҡиҮӘеҠЁи§ЈжһҗжҲҗжҹҗдёӘеҜ№иұЎпјҢжҲ‘们зӣҙжҺҘйҖҡиҝҮжҢҮе®ҡзҡ„еұһжҖ§иҺ·еҸ–еҚіеҸҜгҖӮ
иҖҢ httptools дҫҝжҳҜ uvicorn зҡ„жҠҘж–Үи§ЈжһҗеҷЁпјҢжҲ‘们еңЁдҪҝз”Ё uvicorn зҡ„ж—¶еҖҷпјҢuvicorn еҶ…йғЁд№ҹдјҡиҮӘеҠЁйҖҡиҝҮ httptools е°ҶжҠҘж–Үи§ЈжһҗеҘҪпјҢиҖҢдёҚйңҖиҰҒжҲ‘们жүӢеҠЁи§ЈжһҗгҖӮ
еӣ жӯӨиҝҷйҮҢд»Ӣз»Қзҡ„ httptools дәҶи§ЈдёҖдёӢеҚіеҸҜпјҢжҲ‘们еҸӘйңҖиҰҒзҹҘйҒ“е®ғжҳҜеҹәдәҺ C е®һзҺ°зҡ„пјҢжҖ§иғҪйқһеёёй«ҳе°ұиЎҢгҖӮдҪҶжҲ‘们дёҚдјҡжүӢеҠЁдҪҝз”Ёе®ғпјҢиҖҢжҳҜеңЁдҪҝз”ЁжҹҗдёӘжЎҶжһ¶пјҲuvicornпјүзҡ„ж—¶еҖҷпјҢз”ұжЎҶжһ¶иҮӘеҠЁеё®жҲ‘们е°ҶжҠҘж–Үи§ЈжһҗеҘҪгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңPythonдёӯhttptoolsжЁЎеқ—еҰӮдҪ•дҪҝз”ЁвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





